 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Goal-Oriented Reinforcement Learning-Based Path Planning Algorithm for Modular Self-Reconfigurable Satellites
May 04, 2025Modular self-reconfigurable satellites refer to satellite clusters composed of individual modular units capable of altering their configurations. The configuration changes enable the execution of diverse tasks and mission objectives. Existing path planning algorithms for reconfiguration often suffer from high computational complexity, poor generalization capability, and limited support for diverse target configurations. To address these challenges, this paper proposes a goal-oriented reinforcement learning-based path planning algorithm. This algorithm is the first to address the challenge that previous reinforcement learning methods failed to overcome, namely handling multiple target configurations. Moreover, techniques such as Hindsight Experience Replay and Invalid Action Masking are incorporated to overcome the significant obstacles posed by sparse rewards and invalid actions. Based on these designs, our model achieves a 95% and 73% success rate in reaching arbitrary target configurations in a modular satellite cluster composed of four and six units, respectively.
Deep Neighbor Layer Aggregation for Lightweight Self-Supervised Monocular Depth Estimation
Sep 17, 2023With the frequent use of self-supervised monocular depth estimation in robotics and autonomous driving, the model's efficiency is becoming increasingly important. Most current approaches apply much larger and more complex networks to improve the precision of depth estimation. Some researchers incorporated Transformer into self-supervised monocular depth estimation to achieve better performance. However, this method leads to high parameters and high computation. We present a fully convolutional depth estimation network using contextual feature fusion. Compared to UNet++ and HRNet, we use high-resolution and low-resolution features to reserve information on small targets and fast-moving objects instead of long-range fusion. We further promote depth estimation results employing lightweight channel attention based on convolution in the decoder stage. Our method reduces the parameters without sacrificing accuracy. Experiments on the KITTI benchmark show that our method can get better results than many large models, such as Monodepth2, with only 30 parameters. The source code is available at https://github.com/boyagesmile/DNA-Depth.
Rethinking Class Activation Maps for Segmentation: Revealing Semantic Information in Shallow Layers by Reducing Noise
Aug 04, 2023



Class activation maps are widely used for explaining deep neural networks. Due to its ability to highlight regions of interest, it has evolved in recent years as a key step in weakly supervised learning. A major limitation to the performance of the class activation maps is the small spatial resolution of the feature maps in the last layer of the convolutional neural network. Therefore, we expect to generate high-resolution feature maps that result in high-quality semantic information. In this paper, we rethink the properties of semantic information in shallow feature maps. We find that the shallow feature maps still have fine-grained non-discriminative features while mixing considerable non-target noise. Furthermore, we propose a simple gradient-based denoising method to filter the noise by truncating the positive gradient. Our proposed scheme can be easily deployed in other CAM-related methods, facilitating these methods to obtain higher-quality class activation maps. We evaluate the proposed approach through a weakly-supervised semantic segmentation task, and a large number of experiments demonstrate the effectiveness of our approach.
Training Neural Networks for Solving 1-D Optimal Piecewise Linear Approximation
Oct 14, 2021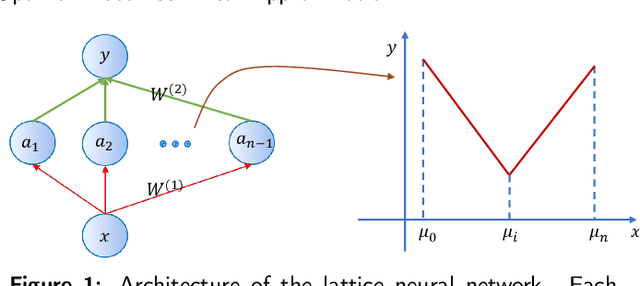
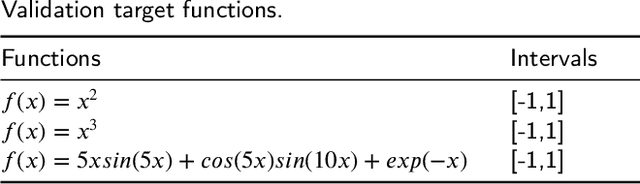
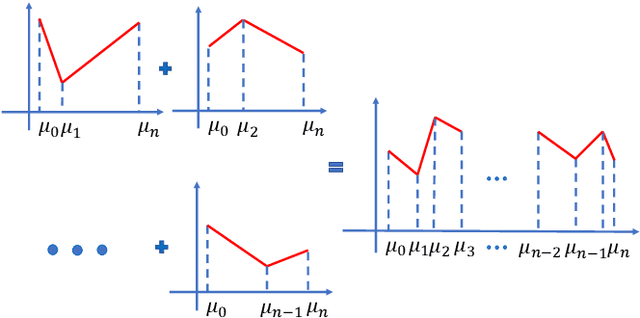
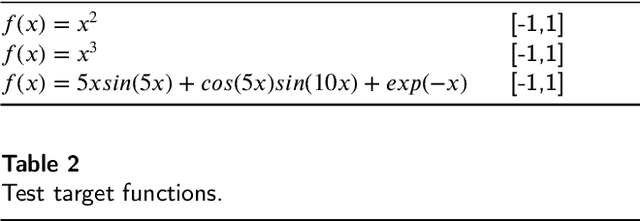
Recently, the interpretability of deep learning has attracted a lot of attention. A plethora of methods have attempted to explain neural networks by feature visualization, saliency maps, model distillation, and so on. However, it is hard for these methods to reveal the intrinsic properties of neural networks. In this work, we studied the 1-D optimal piecewise linear approximation (PWLA) problem, and associated it with a designed neural network, named lattice neural network (LNN). We asked four essential questions as following: (1) What are the characters of the optimal solution of the PWLA problem? (2) Can an LNN converge to the global optimum? (3) Can an LNN converge to the local optimum? (4) Can an LNN solve the PWLA problem? Our main contributions are that we propose the theorems to characterize the optimal solution of the PWLA problem and present the LNN method for solving it. We evaluated the proposed LNNs on approximation tasks, forged an empirical method to improve the performance of LNNs. The experiments verified that our LNN method is competitive with the start-of-the-art method.
How to Explain Neural Networks: A perspective of data space division
May 17, 2021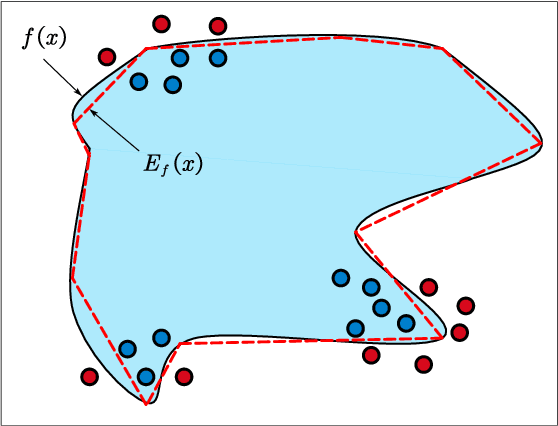
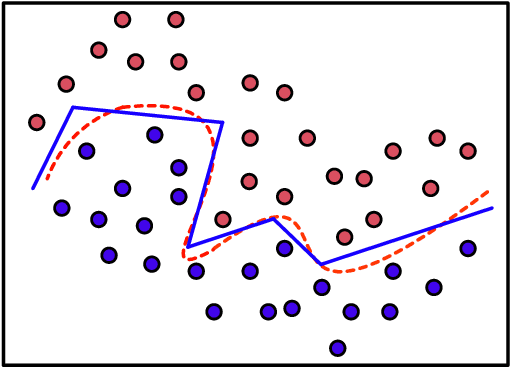
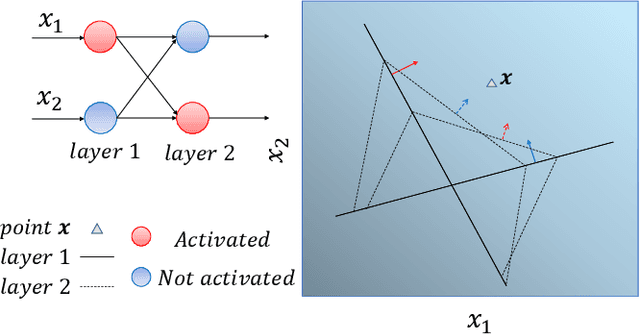
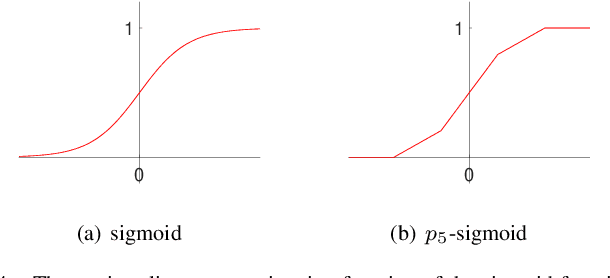
Interpretability of intelligent algorithms represented by deep learning has been yet an open problem. We discuss the shortcomings of the existing explainable method based on the two attributes of explanation, which are called completeness and explicitness. Furthermore, we point out that a model that completely relies on feed-forward mapping is extremely easy to cause inexplicability because it is hard to quantify the relationship between this mapping and the final model. Based on the perspective of the data space division, the principle of complete local interpretable model-agnostic explanations (CLIMEP) is proposed in this paper. To study the classification problems, we further discussed the equivalence of the CLIMEP and the decision boundary. As a matter of fact, it is also difficult to implementation of CLIMEP. To tackle the challenge, motivated by the fact that a fully-connected neural network (FCNN) with piece-wise linear activation functions (PWLs) can partition the input space into several linear regions, we extend this result to arbitrary FCNNs by the strategy of linearizing the activation functions. Applying this technique to solving classification problems, it is the first time that the complete decision boundary of FCNNs has been able to be obtained. Finally, we propose the DecisionNet (DNet), which divides the input space by the hyper-planes of the decision boundary. Hence, each linear interval of the DNet merely contains samples of the same label. Experiments show that the surprising model compression efficiency of the DNet with an arbitrary controlled precision.
CFNet: LiDAR-Camera Registration Using Calibration Flow Network
Apr 24, 2021
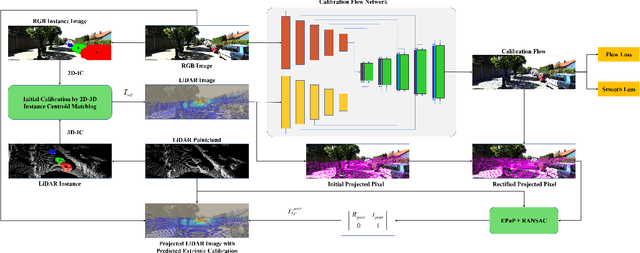

As an essential procedure of data fusion, LiDAR-camera calibration is critical for autonomous vehicles and robot navigation. Most calibration methods rely on hand-crafted features and require significant amounts of extracted features or specific calibration targets. With the development of deep learning (DL) techniques, some attempts take advantage of convolutional neural networks (CNNs) to regress the 6 degrees of freedom (DOF) extrinsic parameters. Nevertheless, the performance of these DL-based methods is reported to be worse than the non-DL methods. This paper proposed an online LiDAR-camera extrinsic calibration algorithm that combines the DL and the geometry methods. We define a two-channel image named calibration flow to illustrate the deviation from the initial projection to the ground truth. EPnP algorithm within the RANdom SAmple Consensus (RANSAC) scheme is applied to estimate the extrinsic parameters with 2D-3D correspondences constructed by the calibration flow. Experiments on KITTI datasets demonstrate that our proposed method is superior to the state-of-the-art methods. Furthermore, we propose a semantic initialization algorithm with the introduction of instance centroids (ICs). The code will be publicly available at https://github.com/LvXudong-HIT/CFNet.
High-quality Low-dose CT Reconstruction Using Convolutional Neural Networks with Spatial and Channel Squeeze and Excitation
Apr 01, 2021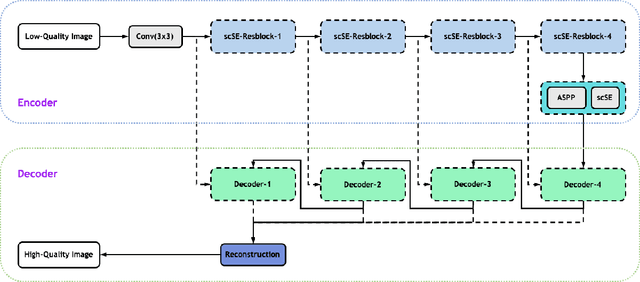
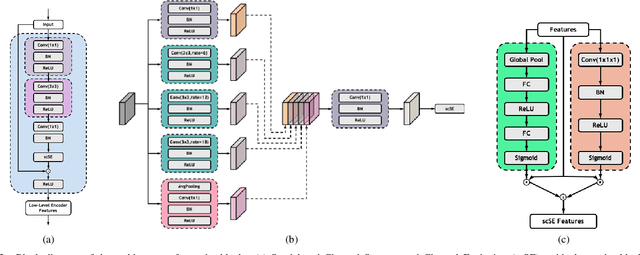
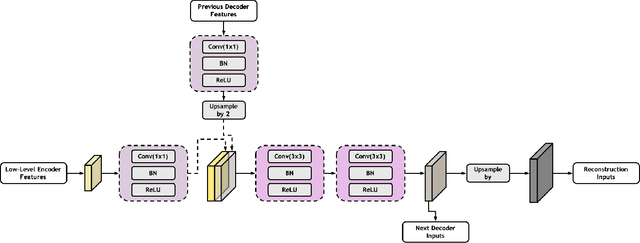
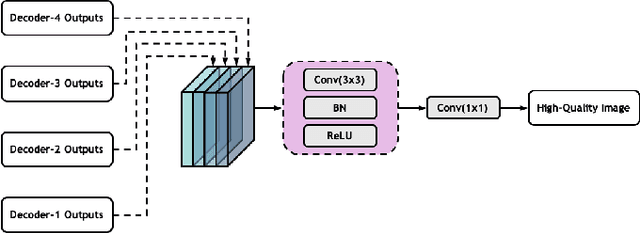
Low-dose computed tomography (CT) allows the reduction of radiation risk in clinical applications at the expense of image quality, which deteriorates the diagnosis accuracy of radiologists. In this work, we present a High-Quality Imaging network (HQINet) for the CT image reconstruction from Low-dose computed tomography (CT) acquisitions. HQINet was a convolutional encoder-decoder architecture, where the encoder was used to extract spatial and temporal information from three contiguous slices while the decoder was used to recover the spacial information of the middle slice. We provide experimental results on the real projection data from low-dose CT Image and Projection Data (LDCT-and-Projection-data), demonstrating that the proposed approach yielded a notable improvement of the performance in terms of image quality, with a rise of 5.5dB in terms of peak signal-to-noise ratio (PSNR) and 0.29 in terms of mutual information (MI).
Lidar and Camera Self-Calibration using CostVolume Network
Dec 27, 2020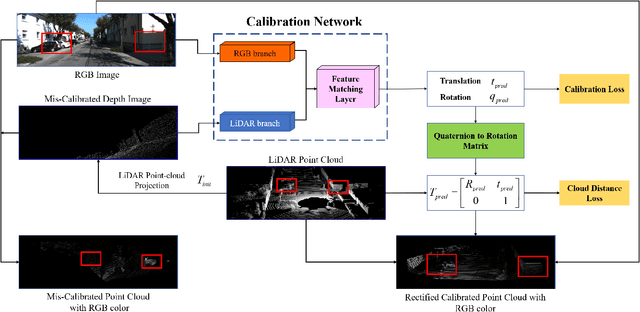
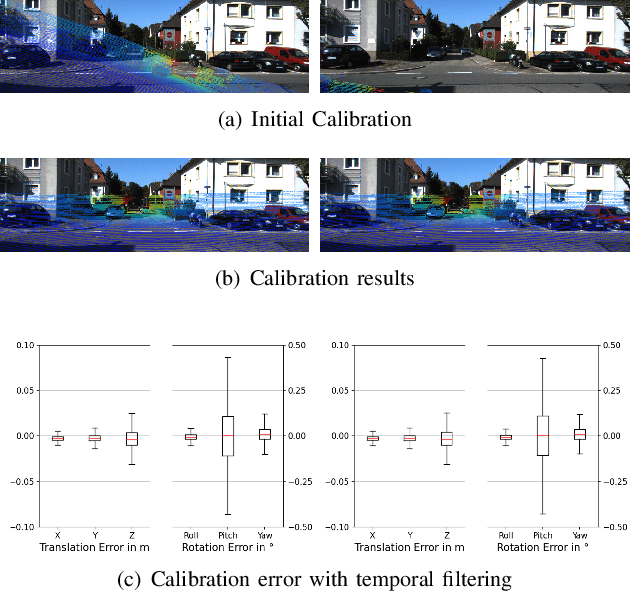


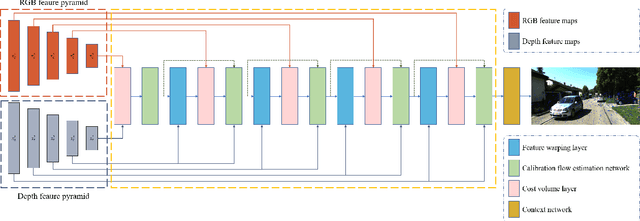
In this paper, we propose a novel online self-calibration approach for Light Detection and Ranging (LiDAR) and camera sensors. Compared to the previous CNN-based methods that concatenate the feature maps of the RGB image and decalibrated depth image, we exploit the cost volume inspired by the PWC-Net for feature matching. Besides the smooth L1-Loss of the predicted extrinsic calibration parameters, an additional point cloud loss is applied. Instead of regress the extrinsic parameters between LiDAR and camera directly, we predict the decalibrated deviation from initial calibration to the ground truth. During inference, the calibration error decreases further with the usage of iterative refinement and the temporal filtering approach. The evaluation results on the KITTI dataset illustrate that our approach outperforms CNN-based state-of-the-art methods in terms of a mean absolute calibration error of 0.297cm in translation and 0.017{\deg} in rotation with miscalibration magnitudes of up to 1.5m and 20{\deg}.
Semantic Flow-guided Motion Removal Method for Robust Mapping
Oct 14, 2020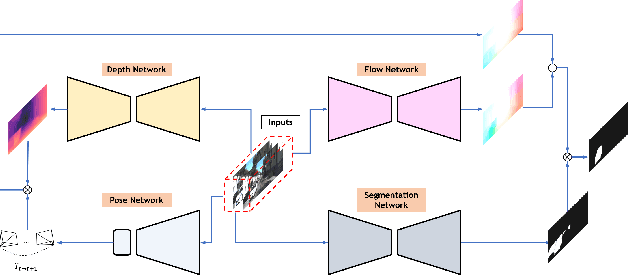
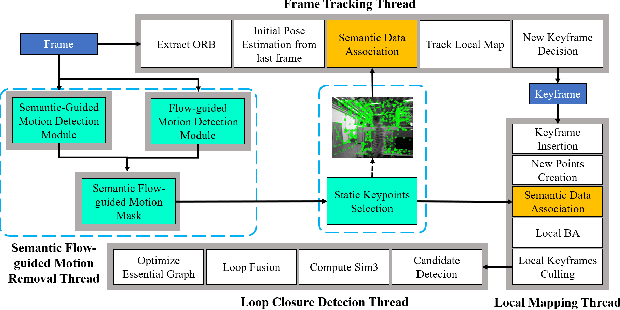


Moving objects in scenes are still a severe challenge for the SLAM system. Many efforts have tried to remove the motion regions in the images by detecting moving objects. In this way, the keypoints belonging to motion regions will be ignored in the later calculations. In this paper, we proposed a novel motion removal method, leveraging semantic information and optical flow to extract motion regions. Different from previous works, we don't predict moving objects or motion regions directly from image sequences. We computed rigid optical flow, synthesized by the depth and pose, and compared it against the estimated optical flow to obtain initial motion regions. Then, we utilized K-means to finetune the motion region masks with instance segmentation masks. The ORB-SLAM2 integrated with the proposed motion removal method achieved the best performance in both indoor and outdoor dynamic environments.