 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles
Paper and Code
Mar 27, 2019
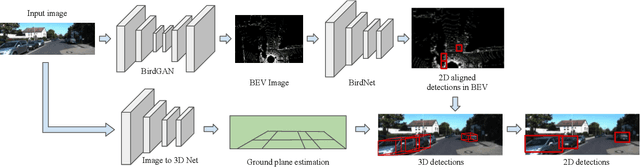
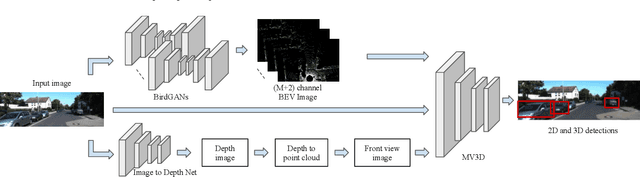

We address the problem of 3D object detection from 2D monocular images in autonomous driving scenarios. We propose to lift the 2D images to 3D representations using learned neural networks and leverage existing networks working directly on 3D to perform 3D object detection and localization. We show that, with carefully designed training mechanism and automatically selected minimally noisy data, such a method is not only feasible, but gives higher results than many methods working on actual 3D inputs acquired from physical sensors. On the challenging KITTI benchmark, we show that our 2D to 3D lifted method outperforms many recent competitive 3D networks while significantly outperforming previous state of the art for 3D detection from monocular images. We also show that a late fusion of the output of the network trained on generated 3D images, with that trained on real 3D images, improves performance. We find the results very interesting and argue that such a method could serve as a highly reliable backup in case of malfunction of expensive 3D sensors, if not potentially making them redundant, at least in the case of low human injury risk autonomous navigation scenarios like warehouse automation.