 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Field Image Coding Using VVC standard and View Synthesis based on Dual Discriminator GAN
Paper and Code
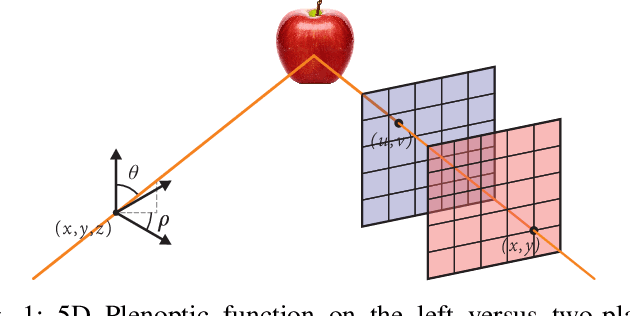



Light field (LF) technology is considered as a promising way for providing a high-quality virtual reality (VR) content. However, such an imaging technology produces a large amount of data requiring efficient LF image compression solutions. In this paper, we propose a LF image coding method based on a view synthesis and view quality enhancement techniques. Instead of transmitting all the LF views, only a sparse set of reference views are encoded and transmitted, while the remaining views are synthesized at the decoder side. The transmitted views are encoded using the versatile video coding (VVC) standard and are used as reference views to synthesize the dropped views. The selection of non-reference dropped views is performed using a rate-distortion optimization based on the VVC temporal scalability. The dropped views are reconstructed using the LF dual discriminator GAN (LF-D2GAN) model. In addition, to ensure that the quality of the views is consistent, at the decoder, a quality enhancement procedure is performed on the reconstructed views allowing smooth navigation across views. Experimental results show that the proposed method provides high coding performance and overcomes the state-of-the-art LF image compression methods by -36.22% in terms of BD-BR and 1.35 dB in BD-PSNR. The web page of this work is available at https://naderbakir79.github.io/LFD2GAN.html.