 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Extraction of Audio Classifiers for Speaker Identification
Paper and Code
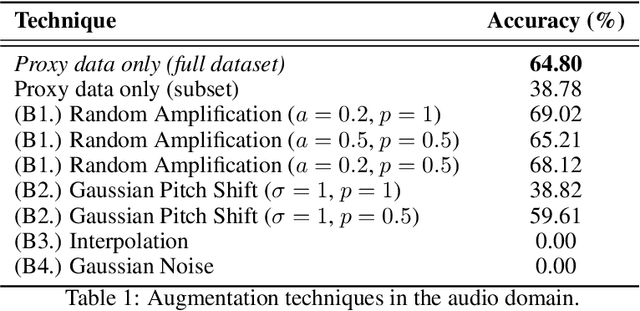



It is perhaps no longer surprising that machine learning models, especially deep neural networks, are particularly vulnerable to attacks. One such vulnerability that has been well studied is model extraction: a phenomenon in which the attacker attempts to steal a victim's model by training a surrogate model to mimic the decision boundaries of the victim model. Previous works have demonstrated the effectiveness of such an attack and its devastating consequences, but much of this work has been done primarily for image and text processing tasks. Our work is the first attempt to perform model extraction on {\em audio classification models}. We are motivated by an attacker whose goal is to mimic the behavior of the victim's model trained to identify a speaker. This is particularly problematic in security-sensitive domains such as biometric authentication. We find that prior model extraction techniques, where the attacker \textit{naively} uses a proxy dataset to attack a potential victim's model, fail. We therefore propose the use of a generative model to create a sufficiently large and diverse pool of synthetic attack queries. We find that our approach is able to extract a victim's model trained on \texttt{LibriSpeech} using queries synthesized with a proxy dataset based off of \texttt{VoxCeleb}; we achieve a test accuracy of 84.41\% with a budget of 3 million queries.