 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial mixup: Directional loudness modification as data augmentation for sound event localization and detection
Paper and Code
Oct 12, 2021

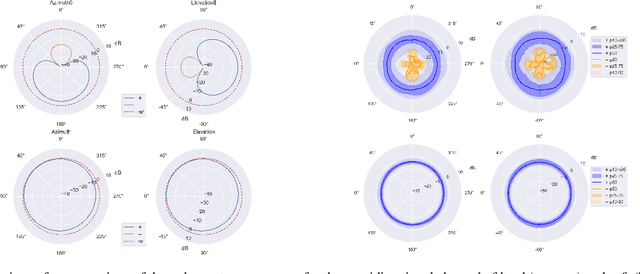
Data augmentation methods have shown great importance in diverse supervised learning problems where labeled data is scarce or costly to obtain. For sound event localization and detection (SELD) tasks several augmentation methods have been proposed, with most borrowing ideas from other domains such as images, speech, or monophonic audio. However, only a few exploit the spatial properties of a full 3D audio scene. We propose Spatial Mixup, as an application of parametric spatial audio effects for data augmentation, which modifies the directional properties of a multi-channel spatial audio signal encoded in the ambisonics domain. Similarly to beamforming, these modifications enhance or suppress signals arriving from certain directions, although the effect is less pronounced. Therefore enabling deep learning models to achieve invariance to small spatial perturbations. The method is evaluated with experiments in the DCASE 2021 Task 3 dataset, where spatial mixup increases performance over a non-augmented baseline, and compares to other well known augmentation methods. Furthermore, combining spatial mixup with other methods greatly improves performance.