 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Privacy Risk of In-context Learning
Paper and Code
Nov 15, 2024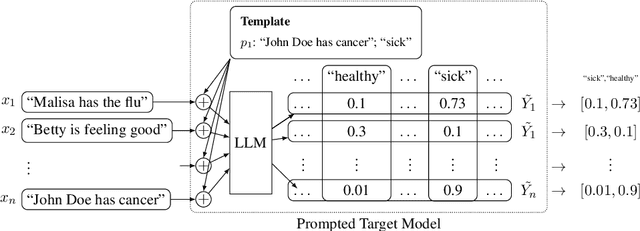
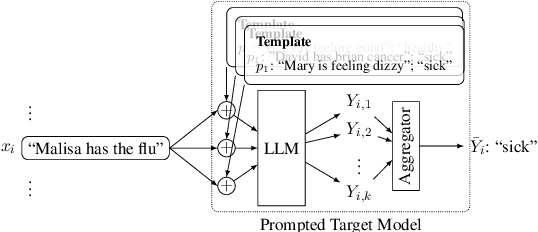

Large language models (LLMs) are excellent few-shot learners. They can perform a wide variety of tasks purely based on natural language prompts provided to them. These prompts contain data of a specific downstream task -- often the private dataset of a party, e.g., a company that wants to leverage the LLM for their purposes. We show that deploying prompted models presents a significant privacy risk for the data used within the prompt by instantiating a highly effective membership inference attack. We also observe that the privacy risk of prompted models exceeds fine-tuned models at the same utility levels. After identifying the model's sensitivity to their prompts -- in the form of a significantly higher prediction confidence on the prompted data -- as a cause for the increased risk, we propose ensembling as a mitigation strategy. By aggregating over multiple different versions of a prompted model, membership inference risk can be decreased.