 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Extraction of Audio Classifiers for Speaker Identification
Jul 26, 2022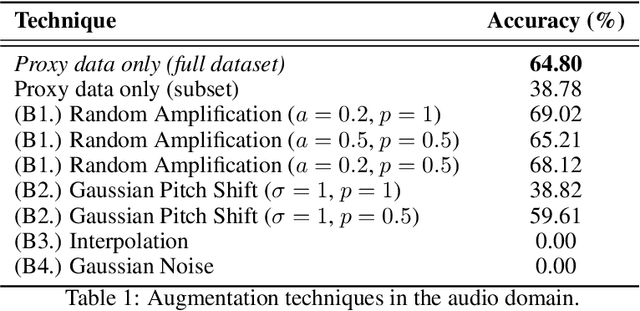



It is perhaps no longer surprising that machine learning models, especially deep neural networks, are particularly vulnerable to attacks. One such vulnerability that has been well studied is model extraction: a phenomenon in which the attacker attempts to steal a victim's model by training a surrogate model to mimic the decision boundaries of the victim model. Previous works have demonstrated the effectiveness of such an attack and its devastating consequences, but much of this work has been done primarily for image and text processing tasks. Our work is the first attempt to perform model extraction on {\em audio classification models}. We are motivated by an attacker whose goal is to mimic the behavior of the victim's model trained to identify a speaker. This is particularly problematic in security-sensitive domains such as biometric authentication. We find that prior model extraction techniques, where the attacker \textit{naively} uses a proxy dataset to attack a potential victim's model, fail. We therefore propose the use of a generative model to create a sufficiently large and diverse pool of synthetic attack queries. We find that our approach is able to extract a victim's model trained on \texttt{LibriSpeech} using queries synthesized with a proxy dataset based off of \texttt{VoxCeleb}; we achieve a test accuracy of 84.41\% with a budget of 3 million queries.
Machine Unlearning
Dec 09, 2019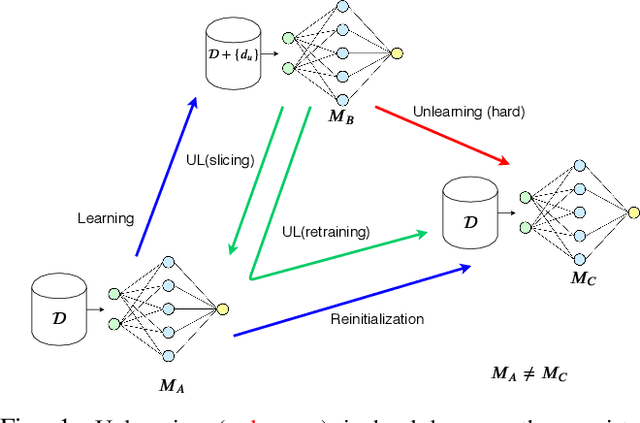
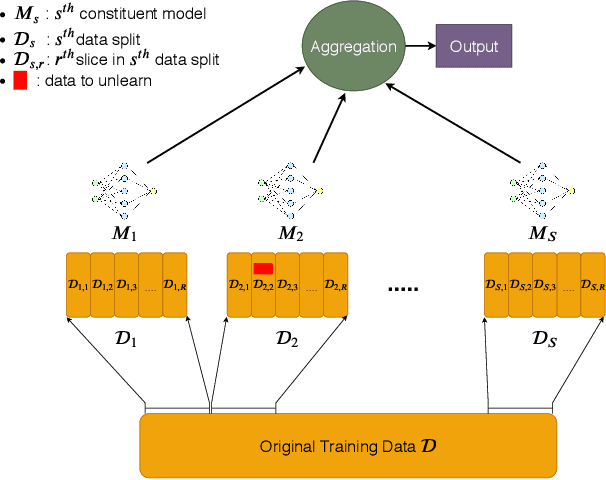
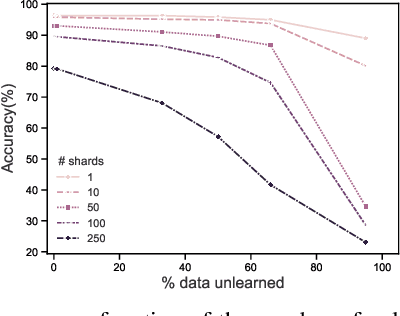
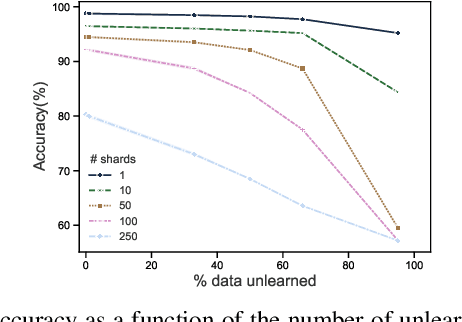
Once users have shared their data online, it is generally difficult for them to revoke access and ask for the data to be deleted. Machine learning (ML) exacerbates this problem because any model trained with said data may have memorized it, putting users at risk of a successful privacy attack exposing their information. Yet, having models unlearn is notoriously difficult. After a data point is removed from a training set, one often resorts to entirely retraining downstream models from scratch. We introduce SISA training, a framework that decreases the number of model parameters affected by an unlearning request and caches intermediate outputs of the training algorithm to limit the number of model updates that need to be computed to have these parameters unlearn. This framework reduces the computational overhead associated with unlearning, even in the worst-case setting where unlearning requests are made uniformly across the training set. In some cases, we may have a prior on the distribution of unlearning requests that will be issued by users. We may take this prior into account to partition and order data accordingly and further decrease overhead from unlearning. Our evaluation spans two datasets from different application domains, with corresponding motivations for unlearning. Under no distributional assumptions, we observe that SISA training improves unlearning for the Purchase dataset by 3.13x, and 1.658x for the SVHN dataset, over retraining from scratch. We also validate how knowledge of the unlearning distribution provides further improvements in retraining time by simulating a scenario where we model unlearning requests that come from users of a commercial product that is available in countries with varying sensitivity to privacy. Our work contributes to practical data governance in machine learning.