 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposition of Experts: A Modular Compound AI System Leveraging Large Language Models
Dec 02, 2024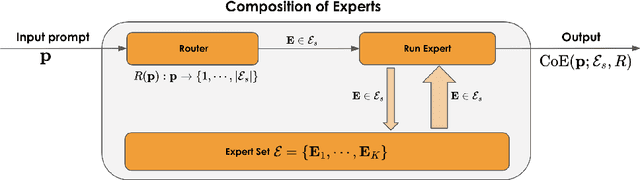
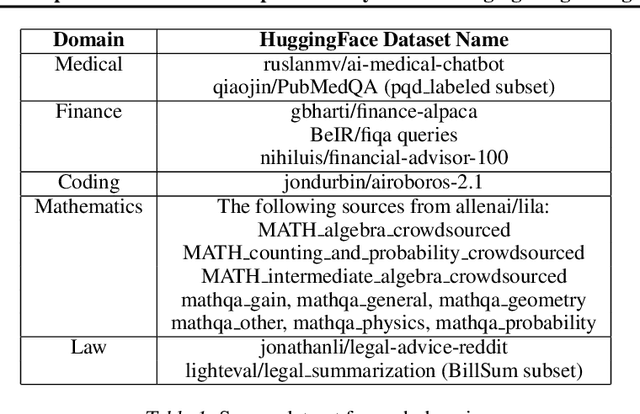
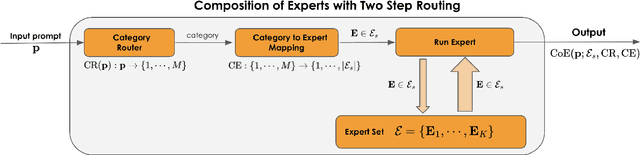
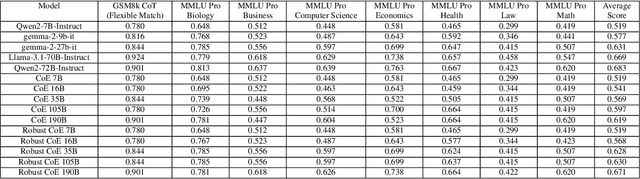
Large Language Models (LLMs) have achieved remarkable advancements, but their monolithic nature presents challenges in terms of scalability, cost, and customization. This paper introduces the Composition of Experts (CoE), a modular compound AI system leveraging multiple expert LLMs. CoE leverages a router to dynamically select the most appropriate expert for a given input, enabling efficient utilization of resources and improved performance. We formulate the general problem of training a CoE and discuss inherent complexities associated with it. We propose a two-step routing approach to address these complexities that first uses a router to classify the input into distinct categories followed by a category-to-expert mapping to obtain desired experts. CoE offers a flexible and cost-effective solution to build compound AI systems. Our empirical evaluation demonstrates the effectiveness of CoE in achieving superior performance with reduced computational overhead. Given that CoE comprises of many expert LLMs it has unique system requirements for cost-effective serving. We present an efficient implementation of CoE leveraging SambaNova SN40L RDUs unique three-tiered memory architecture. CoEs obtained using open weight LLMs Qwen/Qwen2-7B-Instruct, google/gemma-2-9b-it, google/gemma-2-27b-it, meta-llama/Llama-3.1-70B-Instruct and Qwen/Qwen2-72B-Instruct achieve a score of $59.4$ with merely $31$ billion average active parameters on Arena-Hard and a score of $9.06$ with $54$ billion average active parameters on MT-Bench.
Constructing Domain-Specific Evaluation Sets for LLM-as-a-judge
Aug 16, 2024



Large Language Models (LLMs) have revolutionized the landscape of machine learning, yet current benchmarks often fall short in capturing the diverse behavior of these models in real-world applications. A benchmark's usefulness is determined by its ability to clearly differentiate between models of varying capabilities (separability) and closely align with human preferences. Existing frameworks like Alpaca-Eval 2.0 LC \cite{dubois2024lengthcontrolledalpacaevalsimpleway} and Arena-Hard v0.1 \cite{li2024crowdsourced} are limited by their focus on general-purpose queries and lack of diversity across domains such as law, medicine, and multilingual contexts. In this paper, we address these limitations by introducing a novel data pipeline that curates diverse, domain-specific evaluation sets tailored for LLM-as-a-Judge frameworks. Our approach leverages a combination of manual curation, semi-supervised learning to generate clusters, and stratified sampling to ensure balanced representation across a wide range of domains and languages. The resulting evaluation set, which includes 1573 samples across 14 categories, demonstrates high separability (84\%) across ten top-ranked models, and agreement (84\%) with Chatbot Arena and (0.915) Spearman correlation. The agreement values are 9\% better than Arena Hard and 20\% better than AlpacaEval 2.0 LC, while the Spearman coefficient is 0.7 more than the next best benchmark, showcasing a significant improvement in the usefulness of the benchmark. We further provide an open-source evaluation tool that enables fine-grained analysis of model performance across user-defined categories, offering valuable insights for practitioners. This work contributes to the ongoing effort to enhance the transparency, diversity, and effectiveness of LLM evaluation methodologies.