 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Segmentation of Post-Treatment Gliomas Using Simple Approaches: Artificial Sequence Generation and Ensemble Models
Sep 12, 2024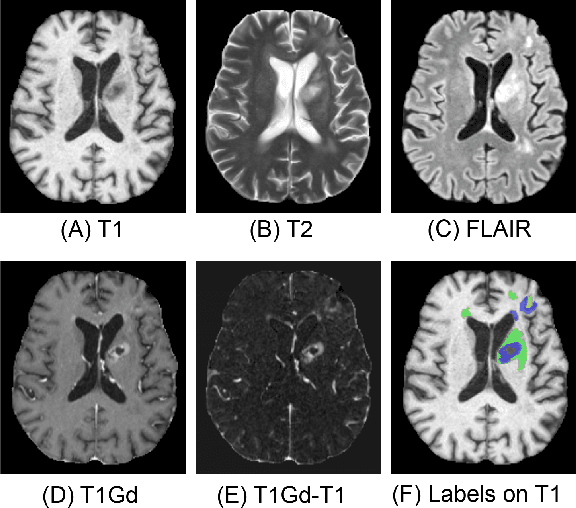
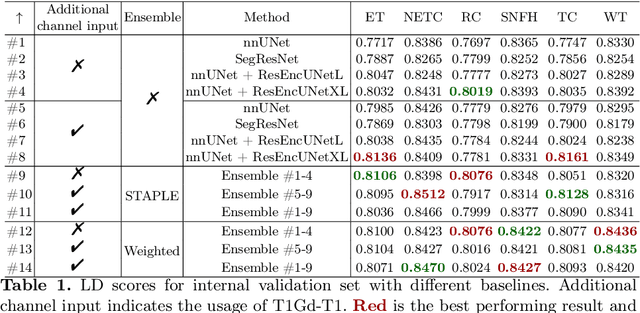
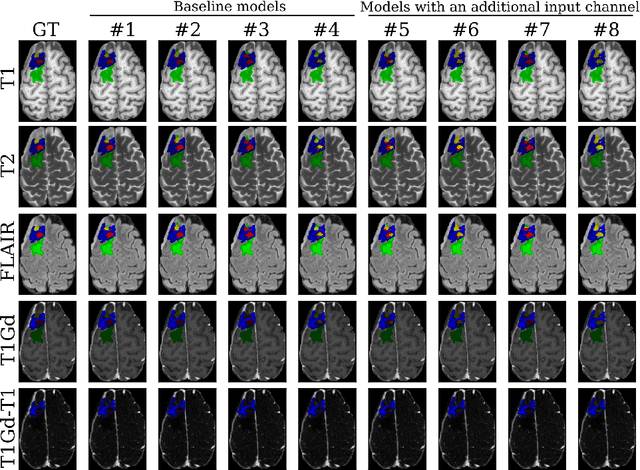
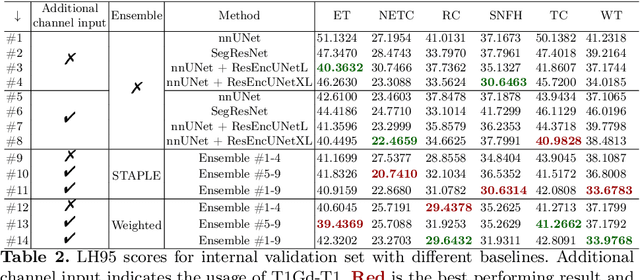
Segmentation is a crucial task in the medical imaging field and is often an important primary step or even a prerequisite to the analysis of medical volumes. Yet treatments such as surgery complicate the accurate delineation of regions of interest. The BraTS Post-Treatment 2024 Challenge published the first public dataset for post-surgery glioma segmentation and addresses the aforementioned issue by fostering the development of automated segmentation tools for glioma in MRI data. In this effort, we propose two straightforward approaches to enhance the segmentation performances of deep learning-based methodologies. First, we incorporate an additional input based on a simple linear combination of the available MRI sequences input, which highlights enhancing tumors. Second, we employ various ensembling methods to weigh the contribution of a battery of models. Our results demonstrate that these approaches significantly improve segmentation performance compared to baseline models, underscoring the effectiveness of these simple approaches in improving medical image segmentation tasks.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021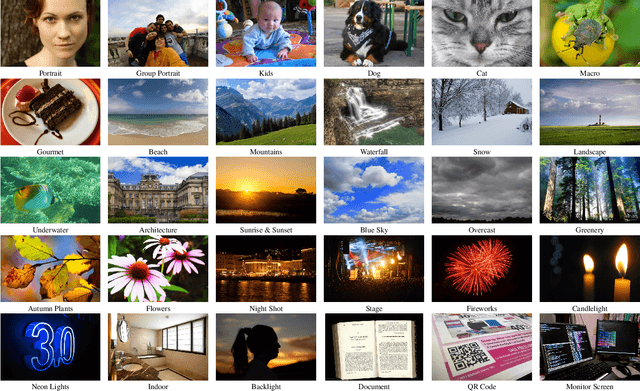
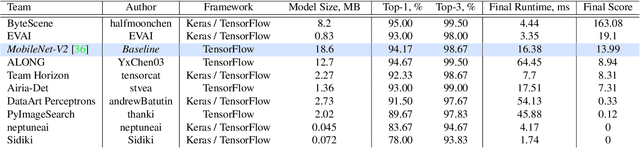
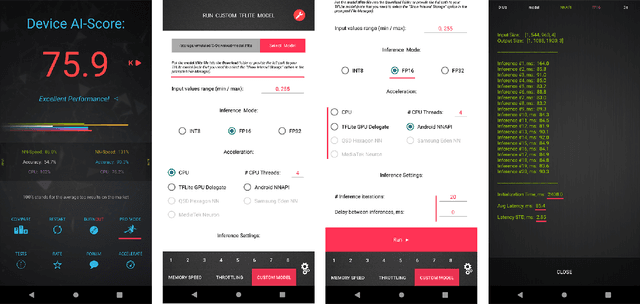

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.