 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Terminology Integration for LLM-based Translation in Specialized Domains
Oct 21, 2024Traditional machine translation methods typically involve training models directly on large parallel corpora, with limited emphasis on specialized terminology. However, In specialized fields such as patent, finance, or biomedical domains, terminology is crucial for translation, with many terms that needs to be translated following agreed-upon conventions. In this paper we introduce a methodology that efficiently trains models with a smaller amount of data while preserving the accuracy of terminology translation. We achieve this through a systematic process of term extraction and glossary creation using the Trie Tree algorithm, followed by data reconstruction to teach the LLM how to integrate these specialized terms. This methodology enhances the model's ability to handle specialized terminology and ensures high-quality translations, particularly in fields where term consistency is crucial. Our approach has demonstrated exceptional performance, achieving the highest translation score among participants in the WMT patent task to date, showcasing its effectiveness and broad applicability in specialized translation domains where general methods often fall short.
TelME: Teacher-leading Multimodal Fusion Network for Emotion Recognition in Conversation
Jan 16, 2024
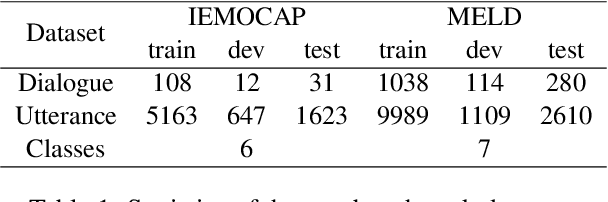
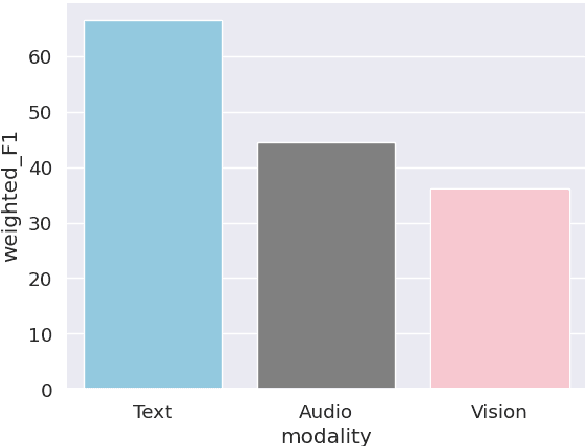
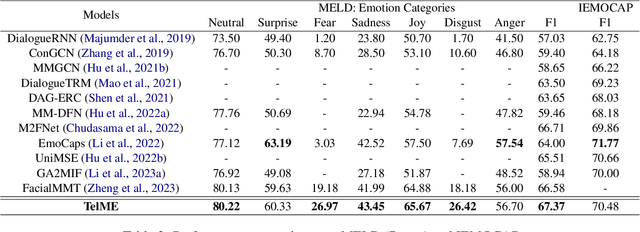
Emotion Recognition in Conversation (ERC) plays a crucial role in enabling dialogue systems to effectively respond to user requests. The emotions in a conversation can be identified by the representations from various modalities, such as audio, visual, and text. However, due to the weak contribution of non-verbal modalities to recognize emotions, multimodal ERC has always been considered a challenging task. In this paper, we propose Teacher-leading Multimodal fusion network for ERC (TelME). TelME incorporates cross-modal knowledge distillation to transfer information from a language model acting as the teacher to the non-verbal students, thereby optimizing the efficacy of the weak modalities. We then combine multimodal features using a shifting fusion approach in which student networks support the teacher. TelME achieves state-of-the-art performance in MELD, a multi-speaker conversation dataset for ERC. Finally, we demonstrate the effectiveness of our components through additional experiments.