 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUIA: Model Inversion Attack against Federated Unlearning
Feb 20, 2025



With the introduction of regulations related to the ``right to be forgotten", federated learning (FL) is facing new privacy compliance challenges. To address these challenges, researchers have proposed federated unlearning (FU). However, existing FU research has primarily focused on improving the efficiency of unlearning, with less attention paid to the potential privacy vulnerabilities inherent in these methods. To address this gap, we draw inspiration from gradient inversion attacks in FL and propose the federated unlearning inversion attack (FUIA). The FUIA is specifically designed for the three types of FU (sample unlearning, client unlearning, and class unlearning), aiming to provide a comprehensive analysis of the privacy leakage risks associated with FU. In FUIA, the server acts as an honest-but-curious attacker, recording and exploiting the model differences before and after unlearning to expose the features and labels of forgotten data. FUIA significantly leaks the privacy of forgotten data and can target all types of FU. This attack contradicts the goal of FU to eliminate specific data influence, instead exploiting its vulnerabilities to recover forgotten data and expose its privacy flaws. Extensive experimental results show that FUIA can effectively reveal the private information of forgotten data. To mitigate this privacy leakage, we also explore two potential defense methods, although these come at the cost of reduced unlearning effectiveness and the usability of the unlearned model.
Streamlined Federated Unlearning: Unite as One to Be Highly Efficient
Nov 28, 2024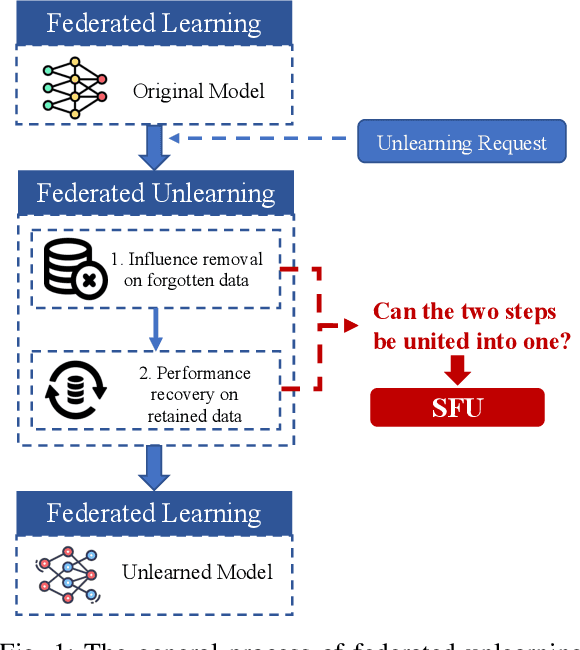
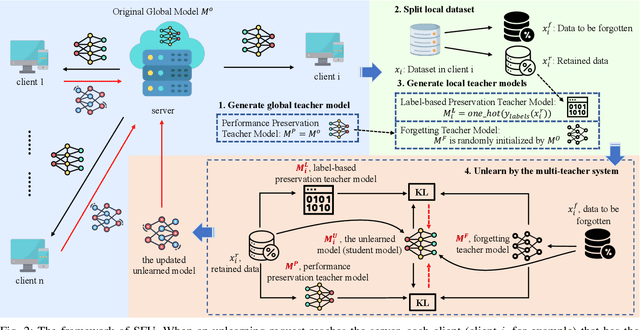
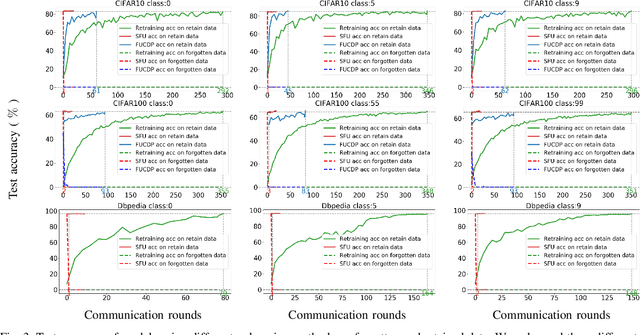
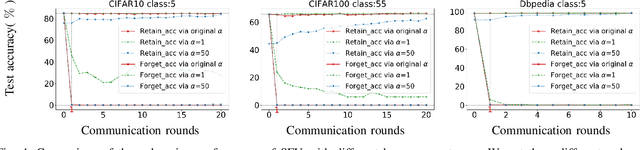
Recently, the enactment of "right to be forgotten" laws and regulations has imposed new privacy requirements on federated learning (FL). Researchers aim to remove the influence of certain data from the trained model without training from scratch through federated unlearning (FU). While current FU research has shown progress in enhancing unlearning efficiency, it often results in degraded model performance upon achieving the goal of data unlearning, necessitating additional steps to recover the performance of the unlearned model. Moreover, these approaches also suffer from many shortcomings such as high consumption of computational and storage resources. To this end, we propose a streamlined federated unlearning approach (SFU) aimed at effectively removing the influence of target data while preserving the model's performance on the retained data without degradation. We design a practical multi-teacher system that achieves both target data influence removal and model performance preservation by guiding the unlearned model through several distinct teacher models. SFU is both computationally and storage-efficient, highly flexible, and generalizable. We conducted extensive experiments on both image and text benchmark datasets. The results demonstrate that SFU significantly improves time and communication efficiency compared to the benchmark retraining method and significantly outperforms existing state-of-the-art (SOTA) methods. Additionally, we verified the effectiveness of SFU using the backdoor attack.