 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion Models with Classifier-Free Gibbs-like Guidance
May 27, 2025Classifier-Free Guidance (CFG) is a widely used technique for improving conditional diffusion models by linearly combining the outputs of conditional and unconditional denoisers. While CFG enhances visual quality and improves alignment with prompts, it often reduces sample diversity, leading to a challenging trade-off between quality and diversity. To address this issue, we make two key contributions. First, CFG generally does not correspond to a well-defined denoising diffusion model (DDM). In particular, contrary to common intuition, CFG does not yield samples from the target distribution associated with the limiting CFG score as the noise level approaches zero -- where the data distribution is tilted by a power $w \gt 1$ of the conditional distribution. We identify the missing component: a R\'enyi divergence term that acts as a repulsive force and is required to correct CFG and render it consistent with a proper DDM. Our analysis shows that this correction term vanishes in the low-noise limit. Second, motivated by this insight, we propose a Gibbs-like sampling procedure to draw samples from the desired tilted distribution. This method starts with an initial sample from the conditional diffusion model without CFG and iteratively refines it, preserving diversity while progressively enhancing sample quality. We evaluate our approach on both image and text-to-audio generation tasks, demonstrating substantial improvements over CFG across all considered metrics. The code is available at https://github.com/yazidjanati/cfgig
NERV++: An Enhanced Implicit Neural Video Representation
Feb 28, 2024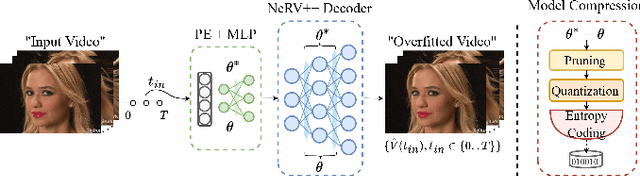
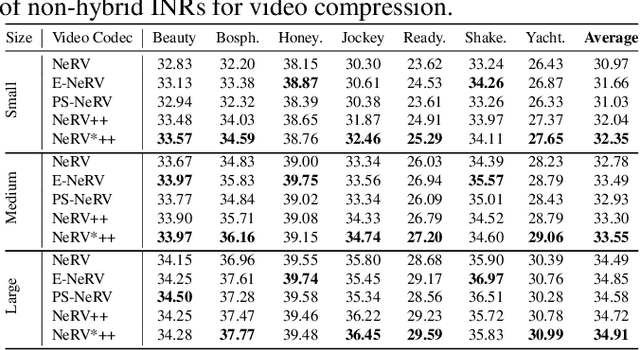
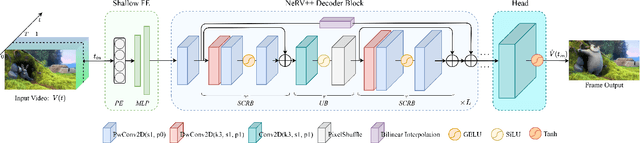
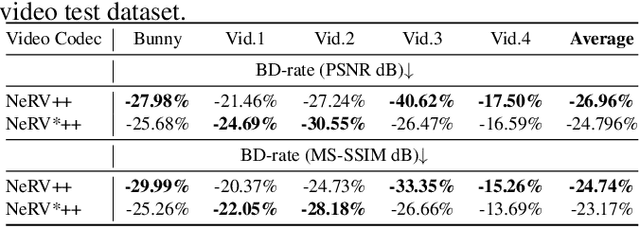
Neural fields, also known as implicit neural representations (INRs), have shown a remarkable capability of representing, generating, and manipulating various data types, allowing for continuous data reconstruction at a low memory footprint. Though promising, INRs applied to video compression still need to improve their rate-distortion performance by a large margin, and require a huge number of parameters and long training iterations to capture high-frequency details, limiting their wider applicability. Resolving this problem remains a quite challenging task, which would make INRs more accessible in compression tasks. We take a step towards resolving these shortcomings by introducing neural representations for videos NeRV++, an enhanced implicit neural video representation, as more straightforward yet effective enhancement over the original NeRV decoder architecture, featuring separable conv2d residual blocks (SCRBs) that sandwiches the upsampling block (UB), and a bilinear interpolation skip layer for improved feature representation. NeRV++ allows videos to be directly represented as a function approximated by a neural network, and significantly enhance the representation capacity beyond current INR-based video codecs. We evaluate our method on UVG, MCL JVC, and Bunny datasets, achieving competitive results for video compression with INRs. This achievement narrows the gap to autoencoder-based video coding, marking a significant stride in INR-based video compression research.
AICT: An Adaptive Image Compression Transformer
Jul 12, 2023



Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Current methods that still rely on ConvNet-based entropy coding are limited in long-range modeling dependencies due to their local connectivity and an increasing number of architectural biases and priors. On the contrary, the proposed ICT can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre/post-processor to accurately extract more compact latent representation while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed adaptive image compression transformer (AICT) framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 12, 2023Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.
Transformer based Models for Unsupervised Anomaly Segmentation in Brain MR Images
Jul 05, 2022
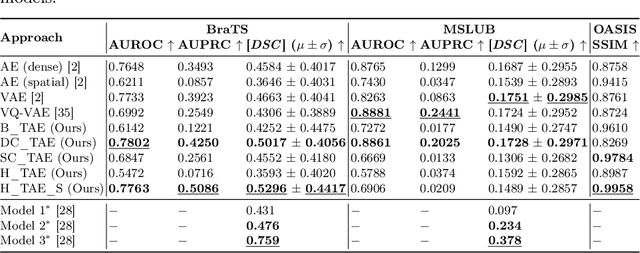


The quality of patient care associated with diagnostic radiology is proportionate to a physician workload. Segmentation is a fundamental limiting precursor to diagnostic and therapeutic procedures. Advances in Machine Learning (ML) aim to increase diagnostic efficiency to replace single application with generalized algorithms. In Unsupervised Anomaly Detection (UAD), Convolutional Neural Network (CNN) based Autoencoders (AEs) and Variational Autoencoders (VAEs) are considered as a de facto approach for reconstruction based anomaly segmentation. Looking for anomalous regions in medical images is one of the main applications that use anomaly segmentation. The restricted receptive field in CNNs limit the CNN to model the global context and hence if the anomalous regions cover parts of the image, the CNN-based AEs are not capable to bring semantic understanding of the image. On the other hand, Vision Transformers (ViTs) have emerged as a competitive alternative to CNNs. It relies on the self-attention mechanism that is capable to relate image patches to each other. To reconstruct a coherent and more realistic image, in this work, we investigate Transformer capabilities in building AEs for reconstruction based UAD task. We focus on anomaly segmentation for Brain Magnetic Resonance Imaging (MRI) and present five Transformer-based models while enabling segmentation performance comparable or superior to State-of-The-Art (SOTA) models. The source code is available on Github https://github.com/ahmedgh970/Transformers_Unsupervised_Anomaly_Segmentation.git