 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedKRSO: Communication and Memory Efficient Federated Fine-Tuning of Large Language Models
Feb 03, 2026Fine-tuning is essential to adapt general-purpose large language models (LLMs) to domain-specific tasks. As a privacy-preserving framework to leverage decentralized data for collaborative model training, Federated Learning (FL) is gaining popularity in LLM fine-tuning, but remains challenging due to the high cost of transmitting full model parameters and computing full gradients on resource-constrained clients. While Parameter-Efficient Fine-Tuning (PEFT) methods are widely used in FL to reduce communication and memory costs, they often sacrifice model performance compared to FFT. This paper proposes FedKRSO (Federated $K$-Seed Random Subspace Optimization), a novel method that enables communication and memory efficient FFT of LLMs in federated settings. In FedKRSO, clients update the model within a shared set of random low-dimension subspaces generated by the server to save memory usage. Furthermore, instead of transmitting full model parameters in each FL round, clients send only the model update accumulators along the subspaces to the server, enabling efficient global model aggregation and dissemination. By using these strategies, FedKRSO can substantially reduce communication and memory overhead while overcoming the performance limitations of PEFT, closely approximating the performance of federated FFT. The convergence properties of FedKRSO are analyzed rigorously under general FL settings. Extensive experiments on the GLUE benchmark across diverse FL scenarios demonstrate that FedKRSO achieves both superior performance and low communication and memory overhead, paving the way towards on federated LLM fine-tuning at the resource-constrained edge.
One Node Per User: Node-Level Federated Learning for Graph Neural Networks
Sep 29, 2024Graph Neural Networks (GNNs) training often necessitates gathering raw user data on a central server, which raises significant privacy concerns. Federated learning emerges as a solution, enabling collaborative model training without users directly sharing their raw data. However, integrating federated learning with GNNs presents unique challenges, especially when a client represents a graph node and holds merely a single feature vector. In this paper, we propose a novel framework for node-level federated graph learning. Specifically, we decouple the message-passing and feature vector transformation processes of the first GNN layer, allowing them to be executed separately on the user devices and the cloud server. Moreover, we introduce a graph Laplacian term based on the feature vector's latent representation to regulate the user-side model updates. The experiment results on multiple datasets show that our approach achieves better performance compared with baselines.
Heterogeneity-Aware Resource Allocation and Topology Design for Hierarchical Federated Edge Learning
Sep 29, 2024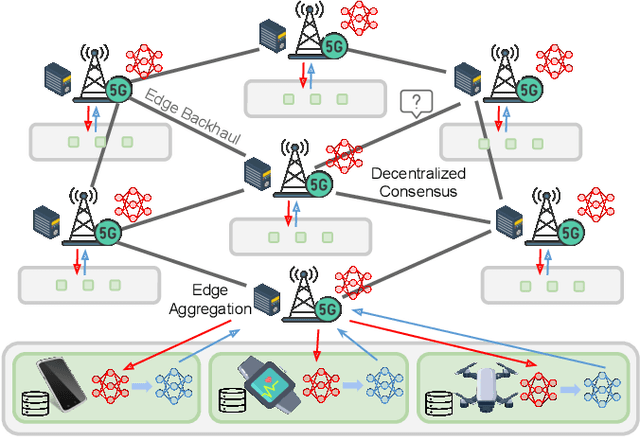
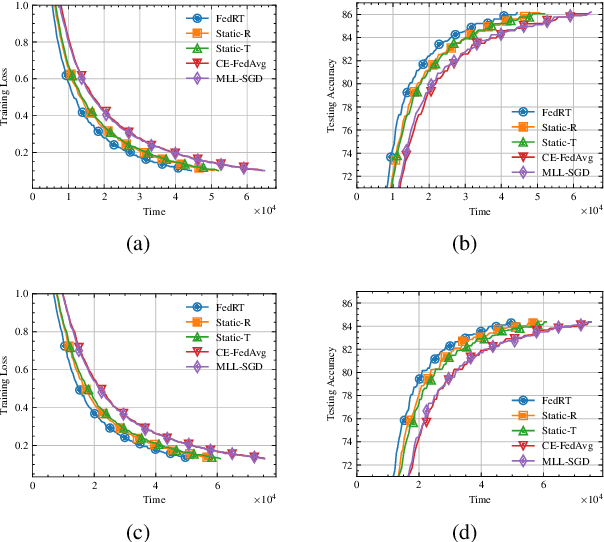
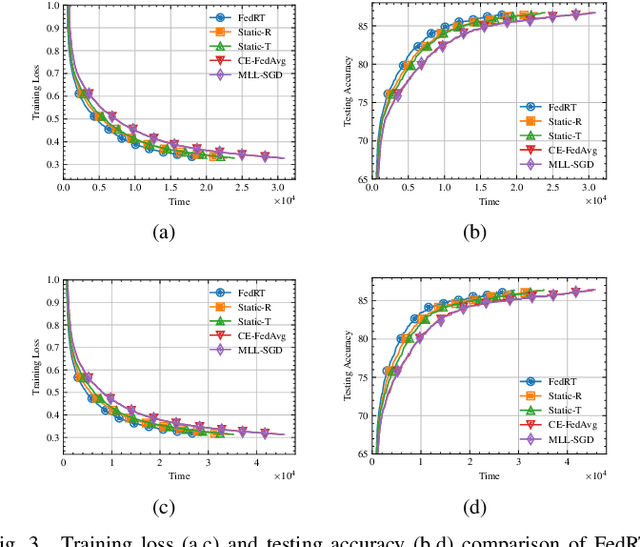
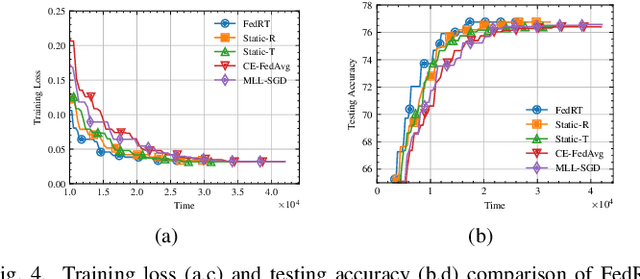
Federated Learning (FL) provides a privacy-preserving framework for training machine learning models on mobile edge devices. Traditional FL algorithms, e.g., FedAvg, impose a heavy communication workload on these devices. To mitigate this issue, Hierarchical Federated Edge Learning (HFEL) has been proposed, leveraging edge servers as intermediaries for model aggregation. Despite its effectiveness, HFEL encounters challenges such as a slow convergence rate and high resource consumption, particularly in the presence of system and data heterogeneity. However, existing works are mainly focused on improving training efficiency for traditional FL, leaving the efficiency of HFEL largely unexplored. In this paper, we consider a two-tier HFEL system, where edge devices are connected to edge servers and edge servers are interconnected through peer-to-peer (P2P) edge backhauls. Our goal is to enhance the training efficiency of the HFEL system through strategic resource allocation and topology design. Specifically, we formulate an optimization problem to minimize the total training latency by allocating the computation and communication resources, as well as adjusting the P2P connections. To ensure convergence under dynamic topologies, we analyze the convergence error bound and introduce a model consensus constraint into the optimization problem. The proposed problem is then decomposed into several subproblems, enabling us to alternatively solve it online. Our method facilitates the efficient implementation of large-scale FL at edge networks under data and system heterogeneity. Comprehensive experiment evaluation on benchmark datasets validates the effectiveness of the proposed method, demonstrating significant reductions in training latency while maintaining the model accuracy compared to various baselines.
Heterogeneity-Aware Cooperative Federated Edge Learning with Adaptive Computation and Communication Compression
Sep 06, 2024Motivated by the drawbacks of cloud-based federated learning (FL), cooperative federated edge learning (CFEL) has been proposed to improve efficiency for FL over mobile edge networks, where multiple edge servers collaboratively coordinate the distributed model training across a large number of edge devices. However, CFEL faces critical challenges arising from dynamic and heterogeneous device properties, which slow down the convergence and increase resource consumption. This paper proposes a heterogeneity-aware CFEL scheme called \textit{Heterogeneity-Aware Cooperative Edge-based Federated Averaging} (HCEF) that aims to maximize the model accuracy while minimizing the training time and energy consumption via adaptive computation and communication compression in CFEL. By theoretically analyzing how local update frequency and gradient compression affect the convergence error bound in CFEL, we develop an efficient online control algorithm for HCEF to dynamically determine local update frequencies and compression ratios for heterogeneous devices. Experimental results show that compared with prior schemes, the proposed HCEF scheme can maintain higher model accuracy while reducing training latency and improving energy efficiency simultaneously.
Quantum-Assisted Joint Caching and Power Allocation for Integrated Satellite-Terrestrial Networks
Dec 22, 2023Low earth orbit (LEO) satellite network can complement terrestrial networks for achieving global wireless coverage and improving delay-sensitive Internet services. This paper proposes an integrated satellite-terrestrial network (ISTN) architecture to provide ground users with seamless and reliable content delivery services. For optimal service provisioning in this architecture, we formulate an optimization model to maximize the network throughput by jointly optimizing content delivery policy, cache placement, and transmission power allocation. The resulting optimization model is a large-scale mixed-integer nonlinear program (MINLP) that is intractable for classical computer solvers. Inspired by quantum computing techniques, we propose a hybrid quantum-classical generalized Benders' decomposition (HQCGBD) algorithm to address this challenge. Specifically, we first exploit the generalized Benders' decomposition (GBD) to decompose the problem into a master problem and a subproblem and then leverage the state-of-art quantum annealer to solve the challenging master problem.
Communication and Energy Efficient Wireless Federated Learning with Intrinsic Privacy
Apr 15, 2023Federated Learning (FL) is a collaborative learning framework that enables edge devices to collaboratively learn a global model while keeping raw data locally. Although FL avoids leaking direct information from local datasets, sensitive information can still be inferred from the shared models. To address the privacy issue in FL, differential privacy (DP) mechanisms are leveraged to provide formal privacy guarantee. However, when deploying FL at the wireless edge with over-the-air computation, ensuring client-level DP faces significant challenges. In this paper, we propose a novel wireless FL scheme called private federated edge learning with sparsification (PFELS) to provide client-level DP guarantee with intrinsic channel noise while reducing communication and energy overhead and improving model accuracy. The key idea of PFELS is for each device to first compress its model update and then adaptively design the transmit power of the compressed model update according to the wireless channel status without any artificial noise addition. We provide a privacy analysis for PFELS and prove the convergence of PFELS under general non-convex and non-IID settings. Experimental results show that compared with prior work, PFELS can improve the accuracy with the same DP guarantee and save communication and energy costs simultaneously.
Scalable and Low-Latency Federated Learning with Cooperative Mobile Edge Networking
May 25, 2022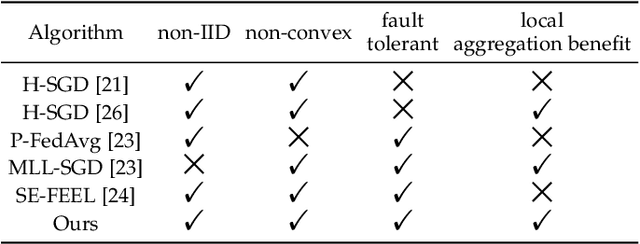
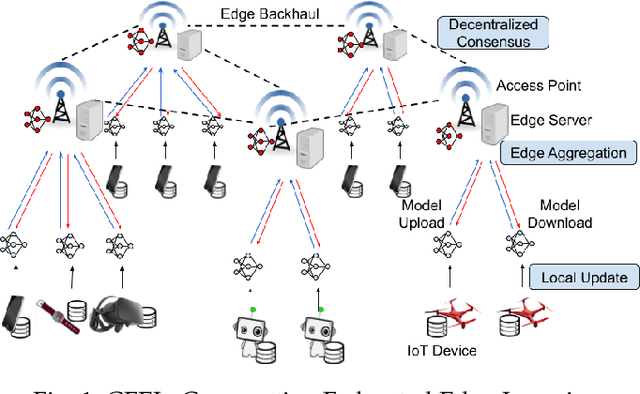

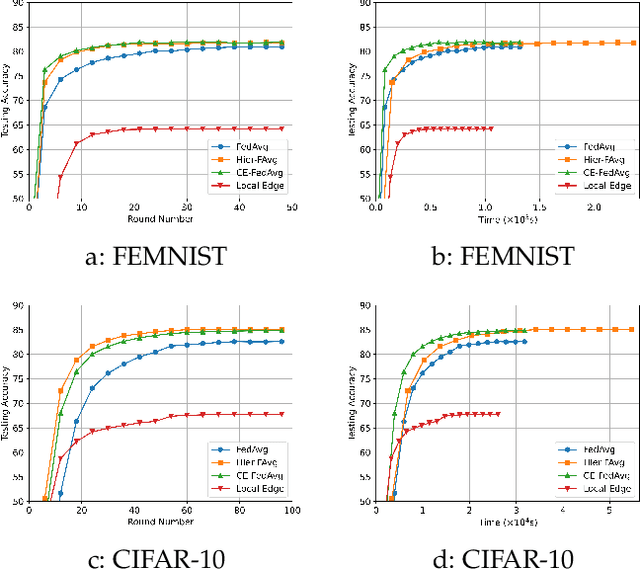
Federated learning (FL) enables collaborative model training without centralizing data. However, the traditional FL framework is cloud-based and suffers from high communication latency. On the other hand, the edge-based FL framework that relies on an edge server co-located with access point for model aggregation has low communication latency but suffers from degraded model accuracy due to the limited coverage of edge server. In light of high-accuracy but high-latency cloud-based FL and low-latency but low-accuracy edge-based FL, this paper proposes a new FL framework based on cooperative mobile edge networking called cooperative federated edge learning (CFEL) to enable both high-accuracy and low-latency distributed intelligence at mobile edge networks. Considering the unique two-tier network architecture of CFEL, a novel federated optimization method dubbed cooperative edge-based federated averaging (CE-FedAvg) is further developed, wherein each edge server both coordinates collaborative model training among the devices within its own coverage and cooperates with other edge servers to learn a shared global model through decentralized consensus. Experimental results based on benchmark datasets show that CFEL can largely speed up the convergence speed and reduce the training time to achieve a target model accuracy compared with prior FL frameworks.
Federated Learning with Sparsified Model Perturbation: Improving Accuracy under Client-Level Differential Privacy
Feb 15, 2022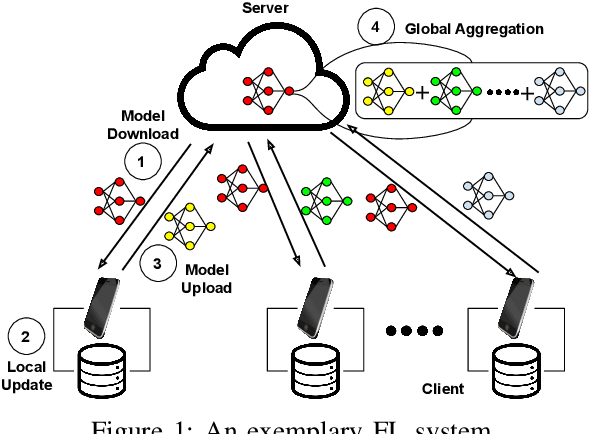
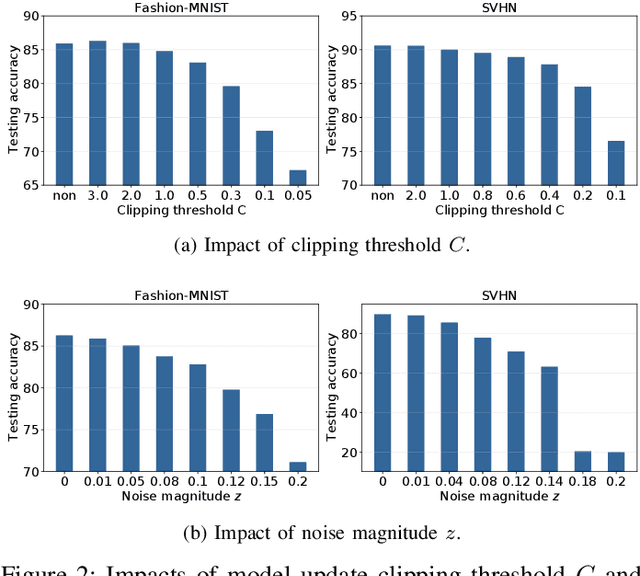
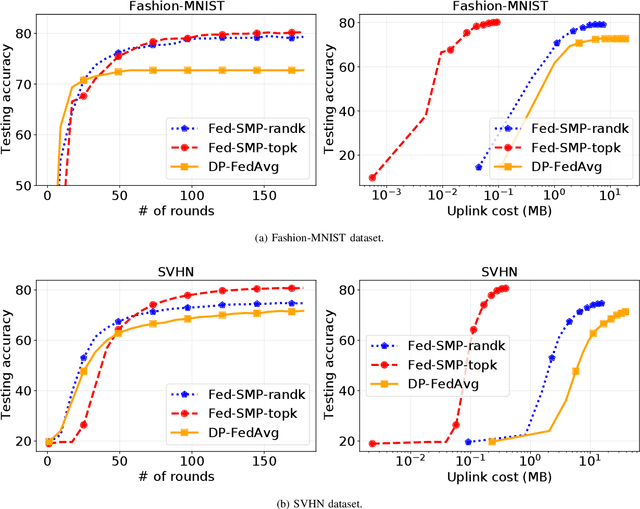
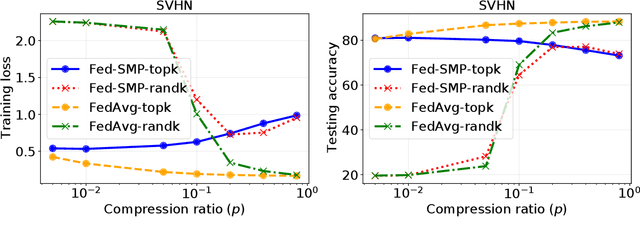
Federated learning (FL) that enables distributed clients to collaboratively learn a shared statistical model while keeping their training data locally has received great attention recently and can improve privacy and communication efficiency in comparison with traditional centralized machine learning paradigm. However, sensitive information about the training data can still be inferred from model updates shared in FL. Differential privacy (DP) is the state-of-the-art technique to defend against those attacks. The key challenge to achieve DP in FL lies in the adverse impact of DP noise on model accuracy, particularly for deep learning models with large numbers of model parameters. This paper develops a novel differentially-private FL scheme named Fed-SMP that provides client-level DP guarantee while maintaining high model accuracy. To mitigate the impact of privacy protection on model accuracy, Fed-SMP leverages a new technique called Sparsified Model Perturbation (SMP), where local models are sparsified first before being perturbed with additive Gaussian noise. Two sparsification strategies are considered in Fed-SMP: random sparsification and top-$k$ sparsification. We also apply R{\'e}nyi differential privacy to providing a tight analysis for the end-to-end DP guarantee of Fed-SMP and prove the convergence of Fed-SMP with general loss functions. Extensive experiments on real-world datasets are conducted to demonstrate the effectiveness of Fed-SMP in largely improving model accuracy with the same level of DP guarantee and saving communication cost simultaneously.
Sparsified Privacy-Masking for Communication-Efficient and Privacy-Preserving Federated Learning
Aug 01, 2020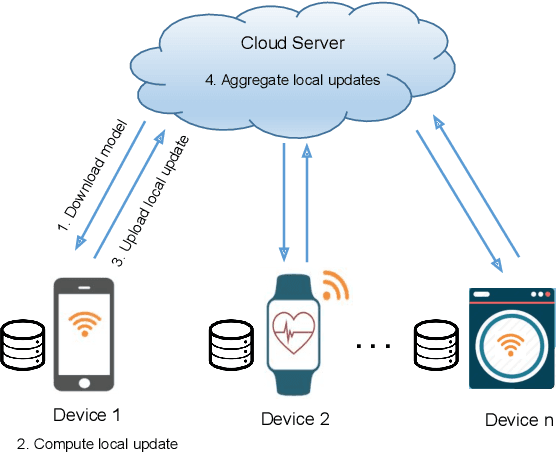
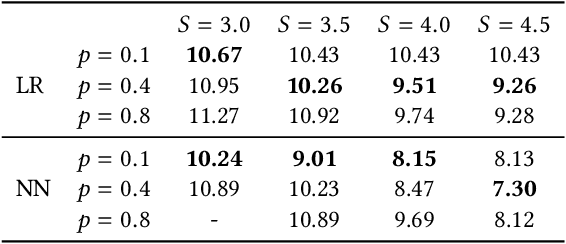
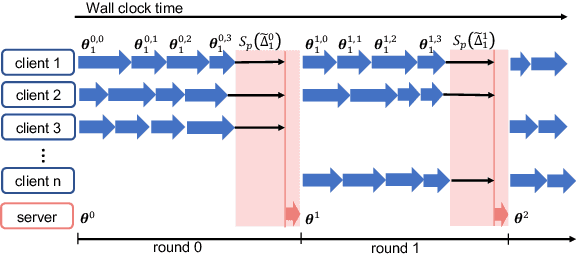
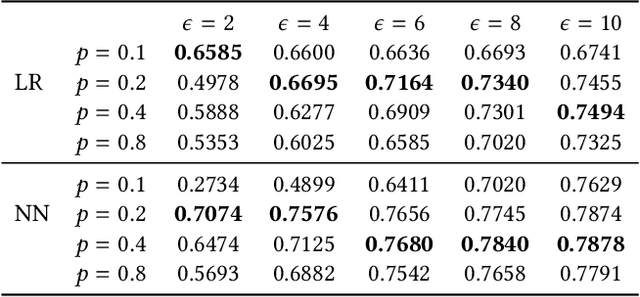
Federated learning has received significant interests recently due to its capability of learning a shared machine learning model across smart devices without accessing their private data in the era of Internet of things. This paper jointly considers two critical issues of federated learning -- data privacy and communication efficiency -- and develops a communication-efficient and differentially-private federated learning scheme called CPFed. The main challenge in addressing both issues together lies in the fact that data compression techniques often lead to an increased number of training iterations required for achieving some desired training loss due to the compression errors, while the differential privacy guarantee usually deteriorates with respect to the number of training iterations. To reconcile this dilemma, we propose to use sparsified privacy-masking that first adds random noise to the model update and then applies unbiased random sparsifier before uploading the model update at each device in federated learning. By using sparsified privacy-masking, our proposed CPFed scheme can achieve high communication efficiency and strong data privacy guarantee at the same time while preserving model accuracy. We provide an explict end-to-end privacy guarantee of CPFed using zero-concentrated differential privacy and give its theoretical convergence rates for both convex and non-convex models. Through extensive numerical experiments on real-world datasets, we demonstrate the effectiveness and efficiency of our proposed method.
CPFed: Communication-Efficient and Privacy-Preserving Federated Learning
Mar 30, 2020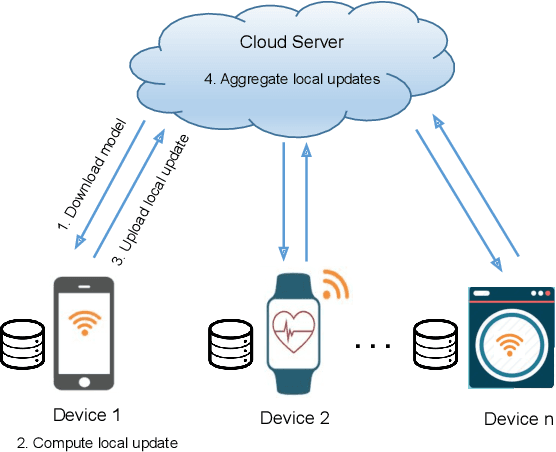
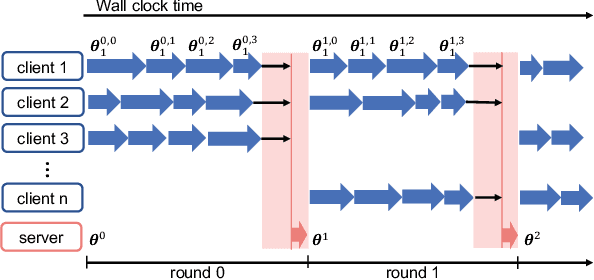
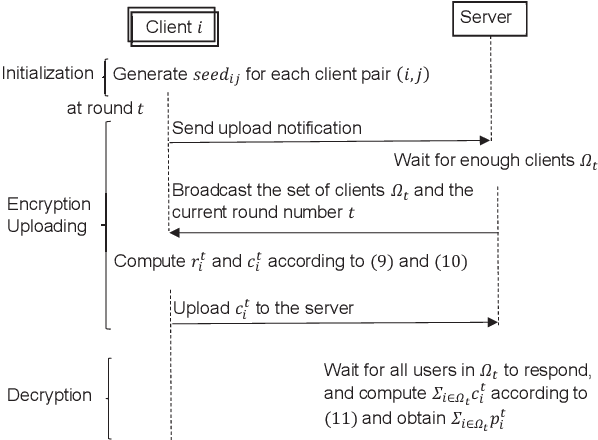
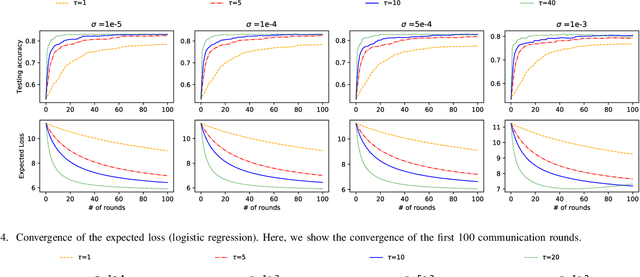
Federated learning is a machine learning setting where a set of edge devices iteratively train a model under the orchestration of a central server, while keeping all data locally on edge devices. In each iteration of federated learning, edge devices perform computation with their local data, and the local computation results are then uploaded to the server for model update. During this process, the challenges of privacy leakage and communication overhead arise due to the extensive information exchange between edge devices and the server. In this paper, we develop CPFed, a communication-efficient and privacy-preserving federated learning method, to solve the above challenges. CPFed integrates three key components: (1) periodic averaging where local computation results at edge devices are only periodically averaged at the server; (2) Gaussian mechanism where edge devices randomly perturb their local computation results before sending the results to the server; and (3) secure aggregation where the perturbed local computation results are homomorphically encrypted before being sent to the server. CPFed can address both the communication efficiency and privacy leakage challenges in federated learning while achieving high model accuracy. We provide an end-to-end privacy guarantee of CPFed and analyze its theoretical convergence rates for both convex and non-convex models. Through extensive numerical experiments on real-world datasets, we demonstrate the effectiveness and efficiency of our proposed method.