 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReveal of Vision Transformers Robustness against Adversarial Attacks
Paper and Code
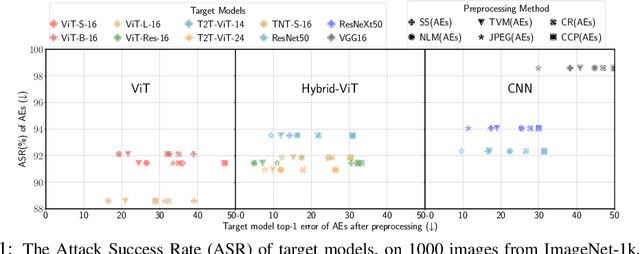
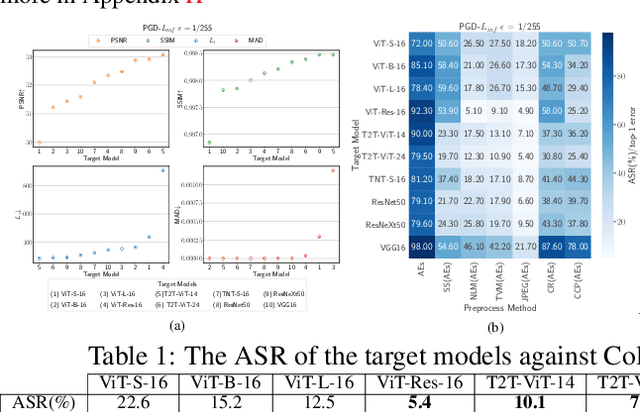
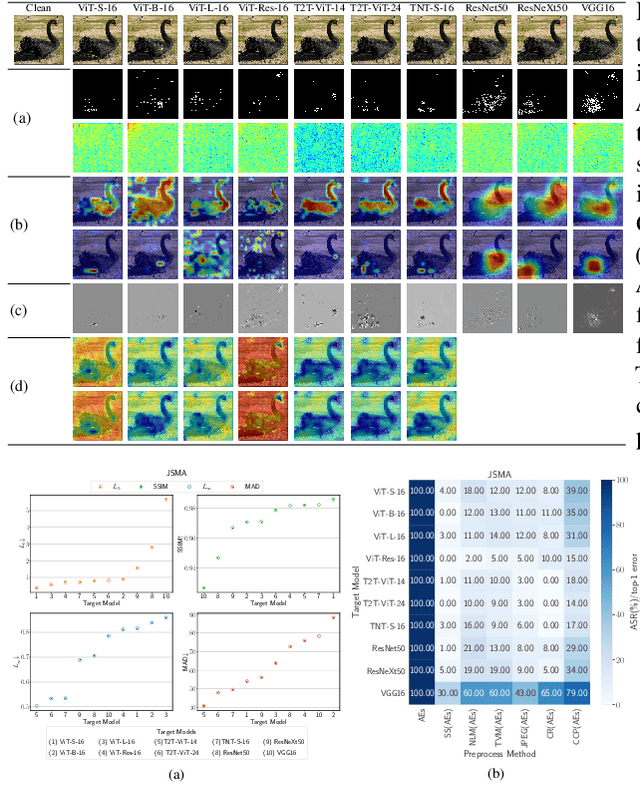
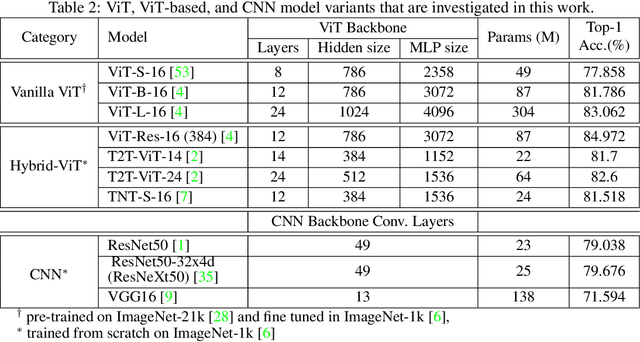
Attention-based networks have achieved state-of-the-art performance in many computer vision tasks, such as image classification. Unlike Convolutional Neural Network (CNN), the major part of the vanilla Vision Transformer (ViT) is the attention block that brings the power of mimicking the global context of the input image. This power is data hunger and hence, the larger the training data the better the performance. To overcome this limitation, many ViT-based networks, or hybrid-ViT, have been proposed to include local context during the training. The robustness of ViTs and its variants against adversarial attacks has not been widely invested in the literature. Some robustness attributes were revealed in few previous works and hence, more insight robustness attributes are yet unrevealed. This work studies the robustness of ViT variants 1) against different $L_p$-based adversarial attacks in comparison with CNNs and 2) under Adversarial Examples (AEs) after applying preprocessing defense methods. To that end, we run a set of experiments on 1000 images from ImageNet-1k and then provide an analysis that reveals that vanilla ViT or hybrid-ViT are more robust than CNNs. For instance, we found that 1) Vanilla ViTs or hybrid-ViTs are more robust than CNNs under $L_0$, $L_1$, $L_2$, $L_\infty$-based, and Color Channel Perturbations (CCP) attacks. 2) Vanilla ViTs are not responding to preprocessing defenses that mainly reduce the high frequency components while, hybrid-ViTs are more responsive to such defense. 3) CCP can be used as a preprocessing defense and larger ViT variants are found to be more responsive than other models. Furthermore, feature maps, attention maps, and Grad-CAM visualization jointly with image quality measures, and perturbations' energy spectrum are provided for an insight understanding of attention-based models.