 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Optimizers: Improving Training with One Line of Code
Paper and Code


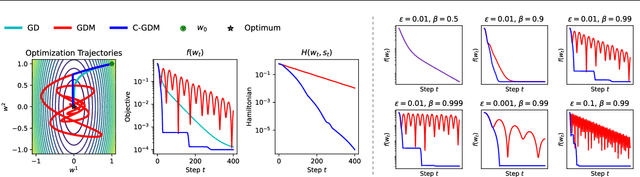

AdamW has been the default optimizer for transformer pretraining. For many years, our community searches for faster and more stable optimizers with only constraint positive outcomes. In this work, we propose a \textbf{single-line modification in Pytorch} to any momentum-based optimizer, which we rename Cautious Optimizer, e.g. C-AdamW and C-Lion. Our theoretical result shows that this modification preserves Adam's Hamiltonian function and it does not break the convergence guarantee under the Lyapunov analysis. In addition, a whole new family of optimizers is revealed by our theoretical insight. Among them, we pick the simplest one for empirical experiments, showing speed-up on Llama and MAE pretraining up to $1.47\times$. Code is available at https://github.com/kyleliang919/C-Optim