 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Guided Efficient Exploration via Large Language Model in Reinforcement Learning
Sep 26, 2025Real-world decision-making tasks typically occur in complex and open environments, posing significant challenges to reinforcement learning (RL) agents' exploration efficiency and long-horizon planning capabilities. A promising approach is LLM-enhanced RL, which leverages the rich prior knowledge and strong planning capabilities of LLMs to guide RL agents in efficient exploration. However, existing methods mostly rely on frequent and costly LLM invocations and suffer from limited performance due to the semantic mismatch. In this paper, we introduce a Structured Goal-guided Reinforcement Learning (SGRL) method that integrates a structured goal planner and a goal-conditioned action pruner to guide RL agents toward efficient exploration. Specifically, the structured goal planner utilizes LLMs to generate a reusable, structured function for goal generation, in which goals are prioritized. Furthermore, by utilizing LLMs to determine goals' priority weights, it dynamically generates forward-looking goals to guide the agent's policy toward more promising decision-making trajectories. The goal-conditioned action pruner employs an action masking mechanism that filters out actions misaligned with the current goal, thereby constraining the RL agent to select goal-consistent policies. We evaluate the proposed method on Crafter and Craftax-Classic, and experimental results demonstrate that SGRL achieves superior performance compared to existing state-of-the-art methods.
Heterogeneity-Aware Resource Allocation and Topology Design for Hierarchical Federated Edge Learning
Sep 29, 2024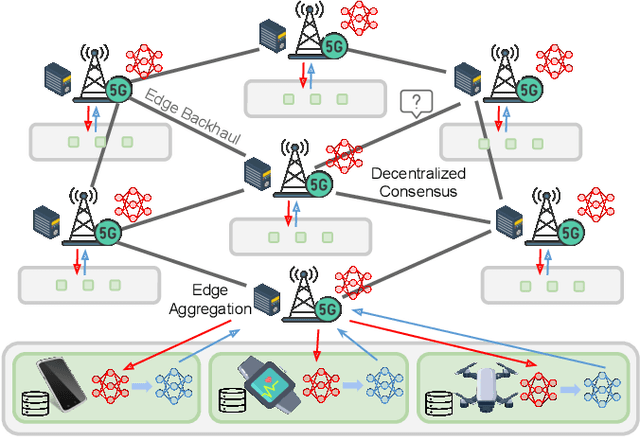
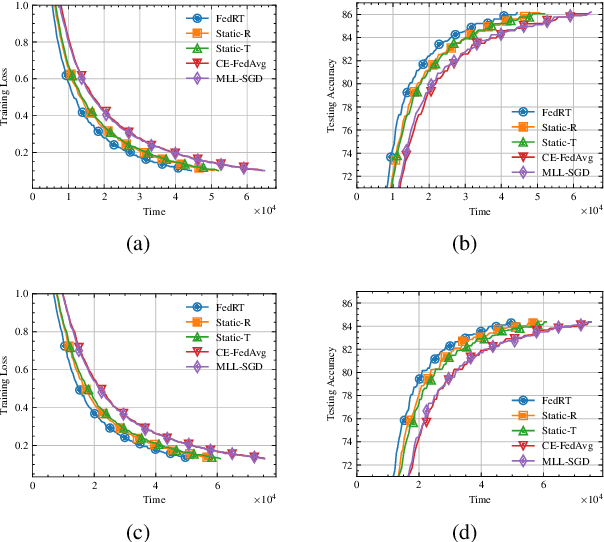
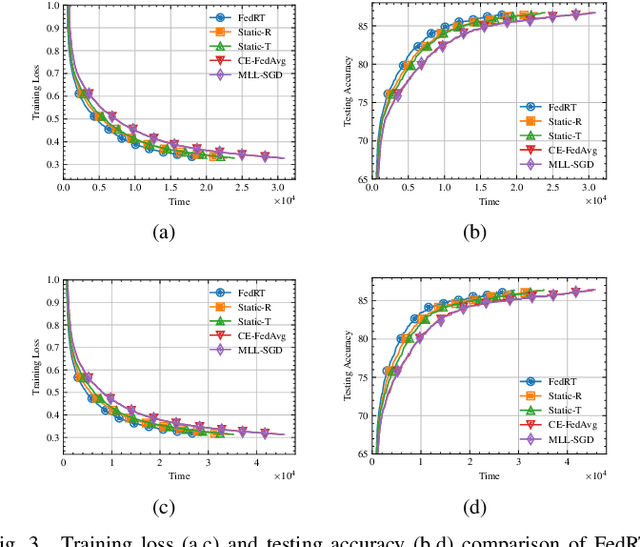
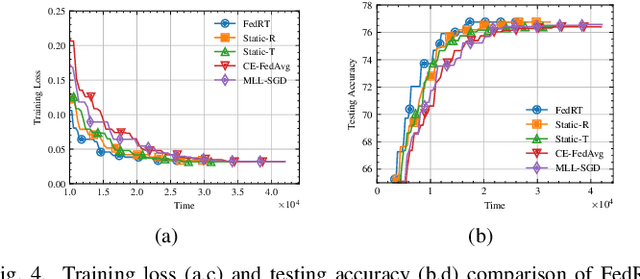
Federated Learning (FL) provides a privacy-preserving framework for training machine learning models on mobile edge devices. Traditional FL algorithms, e.g., FedAvg, impose a heavy communication workload on these devices. To mitigate this issue, Hierarchical Federated Edge Learning (HFEL) has been proposed, leveraging edge servers as intermediaries for model aggregation. Despite its effectiveness, HFEL encounters challenges such as a slow convergence rate and high resource consumption, particularly in the presence of system and data heterogeneity. However, existing works are mainly focused on improving training efficiency for traditional FL, leaving the efficiency of HFEL largely unexplored. In this paper, we consider a two-tier HFEL system, where edge devices are connected to edge servers and edge servers are interconnected through peer-to-peer (P2P) edge backhauls. Our goal is to enhance the training efficiency of the HFEL system through strategic resource allocation and topology design. Specifically, we formulate an optimization problem to minimize the total training latency by allocating the computation and communication resources, as well as adjusting the P2P connections. To ensure convergence under dynamic topologies, we analyze the convergence error bound and introduce a model consensus constraint into the optimization problem. The proposed problem is then decomposed into several subproblems, enabling us to alternatively solve it online. Our method facilitates the efficient implementation of large-scale FL at edge networks under data and system heterogeneity. Comprehensive experiment evaluation on benchmark datasets validates the effectiveness of the proposed method, demonstrating significant reductions in training latency while maintaining the model accuracy compared to various baselines.
One Node Per User: Node-Level Federated Learning for Graph Neural Networks
Sep 29, 2024Graph Neural Networks (GNNs) training often necessitates gathering raw user data on a central server, which raises significant privacy concerns. Federated learning emerges as a solution, enabling collaborative model training without users directly sharing their raw data. However, integrating federated learning with GNNs presents unique challenges, especially when a client represents a graph node and holds merely a single feature vector. In this paper, we propose a novel framework for node-level federated graph learning. Specifically, we decouple the message-passing and feature vector transformation processes of the first GNN layer, allowing them to be executed separately on the user devices and the cloud server. Moreover, we introduce a graph Laplacian term based on the feature vector's latent representation to regulate the user-side model updates. The experiment results on multiple datasets show that our approach achieves better performance compared with baselines.
Heterogeneity-Aware Cooperative Federated Edge Learning with Adaptive Computation and Communication Compression
Sep 06, 2024Motivated by the drawbacks of cloud-based federated learning (FL), cooperative federated edge learning (CFEL) has been proposed to improve efficiency for FL over mobile edge networks, where multiple edge servers collaboratively coordinate the distributed model training across a large number of edge devices. However, CFEL faces critical challenges arising from dynamic and heterogeneous device properties, which slow down the convergence and increase resource consumption. This paper proposes a heterogeneity-aware CFEL scheme called \textit{Heterogeneity-Aware Cooperative Edge-based Federated Averaging} (HCEF) that aims to maximize the model accuracy while minimizing the training time and energy consumption via adaptive computation and communication compression in CFEL. By theoretically analyzing how local update frequency and gradient compression affect the convergence error bound in CFEL, we develop an efficient online control algorithm for HCEF to dynamically determine local update frequencies and compression ratios for heterogeneous devices. Experimental results show that compared with prior schemes, the proposed HCEF scheme can maintain higher model accuracy while reducing training latency and improving energy efficiency simultaneously.
Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation
Sep 26, 2023Text-to-image generative models have garnered immense attention for their ability to produce high-fidelity images from text prompts. Among these, Stable Diffusion distinguishes itself as a leading open-source model in this fast-growing field. However, the intricacies of fine-tuning these models pose multiple challenges from new methodology integration to systematic evaluation. Addressing these issues, this paper introduces LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) [https://github.com/KohakuBlueleaf/LyCORIS], an open-source library that offers a wide selection of fine-tuning methodologies for Stable Diffusion. Furthermore, we present a thorough framework for the systematic assessment of varied fine-tuning techniques. This framework employs a diverse suite of metrics and delves into multiple facets of fine-tuning, including hyperparameter adjustments and the evaluation with different prompt types across various concept categories. Through this comprehensive approach, our work provides essential insights into the nuanced effects of fine-tuning parameters, bridging the gap between state-of-the-art research and practical application.
Scalable and Low-Latency Federated Learning with Cooperative Mobile Edge Networking
May 25, 2022
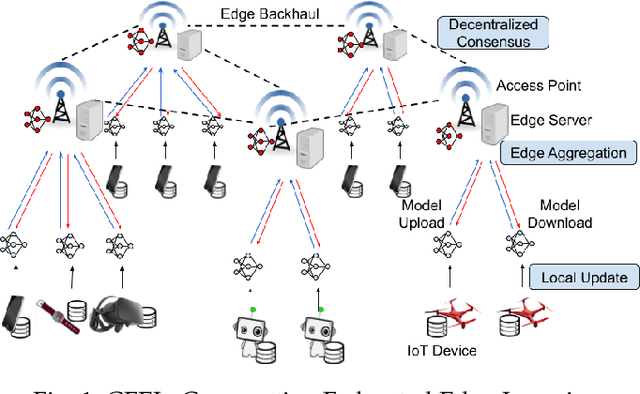

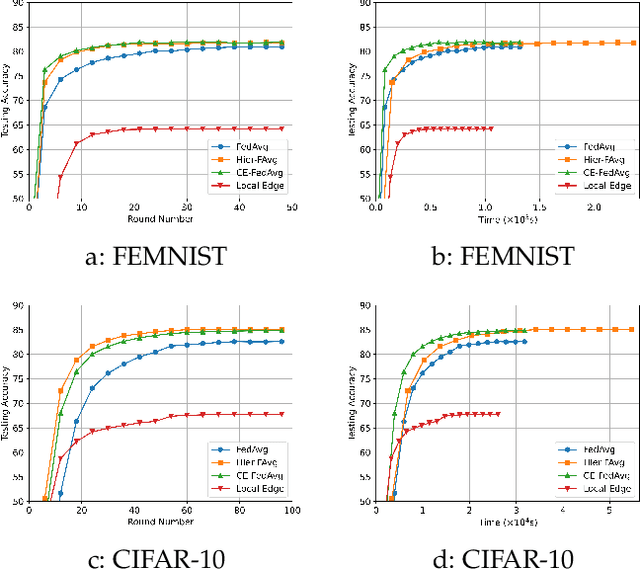
Federated learning (FL) enables collaborative model training without centralizing data. However, the traditional FL framework is cloud-based and suffers from high communication latency. On the other hand, the edge-based FL framework that relies on an edge server co-located with access point for model aggregation has low communication latency but suffers from degraded model accuracy due to the limited coverage of edge server. In light of high-accuracy but high-latency cloud-based FL and low-latency but low-accuracy edge-based FL, this paper proposes a new FL framework based on cooperative mobile edge networking called cooperative federated edge learning (CFEL) to enable both high-accuracy and low-latency distributed intelligence at mobile edge networks. Considering the unique two-tier network architecture of CFEL, a novel federated optimization method dubbed cooperative edge-based federated averaging (CE-FedAvg) is further developed, wherein each edge server both coordinates collaborative model training among the devices within its own coverage and cooperates with other edge servers to learn a shared global model through decentralized consensus. Experimental results based on benchmark datasets show that CFEL can largely speed up the convergence speed and reduce the training time to achieve a target model accuracy compared with prior FL frameworks.
Certified Robustness of Graph Classification against Topology Attack with Randomized Smoothing
Sep 12, 2020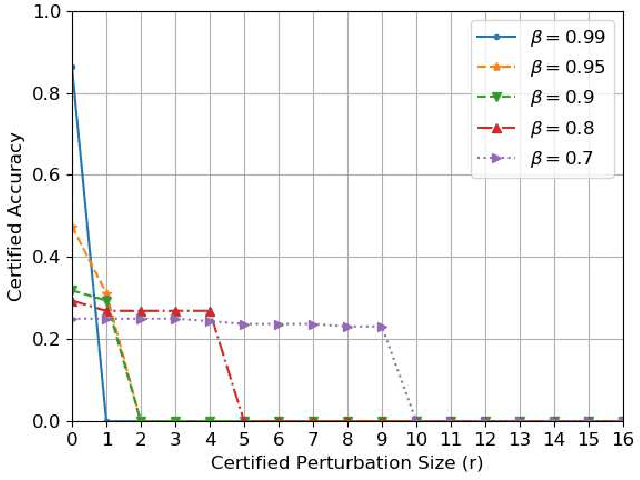
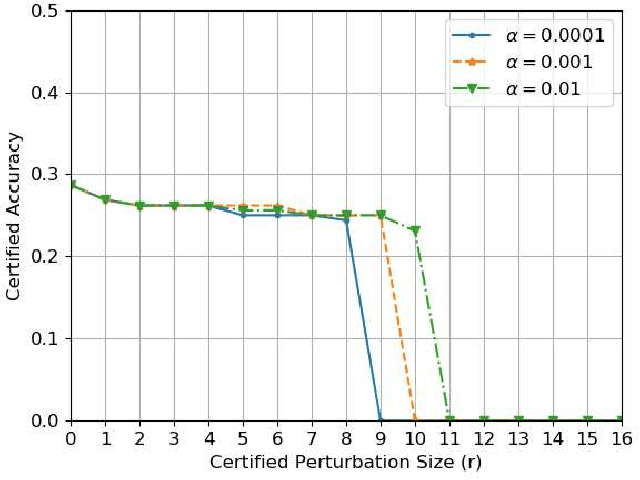
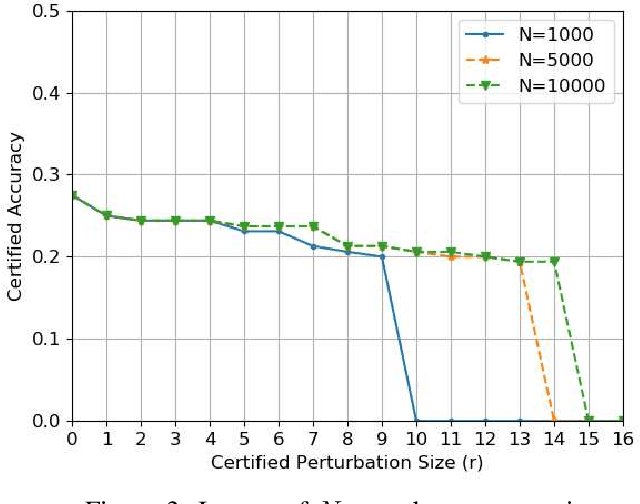
Graph classification has practical applications in diverse fields. Recent studies show that graph-based machine learning models are especially vulnerable to adversarial perturbations due to the non i.i.d nature of graph data. By adding or deleting a small number of edges in the graph, adversaries could greatly change the graph label predicted by a graph classification model. In this work, we propose to build a smoothed graph classification model with certified robustness guarantee. We have proven that the resulting graph classification model would output the same prediction for a graph under $l_0$ bounded adversarial perturbation. We also evaluate the effectiveness of our approach under graph convolutional network (GCN) based multi-class graph classification model.