 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-temporal V-Net for automatic segmentation and quantification of right ventricles in gated myocardial perfusion SPECT images
Oct 11, 2021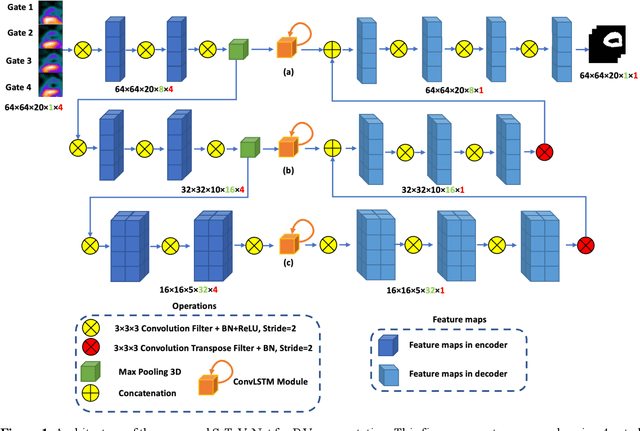
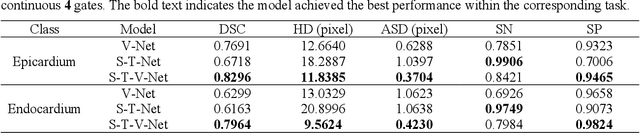
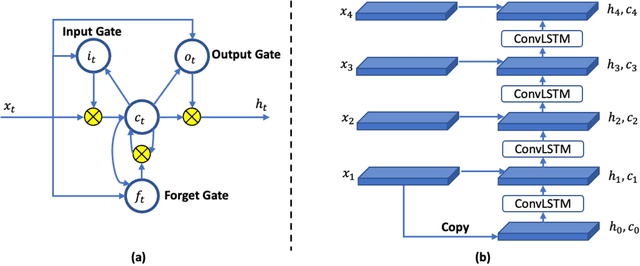
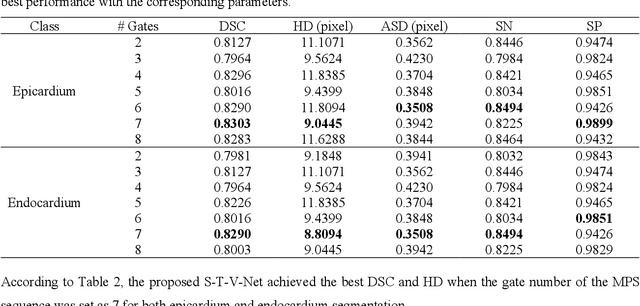
Background. Functional assessment of right ventricles (RV) using gated myocardial perfusion single-photon emission computed tomography (MPS) heavily relies on the precise extraction of right ventricular contours. In this paper, we present a new deep learning model integrating both the spatial and temporal features in SPECT images to perform the segmentation of RV epicardium and endocardium. Methods. By integrating the spatial features from each cardiac frame of gated MPS and the temporal features from the sequential cardiac frames of the gated MPS, we develop a Spatial-Temporal V-Net (S-T-V-Net) for automatic extraction of RV endocardial and epicardial contours. In the S-T-V-Net, a V-Net is employed to hierarchically extract spatial features, and convolutional long-term short-term memory (ConvLSTM) units are added to the skip-connection pathway to extract the temporal features. The input of the S-T-V-Net is an ECG-gated sequence of the SPECT images and the output is the probability map of the endocardial or epicardial masks. A Dice similarity coefficient (DSC) loss which penalizes the discrepancy between the model prediction and the ground truth is adopted to optimize the segmentation model. Results. Our segmentation model was trained and validated on a retrospective dataset with 34 subjects, and the cardiac cycle of each subject was divided into 8 gates. The proposed ST-V-Net achieved a DSC of 0.7924 and 0.8227 for the RV endocardium and epicardium, respectively. The mean absolute error, the mean squared error, and the Pearson correlation coefficient of the RV ejection fraction between the ground truth and the model prediction are 0.0907, 0.0130 and 0.8411. Conclusion. The results demonstrate that the proposed ST-V-Net is an effective model for RV segmentation. It has great promise for clinical use in RV functional assessment.
FotonNet: A HW-Efficient Object Detection System Using 3D-Depth Segmentation and 2D-DNN Classifier
Nov 19, 2018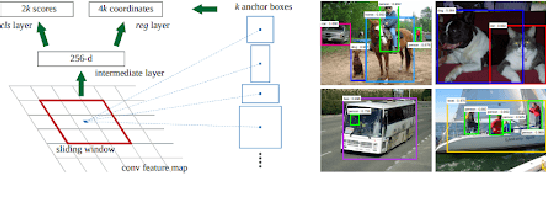
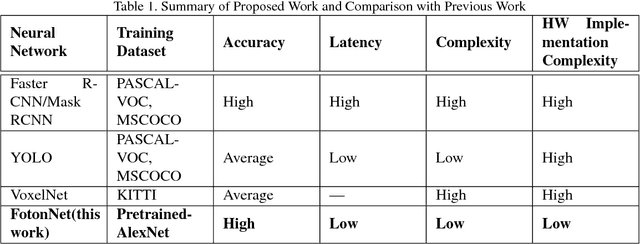
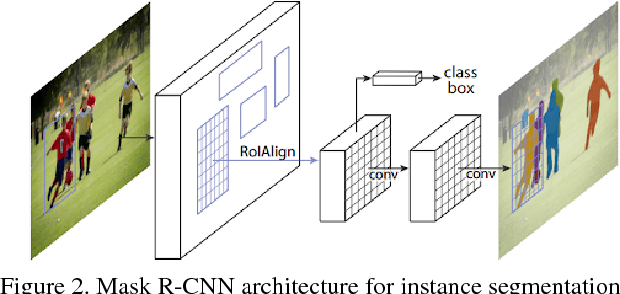
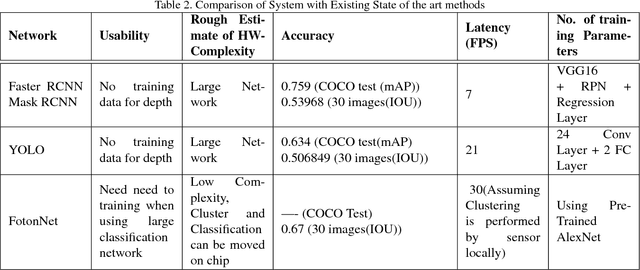
Object detection and classification is one of the most important computer vision problems. Ever since the introduction of deep learning \cite{krizhevsky2012imagenet}, we have witnessed a dramatic increase in the accuracy of this object detection problem. However, most of these improvements have occurred using conventional 2D image processing. Recently, low-cost 3D-image sensors, such as the Microsoft Kinect (Time-of-Flight) or the Apple FaceID (Structured-Light), can provide 3D-depth or point cloud data that can be added to a convolutional neural network, acting as an extra set of dimensions. In our proposed approach, we introduce a new 2D + 3D system that takes the 3D-data to determine the object region followed by any conventional 2D-DNN, such as AlexNet. In this method, our approach can easily dissociate the information collection from the Point Cloud and 2D-Image data and combine both operations later. Hence, our system can use any existing trained 2D network on a large image dataset, and does not require a large 3D-depth dataset for new training. Experimental object detection results across 30 images show an accuracy of 0.67, versus 0.54 and 0.51 for RCNN and YOLO, respectively.