 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Gossip BMUF Process for Neural Language Modeling
Oct 16, 2019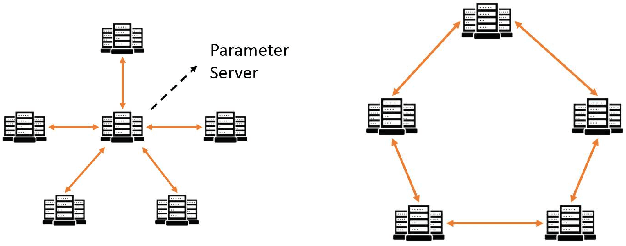
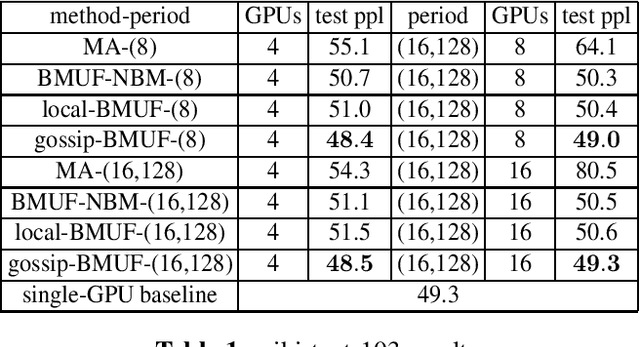
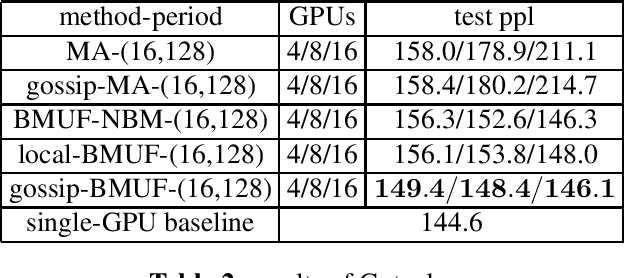
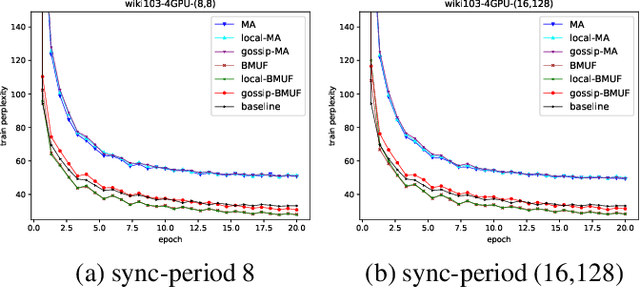
Neural network language model (NNLM) is an essential component of industrial ASR systems. One important challenge of training an NNLM is to leverage between scaling the learning process and handling big data. Conventional approaches such as block momentum provides a blockwise model update filtering (BMUF) process and achieves almost linear speedups with no performance degradation for speech recognition. However, it needs to calculate the model average from all computing nodes (e.g., GPUs) and when the number of computing nodes is large, the learning suffers from the severe communication latency. As a consequence, BMUF is not suitable under restricted network conditions. In this paper, we present a decentralized BMUF process, in which the model is split into different components, each of which is updated by communicating to some randomly chosen neighbor nodes with the same component, followed by a BMUF-like process. We apply this method to several LSTM language modeling tasks. Experimental results show that our approach achieves consistently better performance than conventional BMUF. In particular, we obtain a lower perplexity than the single-GPU baseline on the wiki-text-103 benchmark using 4 GPUs. In addition, no performance degradation is observed when scaling to 8 and 16 GPUs.