 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neighbor Layer Aggregation for Lightweight Self-Supervised Monocular Depth Estimation
Sep 17, 2023With the frequent use of self-supervised monocular depth estimation in robotics and autonomous driving, the model's efficiency is becoming increasingly important. Most current approaches apply much larger and more complex networks to improve the precision of depth estimation. Some researchers incorporated Transformer into self-supervised monocular depth estimation to achieve better performance. However, this method leads to high parameters and high computation. We present a fully convolutional depth estimation network using contextual feature fusion. Compared to UNet++ and HRNet, we use high-resolution and low-resolution features to reserve information on small targets and fast-moving objects instead of long-range fusion. We further promote depth estimation results employing lightweight channel attention based on convolution in the decoder stage. Our method reduces the parameters without sacrificing accuracy. Experiments on the KITTI benchmark show that our method can get better results than many large models, such as Monodepth2, with only 30 parameters. The source code is available at https://github.com/boyagesmile/DNA-Depth.
CFNet: LiDAR-Camera Registration Using Calibration Flow Network
Apr 24, 2021
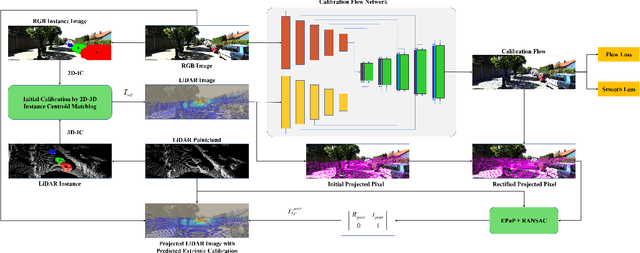

As an essential procedure of data fusion, LiDAR-camera calibration is critical for autonomous vehicles and robot navigation. Most calibration methods rely on hand-crafted features and require significant amounts of extracted features or specific calibration targets. With the development of deep learning (DL) techniques, some attempts take advantage of convolutional neural networks (CNNs) to regress the 6 degrees of freedom (DOF) extrinsic parameters. Nevertheless, the performance of these DL-based methods is reported to be worse than the non-DL methods. This paper proposed an online LiDAR-camera extrinsic calibration algorithm that combines the DL and the geometry methods. We define a two-channel image named calibration flow to illustrate the deviation from the initial projection to the ground truth. EPnP algorithm within the RANdom SAmple Consensus (RANSAC) scheme is applied to estimate the extrinsic parameters with 2D-3D correspondences constructed by the calibration flow. Experiments on KITTI datasets demonstrate that our proposed method is superior to the state-of-the-art methods. Furthermore, we propose a semantic initialization algorithm with the introduction of instance centroids (ICs). The code will be publicly available at https://github.com/LvXudong-HIT/CFNet.
Lidar and Camera Self-Calibration using CostVolume Network
Dec 27, 2020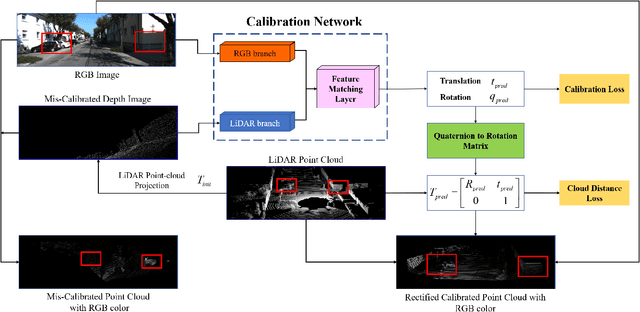
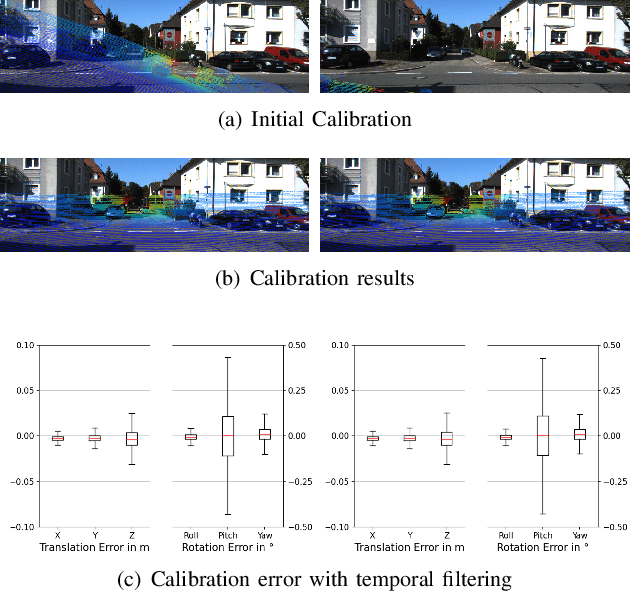


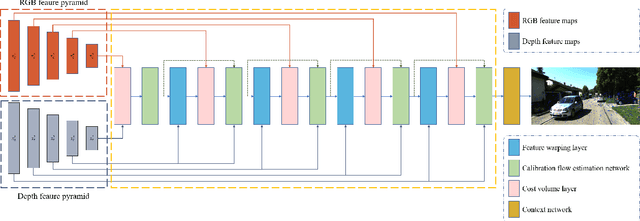
In this paper, we propose a novel online self-calibration approach for Light Detection and Ranging (LiDAR) and camera sensors. Compared to the previous CNN-based methods that concatenate the feature maps of the RGB image and decalibrated depth image, we exploit the cost volume inspired by the PWC-Net for feature matching. Besides the smooth L1-Loss of the predicted extrinsic calibration parameters, an additional point cloud loss is applied. Instead of regress the extrinsic parameters between LiDAR and camera directly, we predict the decalibrated deviation from initial calibration to the ground truth. During inference, the calibration error decreases further with the usage of iterative refinement and the temporal filtering approach. The evaluation results on the KITTI dataset illustrate that our approach outperforms CNN-based state-of-the-art methods in terms of a mean absolute calibration error of 0.297cm in translation and 0.017{\deg} in rotation with miscalibration magnitudes of up to 1.5m and 20{\deg}.
Semantic Flow-guided Motion Removal Method for Robust Mapping
Oct 14, 2020
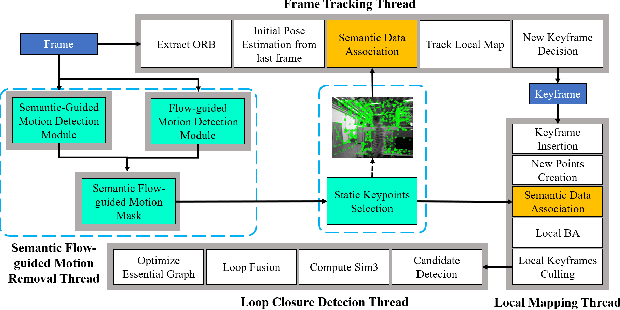


Moving objects in scenes are still a severe challenge for the SLAM system. Many efforts have tried to remove the motion regions in the images by detecting moving objects. In this way, the keypoints belonging to motion regions will be ignored in the later calculations. In this paper, we proposed a novel motion removal method, leveraging semantic information and optical flow to extract motion regions. Different from previous works, we don't predict moving objects or motion regions directly from image sequences. We computed rigid optical flow, synthesized by the depth and pose, and compared it against the estimated optical flow to obtain initial motion regions. Then, we utilized K-means to finetune the motion region masks with instance segmentation masks. The ORB-SLAM2 integrated with the proposed motion removal method achieved the best performance in both indoor and outdoor dynamic environments.