 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFotonNet: A HW-Efficient Object Detection System Using 3D-Depth Segmentation and 2D-DNN Classifier
Nov 19, 2018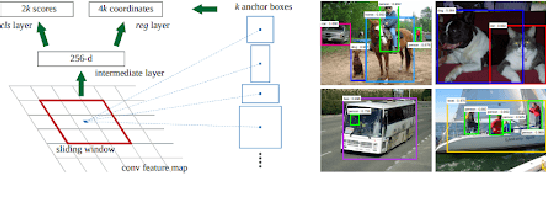
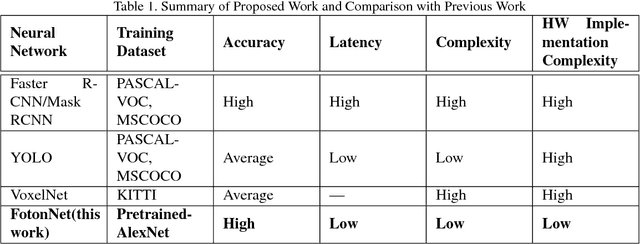
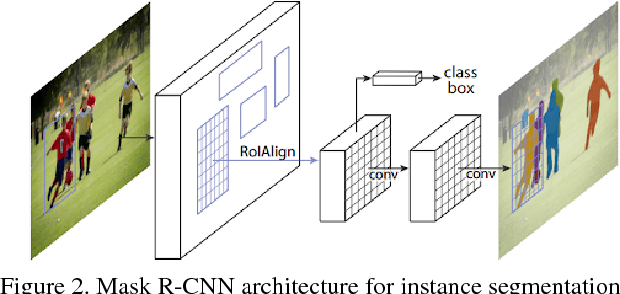
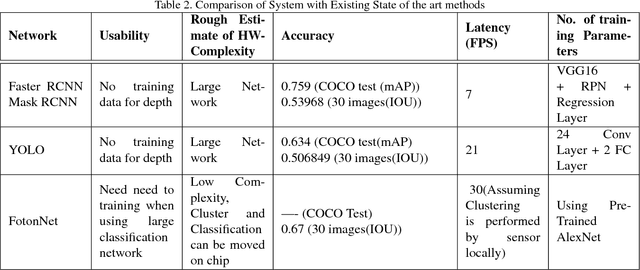
Object detection and classification is one of the most important computer vision problems. Ever since the introduction of deep learning \cite{krizhevsky2012imagenet}, we have witnessed a dramatic increase in the accuracy of this object detection problem. However, most of these improvements have occurred using conventional 2D image processing. Recently, low-cost 3D-image sensors, such as the Microsoft Kinect (Time-of-Flight) or the Apple FaceID (Structured-Light), can provide 3D-depth or point cloud data that can be added to a convolutional neural network, acting as an extra set of dimensions. In our proposed approach, we introduce a new 2D + 3D system that takes the 3D-data to determine the object region followed by any conventional 2D-DNN, such as AlexNet. In this method, our approach can easily dissociate the information collection from the Point Cloud and 2D-Image data and combine both operations later. Hence, our system can use any existing trained 2D network on a large image dataset, and does not require a large 3D-depth dataset for new training. Experimental object detection results across 30 images show an accuracy of 0.67, versus 0.54 and 0.51 for RCNN and YOLO, respectively.