 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesNAS: A Bayesian Approach for Neural Architecture Search
Paper and Code
May 13, 2019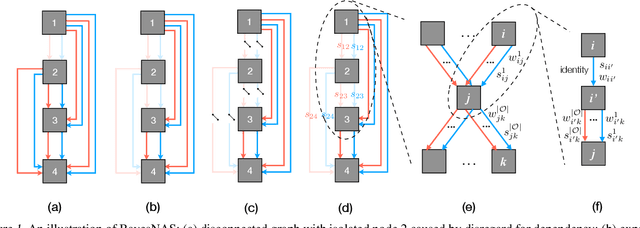

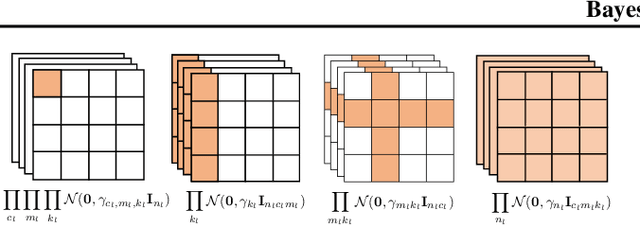

One-Shot Neural Architecture Search (NAS) is a promising method to significantly reduce search time without any separate training. It can be treated as a Network Compression problem on the architecture parameters from an over-parameterized network. However, there are two issues associated with most one-shot NAS methods. First, dependencies between a node and its predecessors and successors are often disregarded which result in improper treatment over zero operations. Second, architecture parameters pruning based on their magnitude is questionable. In this paper, we employ the classic Bayesian learning approach to alleviate these two issues by modeling architecture parameters using hierarchical automatic relevance determination (HARD) priors. Unlike other NAS methods, we train the over-parameterized network for only one epoch then update the architecture. Impressively, this enabled us to find the architecture in both proxy and proxyless tasks on CIFAR-10 within only 0.2 GPU days using a single GPU. As a byproduct, our approach can be transferred directly to compress convolutional neural networks by enforcing structural sparsity which achieves extremely sparse networks without accuracy deterioration.