 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Using Data-Centric Approach for Better Code Representation Learning
Paper and Code

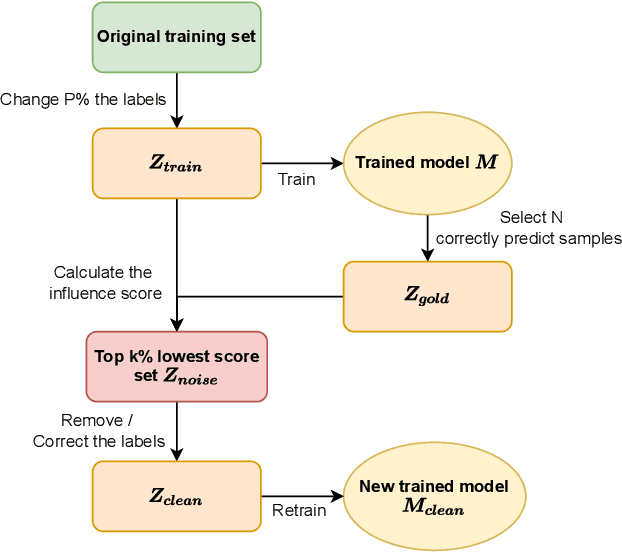
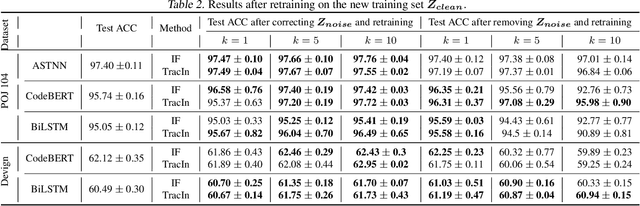
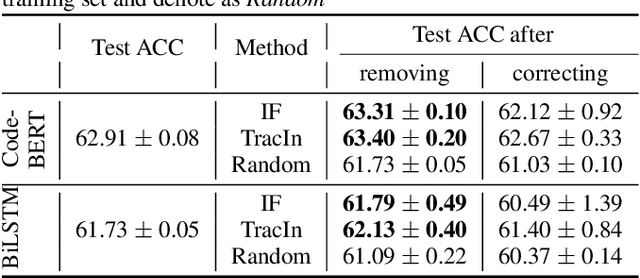
Despite the recent trend of creating source code models and applying them to software engineering tasks, the quality of such models is insufficient for real-world application. In this work, we focus on improving existing code learning models from the data-centric perspective instead of designing new source code models. We shed some light on this direction by using a so-called data-influence method to identify noisy samples of pre-trained code learning models. The data-influence method is to assess the similarity of a target sample to the correct samples to determine whether or not such the target sample is noisy. The results of our evaluation show that data-influence methods can identify noisy samples for the code classification and defection prediction tasks. We envision that the data-centric approach will be a key driver for developing source code models that are useful in practice.