 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-SA: Strengthen In-context Learning via Submodular Selective Annotation
Jul 08, 2024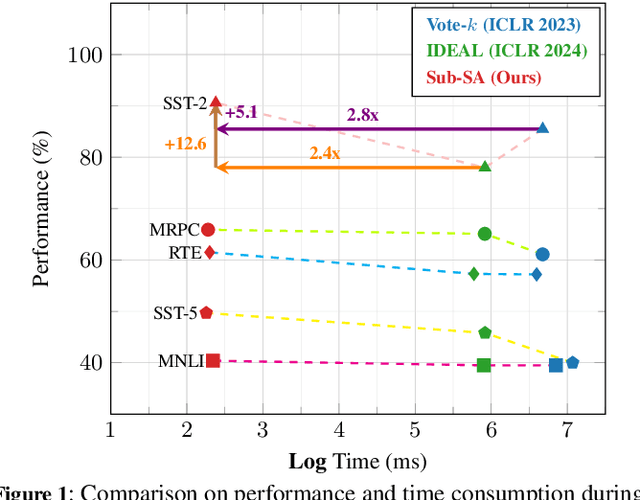
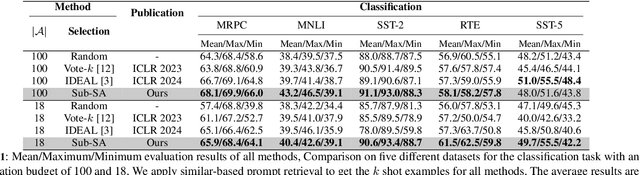

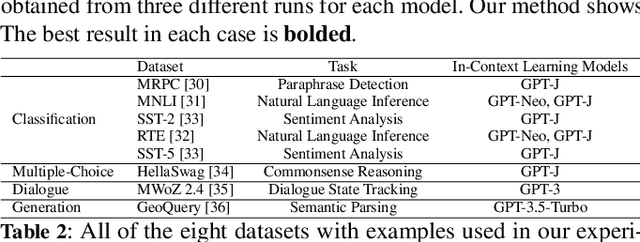
In-context learning (ICL) leverages in-context examples as prompts for the predictions of Large Language Models (LLMs). These prompts play a crucial role in achieving strong performance. However, the selection of suitable prompts from a large pool of labeled examples often entails significant annotation costs. To address this challenge, we propose \textbf{Sub-SA} (\textbf{Sub}modular \textbf{S}elective \textbf{A}nnotation), a submodule-based selective annotation method. The aim of Sub-SA is to reduce annotation costs while improving the quality of in-context examples and minimizing the time consumption of the selection process. In Sub-SA, we design a submodular function that facilitates effective subset selection for annotation and demonstrates the characteristics of monotonically and submodularity from the theoretical perspective. Specifically, we propose \textbf{RPR} (\textbf{R}eward and \textbf{P}enalty \textbf{R}egularization) to better balance the diversity and representativeness of the unlabeled dataset attributed to a reward term and a penalty term, respectively. Consequently, the selection for annotations can be effectively addressed with a simple yet effective greedy search algorithm based on the submodular function. Finally, we apply the similarity prompt retrieval to get the examples for ICL.
TimeLDM: Latent Diffusion Model for Unconditional Time Series Generation
Jul 05, 2024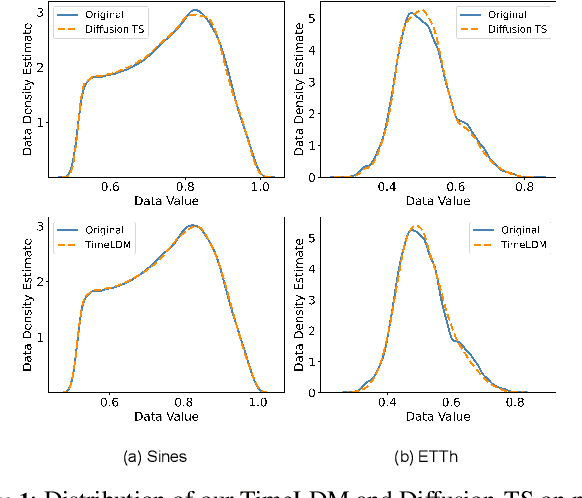

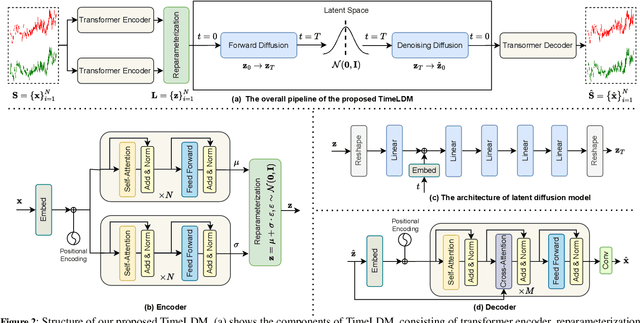
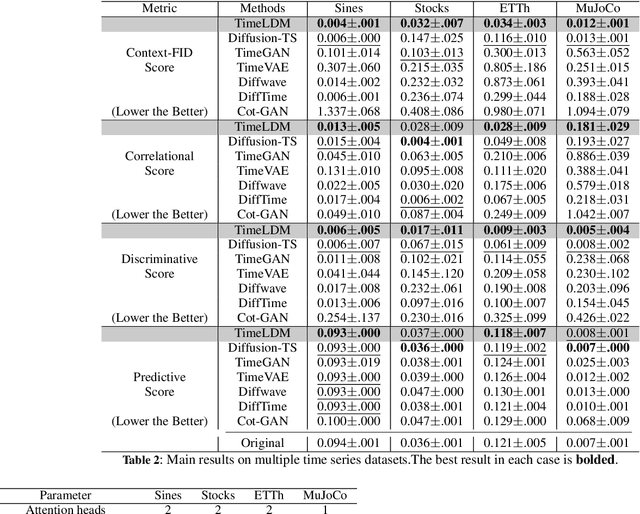
Time series generation is a crucial research topic in the area of deep learning, which can be used for data augmentation, imputing missing values, and forecasting. Currently, latent diffusion models are ascending to the forefront of generative modeling for many important data representations. Being the most pivotal in the computer vision domain, latent diffusion models have also recently attracted interest in other communities, including NLP, Speech, and Geometric Space. In this work, we propose TimeLDM, a novel latent diffusion model for high-quality time series generation. TimeLDM is composed of a variational autoencoder that encodes time series into an informative and smoothed latent content and a latent diffusion model operating in the latent space to generate latent information. We evaluate the ability of our method to generate synthetic time series with simulated and realistic datasets, benchmark the performance against existing state-of-the-art methods. Qualitatively and quantitatively, we find that the proposed TimeLDM persistently delivers high-quality generated time series. Sores from Context-FID and Discriminative indicate that TimeLDM consistently and significantly outperforms current state-of-the-art benchmarks with an average improvement of 3.4$\times$ and 3.8$\times$, respectively. Further studies demonstrate that our method presents better performance on different lengths of time series data generation. To the best of our knowledge, this is the first study to explore the potential of the latent diffusion model for unconditional time series generation and establish a new baseline for synthetic time series.
FotonNet: A HW-Efficient Object Detection System Using 3D-Depth Segmentation and 2D-DNN Classifier
Nov 19, 2018
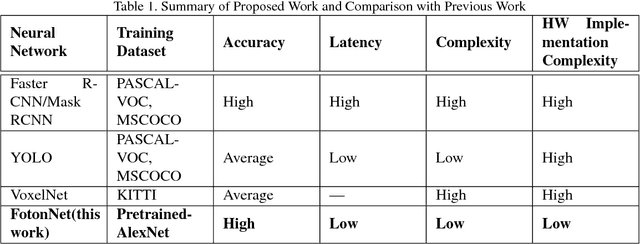
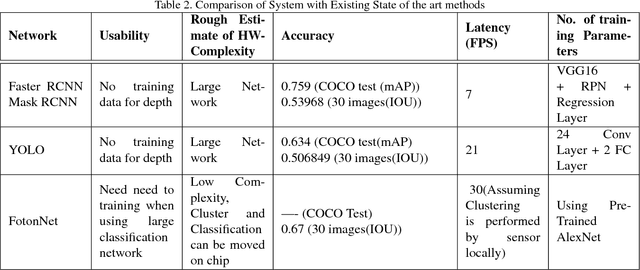
Object detection and classification is one of the most important computer vision problems. Ever since the introduction of deep learning \cite{krizhevsky2012imagenet}, we have witnessed a dramatic increase in the accuracy of this object detection problem. However, most of these improvements have occurred using conventional 2D image processing. Recently, low-cost 3D-image sensors, such as the Microsoft Kinect (Time-of-Flight) or the Apple FaceID (Structured-Light), can provide 3D-depth or point cloud data that can be added to a convolutional neural network, acting as an extra set of dimensions. In our proposed approach, we introduce a new 2D + 3D system that takes the 3D-data to determine the object region followed by any conventional 2D-DNN, such as AlexNet. In this method, our approach can easily dissociate the information collection from the Point Cloud and 2D-Image data and combine both operations later. Hence, our system can use any existing trained 2D network on a large image dataset, and does not require a large 3D-depth dataset for new training. Experimental object detection results across 30 images show an accuracy of 0.67, versus 0.54 and 0.51 for RCNN and YOLO, respectively.