 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftHGNN: Soft Hypergraph Neural Networks for General Visual Recognition
May 21, 2025Visual recognition relies on understanding both the semantics of image tokens and the complex interactions among them. Mainstream self-attention methods, while effective at modeling global pair-wise relations, fail to capture high-order associations inherent in real-world scenes and often suffer from redundant computation. Hypergraphs extend conventional graphs by modeling high-order interactions and offer a promising framework for addressing these limitations. However, existing hypergraph neural networks typically rely on static and hard hyperedge assignments, leading to excessive and redundant hyperedges with hard binary vertex memberships that overlook the continuity of visual semantics. To overcome these issues, we present Soft Hypergraph Neural Networks (SoftHGNNs), which extend the methodology of hypergraph computation, to make it truly efficient and versatile in visual recognition tasks. Our framework introduces the concept of soft hyperedges, where each vertex is associated with hyperedges via continuous participation weights rather than hard binary assignments. This dynamic and differentiable association is achieved by using the learnable hyperedge prototype. Through similarity measurements between token features and the prototype, the model generates semantically rich soft hyperedges. SoftHGNN then aggregates messages over soft hyperedges to capture high-order semantics. To further enhance efficiency when scaling up the number of soft hyperedges, we incorporate a sparse hyperedge selection mechanism that activates only the top-k important hyperedges, along with a load-balancing regularizer to ensure balanced hyperedge utilization. Experimental results across three tasks on five datasets demonstrate that SoftHGNN efficiently captures high-order associations in visual scenes, achieving significant performance improvements.
ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
Dec 11, 2024



Medical image segmentation plays an important role in clinical decision making, treatment planning, and disease tracking. However, it still faces two major challenges. On the one hand, there is often a ``soft boundary'' between foreground and background in medical images, with poor illumination and low contrast further reducing the distinguishability of foreground and background within the image. On the other hand, co-occurrence phenomena are widespread in medical images, and learning these features is misleading to the model's judgment. To address these challenges, we propose a general framework called Contrast-Driven Medical Image Segmentation (ConDSeg). First, we develop a contrastive training strategy called Consistency Reinforcement. It is designed to improve the encoder's robustness in various illumination and contrast scenarios, enabling the model to extract high-quality features even in adverse environments. Second, we introduce a Semantic Information Decoupling module, which is able to decouple features from the encoder into foreground, background, and uncertainty regions, gradually acquiring the ability to reduce uncertainty during training. The Contrast-Driven Feature Aggregation module then contrasts the foreground and background features to guide multi-level feature fusion and key feature enhancement, further distinguishing the entities to be segmented. We also propose a Size-Aware Decoder to solve the scale singularity of the decoder. It accurately locate entities of different sizes in the image, thus avoiding erroneous learning of co-occurrence features. Extensive experiments on five medical image datasets across three scenarios demonstrate the state-of-the-art performance of our method, proving its advanced nature and general applicability to various medical image segmentation scenarios. Our released code is available at \url{https://github.com/Mengqi-Lei/ConDSeg}.
Dysca: A Dynamic and Scalable Benchmark for Evaluating Perception Ability of LVLMs
Jun 27, 2024



Currently many benchmarks have been proposed to evaluate the perception ability of the Large Vision-Language Models (LVLMs). However, most benchmarks conduct questions by selecting images from existing datasets, resulting in the potential data leakage. Besides, these benchmarks merely focus on evaluating LVLMs on the realistic style images and clean scenarios, leaving the multi-stylized images and noisy scenarios unexplored. In response to these challenges, we propose a dynamic and scalable benchmark named Dysca for evaluating LVLMs by leveraging synthesis images. Specifically, we leverage Stable Diffusion and design a rule-based method to dynamically generate novel images, questions and the corresponding answers. We consider 51 kinds of image styles and evaluate the perception capability in 20 subtasks. Moreover, we conduct evaluations under 4 scenarios (i.e., Clean, Corruption, Print Attacking and Adversarial Attacking) and 3 question types (i.e., Multi-choices, True-or-false and Free-form). Thanks to the generative paradigm, Dysca serves as a scalable benchmark for easily adding new subtasks and scenarios. A total of 8 advanced open-source LVLMs with 10 checkpoints are evaluated on Dysca, revealing the drawbacks of current LVLMs. The benchmark is released in \url{https://github.com/Benchmark-Dysca/Dysca}.
EPPS: Advanced Polyp Segmentation via Edge Information Injection and Selective Feature Decoupling
May 20, 2024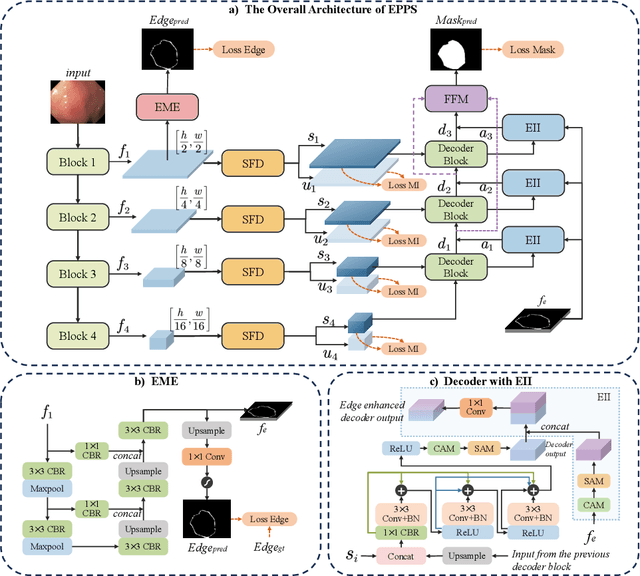



Accurate segmentation of polyps in colonoscopy images is essential for early-stage diagnosis and management of colorectal cancer. Despite advancements in deep learning for polyp segmentation, enduring limitations persist. The edges of polyps are typically ambiguous, making them difficult to discern from the background, and the model performance is often compromised by the influence of irrelevant or unimportant features. To alleviate these challenges, we propose a novel model named Edge-Prioritized Polyp Segmentation (EPPS). Specifically, we incorporate an Edge Mapping Engine (EME) aimed at accurately extracting the edges of polyps. Subsequently, an Edge Information Injector (EII) is devised to augment the mask prediction by injecting the captured edge information into Decoder blocks. Furthermore, we introduce a component called Selective Feature Decoupler (SFD) to suppress the influence of noise and extraneous features on the model. Extensive experiments on 3 widely used polyp segmentation benchmarks demonstrate the superior performance of our method compared with other state-of-the-art approaches.