 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Definition Standard (DDS)
Paper and Code
Jan 07, 2021

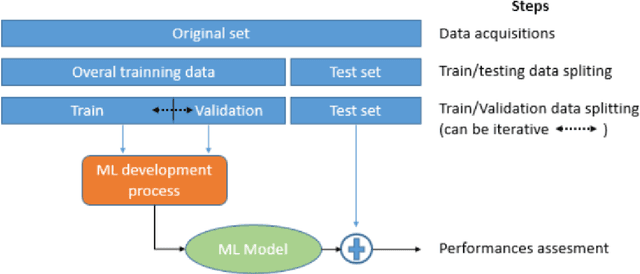
This document gives a set of recommendations to build and manipulate the datasets used to develop and/or validate machine learning models such as deep neural networks. This document is one of the 3 documents defined in [1] to ensure the quality of datasets. This is a work in progress as good practices evolve along with our understanding of machine learning. The document is divided into three main parts. Section 2 addresses the data collection activity. Section 3 gives recommendations about the annotation process. Finally, Section 4 gives recommendations concerning the breakdown between train, validation, and test datasets. In each part, we first define the desired properties at stake, then we explain the objectives targeted to meet the properties, finally we state the recommendations to reach these objectives.