 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024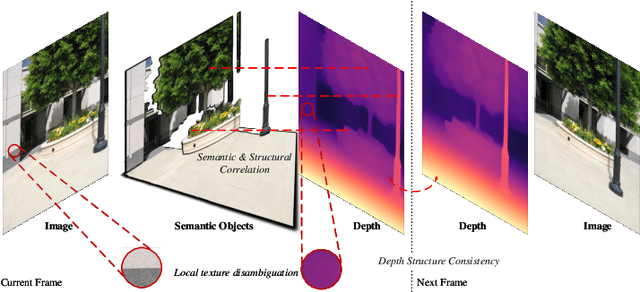
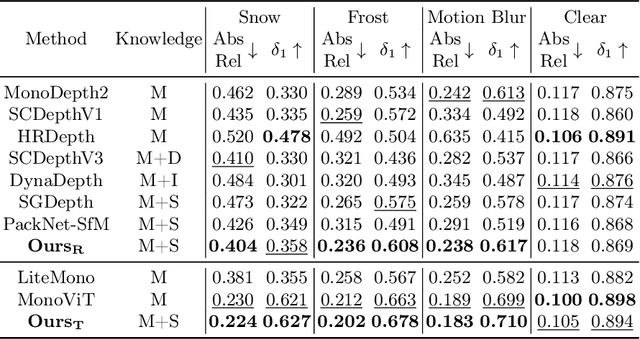
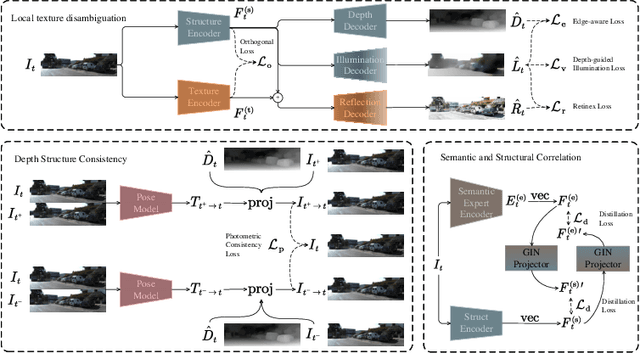
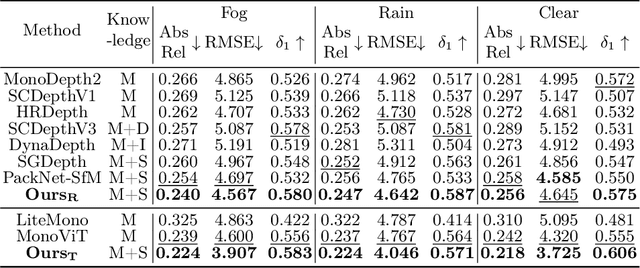
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.