 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024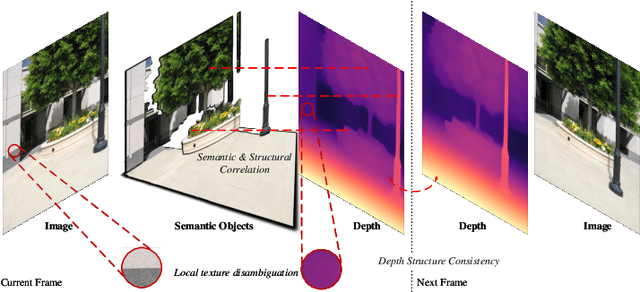
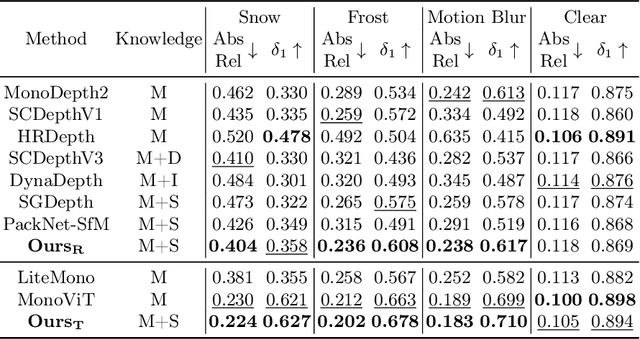
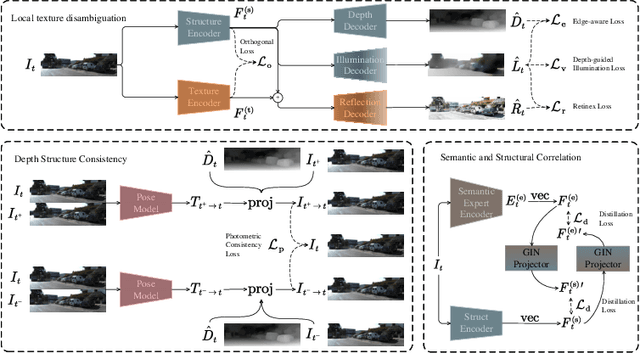
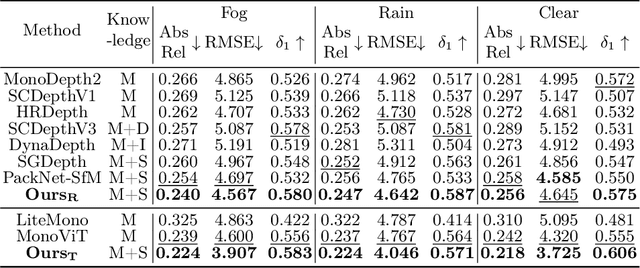
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
Map-Free Visual Relocalization Enhanced by Instance Knowledge and Depth Knowledge
Aug 23, 2024
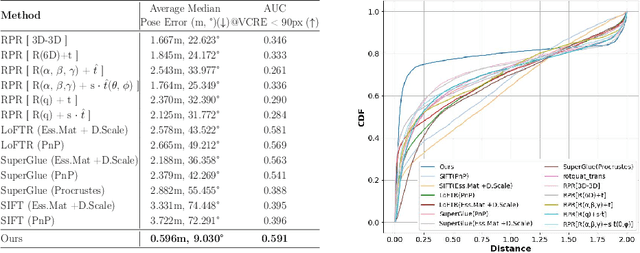
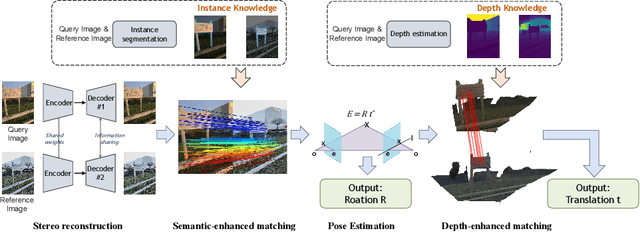

Map-free relocalization technology is crucial for applications in autonomous navigation and augmented reality, but relying on pre-built maps is often impractical. It faces significant challenges due to limitations in matching methods and the inherent lack of scale in monocular images. These issues lead to substantial rotational and metric errors and even localization failures in real-world scenarios. Large matching errors significantly impact the overall relocalization process, affecting both rotational and translational accuracy. Due to the inherent limitations of the camera itself, recovering the metric scale from a single image is crucial, as this significantly impacts the translation error. To address these challenges, we propose a map-free relocalization method enhanced by instance knowledge and depth knowledge. By leveraging instance-based matching information to improve global matching results, our method significantly reduces the possibility of mismatching across different objects. The robustness of instance knowledge across the scene helps the feature point matching model focus on relevant regions and enhance matching accuracy. Additionally, we use estimated metric depth from a single image to reduce metric errors and improve scale recovery accuracy. By integrating methods dedicated to mitigating large translational and rotational errors, our approach demonstrates superior performance in map-free relocalization techniques.