 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot My Deepfake: Towards Plausible Deniability for Machine-Generated Media
Aug 20, 2020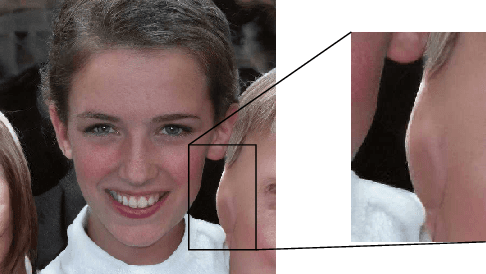


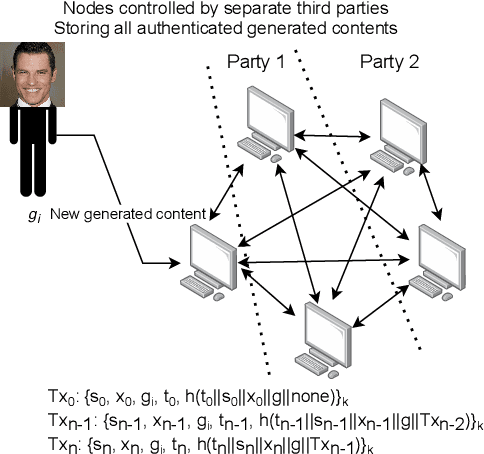
Progress in generative modelling, especially generative adversarial networks, have made it possible to efficiently synthesize and alter media at scale. Malicious individuals now rely on these machine-generated media, or deepfakes, to manipulate social discourse. In order to ensure media authenticity, existing research is focused on deepfake detection. Yet, the very nature of frameworks used for generative modeling suggests that progress towards detecting deepfakes will enable more realistic deepfake generation. Therefore, it comes at no surprise that developers of generative models are under the scrutiny of stakeholders dealing with misinformation campaigns. As such, there is a clear need to develop tools that ensure the transparent use of generative modeling, while minimizing the harm caused by malicious applications. We propose a framework to provide developers of generative models with plausible deniability. We introduce two techniques to provide evidence that a model developer did not produce media that they are being accused of. The first optimizes over the source of entropy of each generative model to probabilistically attribute a deepfake to one of the models. The second involves cryptography to maintain a tamper-proof and publicly-broadcasted record of all legitimate uses of the model. We evaluate our approaches on the seminal example of face synthesis, demonstrating that our first approach achieves 97.62% attribution accuracy, and is less sensitive to perturbations and adversarial examples. In cases where a machine learning approach is unable to provide plausible deniability, we find that involving cryptography as done in our second approach is required. We also discuss the ethical implications of our work, and highlight that a more meaningful legislative framework is required for a more transparent and ethical use of generative modeling.
Machine Unlearning
Dec 09, 2019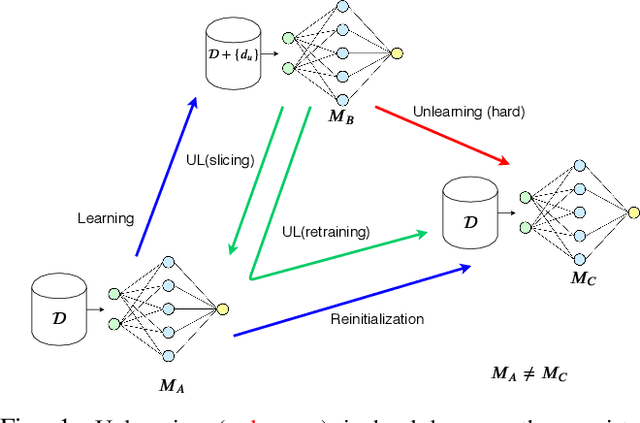
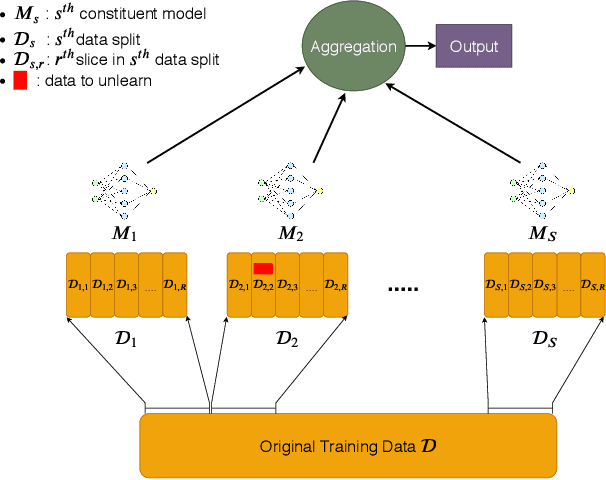
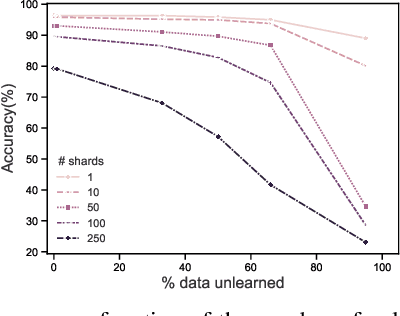
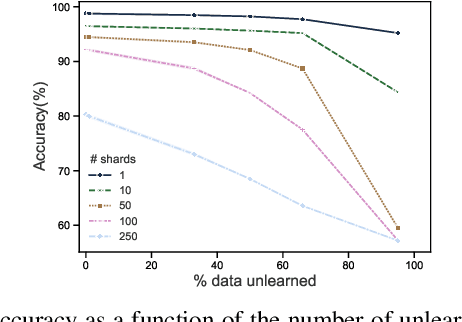
Once users have shared their data online, it is generally difficult for them to revoke access and ask for the data to be deleted. Machine learning (ML) exacerbates this problem because any model trained with said data may have memorized it, putting users at risk of a successful privacy attack exposing their information. Yet, having models unlearn is notoriously difficult. After a data point is removed from a training set, one often resorts to entirely retraining downstream models from scratch. We introduce SISA training, a framework that decreases the number of model parameters affected by an unlearning request and caches intermediate outputs of the training algorithm to limit the number of model updates that need to be computed to have these parameters unlearn. This framework reduces the computational overhead associated with unlearning, even in the worst-case setting where unlearning requests are made uniformly across the training set. In some cases, we may have a prior on the distribution of unlearning requests that will be issued by users. We may take this prior into account to partition and order data accordingly and further decrease overhead from unlearning. Our evaluation spans two datasets from different application domains, with corresponding motivations for unlearning. Under no distributional assumptions, we observe that SISA training improves unlearning for the Purchase dataset by 3.13x, and 1.658x for the SVHN dataset, over retraining from scratch. We also validate how knowledge of the unlearning distribution provides further improvements in retraining time by simulating a scenario where we model unlearning requests that come from users of a commercial product that is available in countries with varying sensitivity to privacy. Our work contributes to practical data governance in machine learning.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019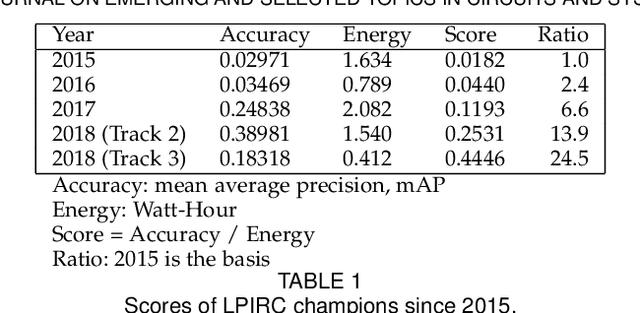
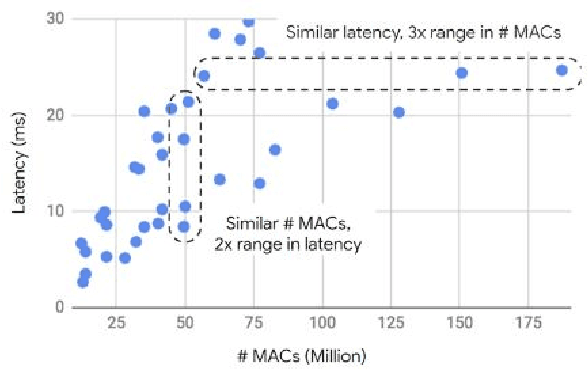
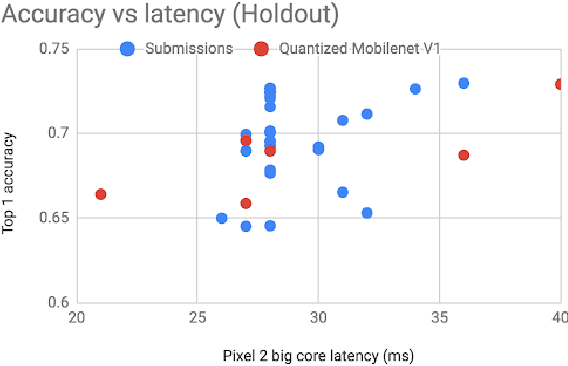
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
2018 Low-Power Image Recognition Challenge
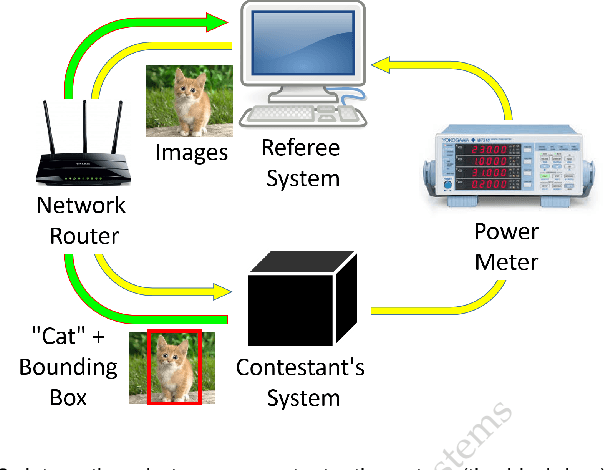
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.