 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024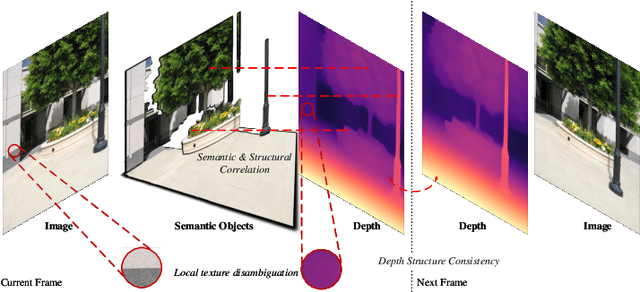
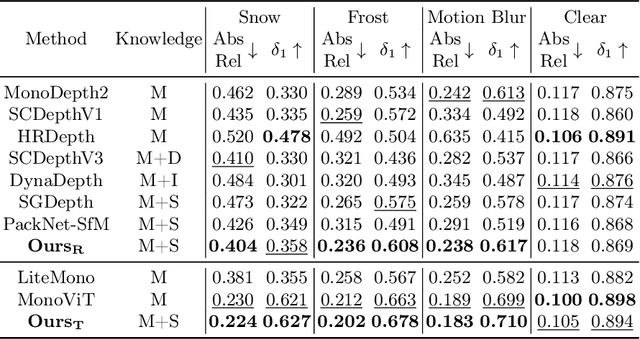
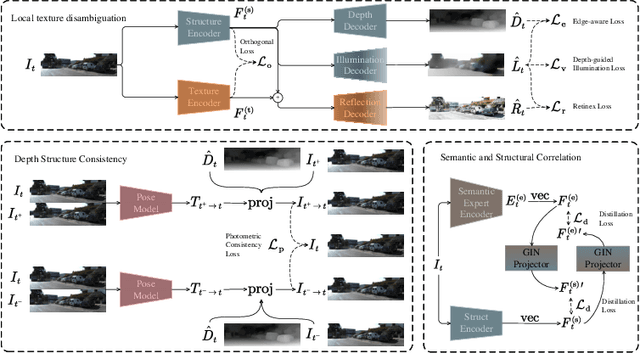
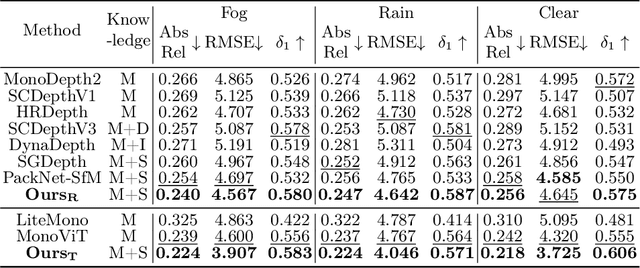
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
OccupancyDETR: Making Semantic Scene Completion as Straightforward as Object Detection
Sep 22, 2023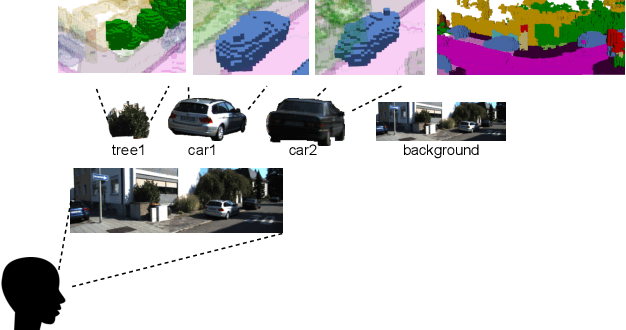
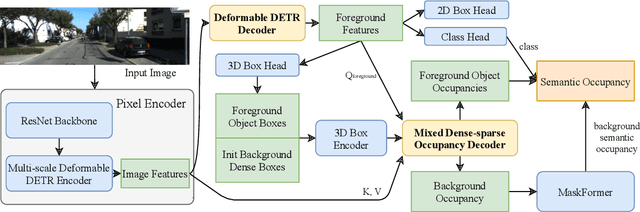
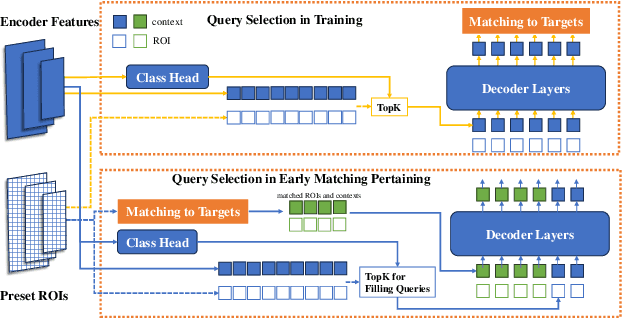
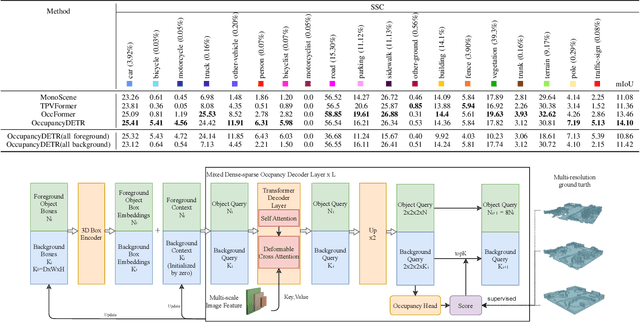
Visual-based 3D semantic occupancy perception (also known as 3D semantic scene completion) is a new perception paradigm for robotic applications like autonomous driving. Compared with Bird's Eye View (BEV) perception, it extends the vertical dimension, significantly enhancing the ability of robots to understand their surroundings. However, due to this very reason, the computational demand for current 3D semantic occupancy perception methods generally surpasses that of BEV perception methods and 2D perception methods. We propose a novel 3D semantic occupancy perception method, OccupancyDETR, which consists of a DETR-like object detection module and a 3D occupancy decoder module. The integration of object detection simplifies our method structurally - instead of predicting the semantics of each voxels, it identifies objects in the scene and their respective 3D occupancy grids. This speeds up our method, reduces required resources, and leverages object detection algorithm, giving our approach notable performance on small objects. We demonstrate the effectiveness of our proposed method on the SemanticKITTI dataset, showcasing an mIoU of 23 and a processing speed of 6 frames per second, thereby presenting a promising solution for real-time 3D semantic scene completion.
Lvio-Fusion: A Self-adaptive Multi-sensor Fusion SLAM Framework Using Actor-critic Method
Jun 12, 2021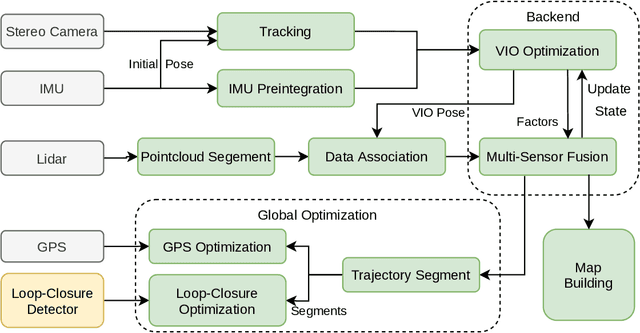
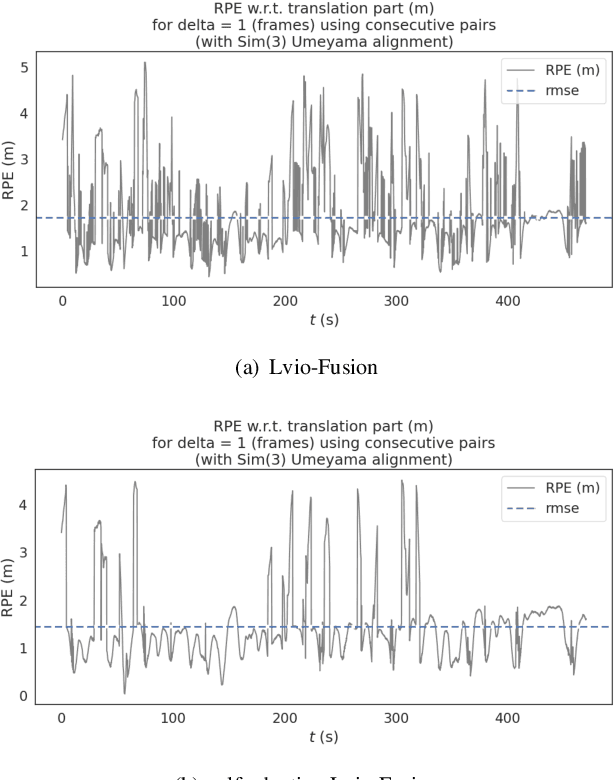

State estimation with sensors is essential for mobile robots. Due to sensors have different performance in different environments, how to fuse measurements of various sensors is a problem. In this paper, we propose a tightly-coupled multi-sensor fusion framework, Lvio-Fusion, which fuses stereo camera, Lidar, IMU, and GPS based on the graph optimization. Especially for urban traffic scenes, we introduce a segmented global pose graph optimization with GPS and loop-closure, which can eliminate accumulated drifts. Additionally, we creatively use a actor-critic method in reinforcement learning to adaptively adjust sensors' weight. After training, actor-critic agent can provide the system with better and dynamic sensors' weight. We evaluate the performance of our system on public datasets and compare it with other state-of-the-art methods, showing that the proposed method achieves high estimation accuracy and robustness to various environments. And our implementations are open source and highly scalable.