 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-SA: Strengthen In-context Learning via Submodular Selective Annotation
Jul 08, 2024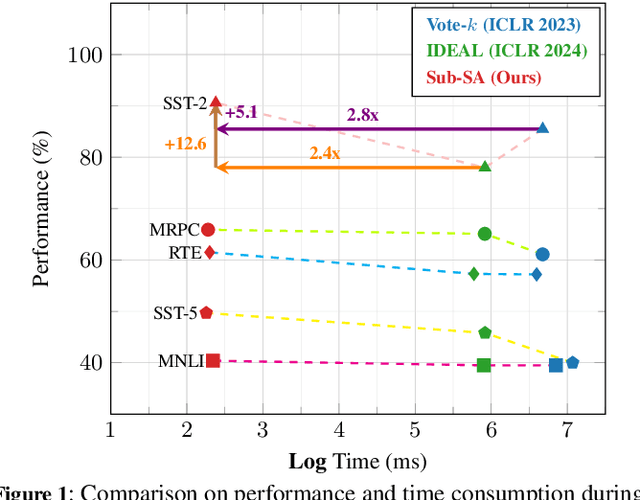
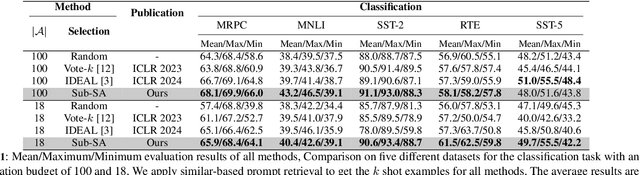

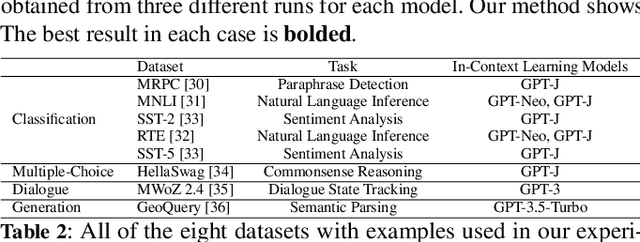
In-context learning (ICL) leverages in-context examples as prompts for the predictions of Large Language Models (LLMs). These prompts play a crucial role in achieving strong performance. However, the selection of suitable prompts from a large pool of labeled examples often entails significant annotation costs. To address this challenge, we propose \textbf{Sub-SA} (\textbf{Sub}modular \textbf{S}elective \textbf{A}nnotation), a submodule-based selective annotation method. The aim of Sub-SA is to reduce annotation costs while improving the quality of in-context examples and minimizing the time consumption of the selection process. In Sub-SA, we design a submodular function that facilitates effective subset selection for annotation and demonstrates the characteristics of monotonically and submodularity from the theoretical perspective. Specifically, we propose \textbf{RPR} (\textbf{R}eward and \textbf{P}enalty \textbf{R}egularization) to better balance the diversity and representativeness of the unlabeled dataset attributed to a reward term and a penalty term, respectively. Consequently, the selection for annotations can be effectively addressed with a simple yet effective greedy search algorithm based on the submodular function. Finally, we apply the similarity prompt retrieval to get the examples for ICL.