 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Acoustic Parameter Estimation
Oct 31, 2024

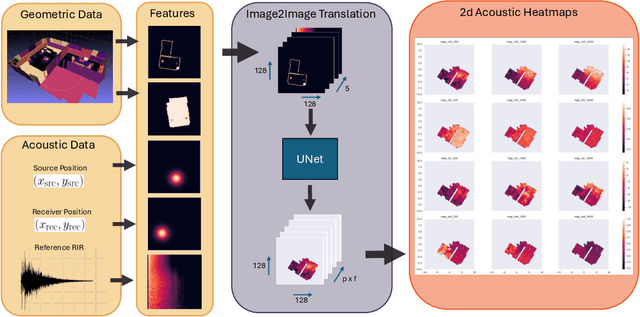
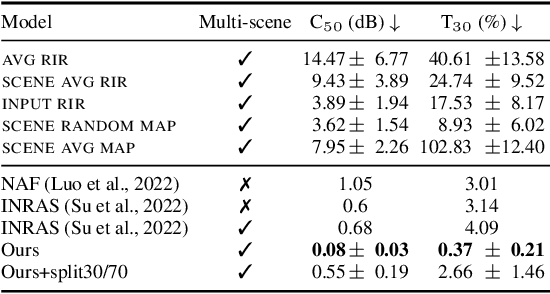
The task of Novel View Acoustic Synthesis (NVAS) - generating Room Impulse Responses (RIRs) for unseen source and receiver positions in a scene - has recently gained traction, especially given its relevance to Augmented Reality (AR) and Virtual Reality (VR) development. However, many of these efforts suffer from similar limitations: they infer RIRs in the time domain, which prove challenging to optimize; they focus on scenes with simple, single-room geometries; they infer only single-channel, directionally-independent acoustic characteristics; and they require inputs, such as 3D geometry meshes with material properties, that may be impractical to obtain for on-device applications. On the other hand, research suggests that sample-wise accuracy of RIRs is not required for perceptual plausibility in AR and VR. Standard acoustic parameters like Clarity Index (C50) or Reverberation Time (T60) have been shown to capably describe pertinent characteristics of the RIRs, especially late reverberation. To address these gaps, this paper introduces a new task centered on estimating spatially distributed acoustic parameters that can be then used to condition a simple reverberator for arbitrary source and receiver positions. The approach is modelled as an image-to-image translation task, which translates 2D floormaps of a scene into 2D heatmaps of acoustic parameters. We introduce a new, large-scale dataset of 1000 scenes consisting of complex, multi-room apartment conditions, and show that our method outperforms statistical baselines significantly. Moreover, we show that the method also works for directionally-dependent (i.e. beamformed) parameter prediction. Finally, the proposed method operates on very limited information, requiring only a broad outline of the scene and a single RIR at inference time.
Spatial mixup: Directional loudness modification as data augmentation for sound event localization and detection
Oct 12, 2021

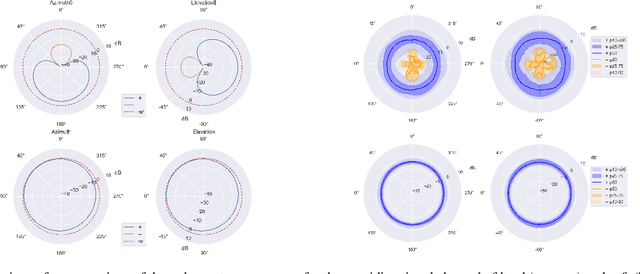
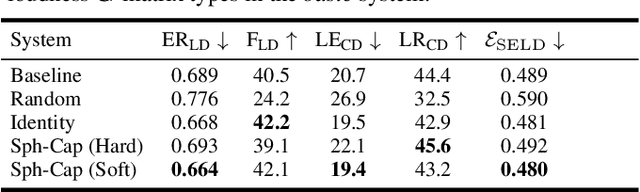
Data augmentation methods have shown great importance in diverse supervised learning problems where labeled data is scarce or costly to obtain. For sound event localization and detection (SELD) tasks several augmentation methods have been proposed, with most borrowing ideas from other domains such as images, speech, or monophonic audio. However, only a few exploit the spatial properties of a full 3D audio scene. We propose Spatial Mixup, as an application of parametric spatial audio effects for data augmentation, which modifies the directional properties of a multi-channel spatial audio signal encoded in the ambisonics domain. Similarly to beamforming, these modifications enhance or suppress signals arriving from certain directions, although the effect is less pronounced. Therefore enabling deep learning models to achieve invariance to small spatial perturbations. The method is evaluated with experiments in the DCASE 2021 Task 3 dataset, where spatial mixup increases performance over a non-augmented baseline, and compares to other well known augmentation methods. Furthermore, combining spatial mixup with other methods greatly improves performance.