 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaCeFormer: Fast Proposal-Free Open-Vocabulary 3D Instance Segmentation
Apr 22, 2026Open-vocabulary 3D instance segmentation is a core capability for robotics and AR/VR, but prior methods trade one bottleneck for another: multi-stage 2D+3D pipelines aggregate foundation-model outputs at hundreds of seconds per scene, while pseudo-labeled end-to-end approaches rely on fragmented masks and external region proposals. We present SpaCeFormer, a proposal-free space-curve transformer that runs at 0.14 seconds per scene, 2-3 orders of magnitude faster than multi-stage 2D+3D pipelines. We pair it with SpaCeFormer-3M, the largest open-vocabulary 3D instance segmentation dataset (3.0M multi-view-consistent captions over 604K instances from 7.4K scenes) built through multi-view mask clustering and multi-view VLM captioning; it reaches 21x higher mask recall than prior single-view pipelines (54.3% vs 2.5% at IoU > 0.5). SpaCeFormer combines spatial window attention with Morton-curve serialization for spatially coherent features, and uses a RoPE-enhanced decoder to predict instance masks directly from learned queries without external proposals. On ScanNet200 we achieve 11.1 zero-shot mAP, a 2.8x improvement over the prior best proposal-free method; on ScanNet++ and Replica, we reach 22.9 and 24.1 mAP, surpassing all prior methods including those using multi-view 2D inputs.
Affostruction: 3D Affordance Grounding with Generative Reconstruction
Jan 14, 2026This paper addresses the problem of affordance grounding from RGBD images of an object, which aims to localize surface regions corresponding to a text query that describes an action on the object. While existing methods predict affordance regions only on visible surfaces, we propose Affostruction, a generative framework that reconstructs complete geometry from partial observations and grounds affordances on the full shape including unobserved regions. We make three core contributions: generative multi-view reconstruction via sparse voxel fusion that extrapolates unseen geometry while maintaining constant token complexity, flow-based affordance grounding that captures inherent ambiguity in affordance distributions, and affordance-driven active view selection that leverages predicted affordances for intelligent viewpoint sampling. Affostruction achieves 19.1 aIoU on affordance grounding (40.4\% improvement) and 32.67 IoU for 3D reconstruction (67.7\% improvement), enabling accurate affordance prediction on complete shapes.
Affogato: Learning Open-Vocabulary Affordance Grounding with Automated Data Generation at Scale
Jun 13, 2025Affordance grounding-localizing object regions based on natural language descriptions of interactions-is a critical challenge for enabling intelligent agents to understand and interact with their environments. However, this task remains challenging due to the need for fine-grained part-level localization, the ambiguity arising from multiple valid interaction regions, and the scarcity of large-scale datasets. In this work, we introduce Affogato, a large-scale benchmark comprising 150K instances, annotated with open-vocabulary text descriptions and corresponding 3D affordance heatmaps across a diverse set of objects and interactions. Building on this benchmark, we develop simple yet effective vision-language models that leverage pretrained part-aware vision backbones and a text-conditional heatmap decoder. Our models trained with the Affogato dataset achieve promising performance on the existing 2D and 3D benchmarks, and notably, exhibit effectiveness in open-vocabulary cross-domain generalization. The Affogato dataset is shared in public: https://huggingface.co/datasets/project-affogato/affogato
Mosaic3D: Foundation Dataset and Model for Open-Vocabulary 3D Segmentation
Feb 04, 2025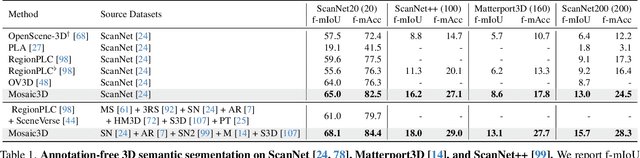

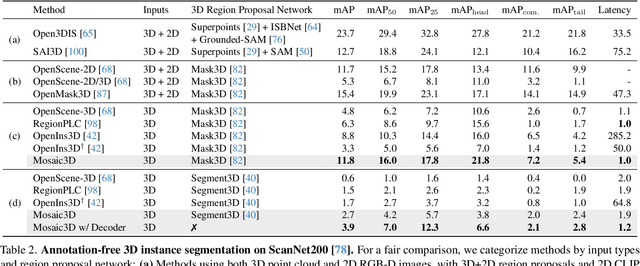
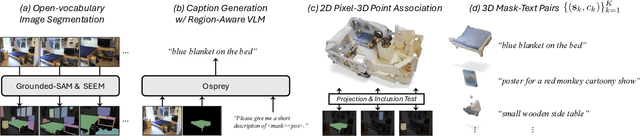
We tackle open-vocabulary 3D scene understanding by introducing a novel data generation pipeline and training framework. Our method addresses three critical requirements for effective training: precise 3D region segmentation, comprehensive textual descriptions, and sufficient dataset scale. By leveraging state-of-the-art open-vocabulary image segmentation models and region-aware Vision-Language Models, we develop an automatic pipeline that generates high-quality 3D mask-text pairs. Applying this pipeline to multiple 3D scene datasets, we create Mosaic3D-5.6M, a dataset of over 30K annotated scenes with 5.6M mask-text pairs, significantly larger than existing datasets. Building upon this data, we propose Mosaic3D, a foundation model combining a 3D encoder trained with contrastive learning and a lightweight mask decoder for open-vocabulary 3D semantic and instance segmentation. Our approach achieves state-of-the-art results on open-vocabulary 3D semantic and instance segmentation tasks including ScanNet200, Matterport3D, and ScanNet++, with ablation studies validating the effectiveness of our large-scale training data.
Learning SO(3)-Invariant Semantic Correspondence via Local Shape Transform
Apr 17, 2024


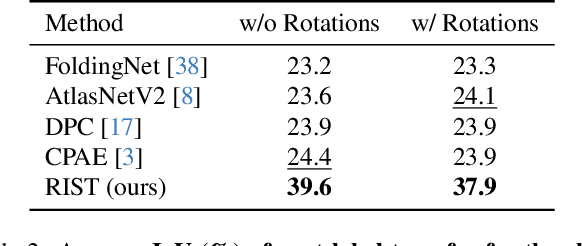
Establishing accurate 3D correspondences between shapes stands as a pivotal challenge with profound implications for computer vision and robotics. However, existing self-supervised methods for this problem assume perfect input shape alignment, restricting their real-world applicability. In this work, we introduce a novel self-supervised Rotation-Invariant 3D correspondence learner with Local Shape Transform, dubbed RIST, that learns to establish dense correspondences between shapes even under challenging intra-class variations and arbitrary orientations. Specifically, RIST learns to dynamically formulate an SO(3)-invariant local shape transform for each point, which maps the SO(3)-equivariant global shape descriptor of the input shape to a local shape descriptor. These local shape descriptors are provided as inputs to our decoder to facilitate point cloud self- and cross-reconstruction. Our proposed self-supervised training pipeline encourages semantically corresponding points from different shapes to be mapped to similar local shape descriptors, enabling RIST to establish dense point-wise correspondences. RIST demonstrates state-of-the-art performances on 3D part label transfer and semantic keypoint transfer given arbitrarily rotated point cloud pairs, outperforming existing methods by significant margins.
Stable and Consistent Prediction of 3D Characteristic Orientation via Invariant Residual Learning
Jun 20, 2023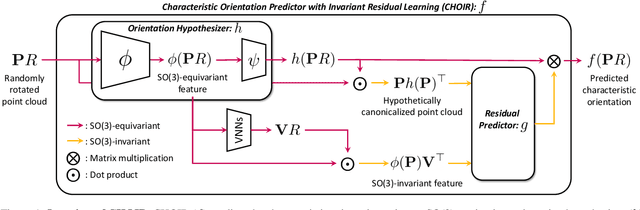

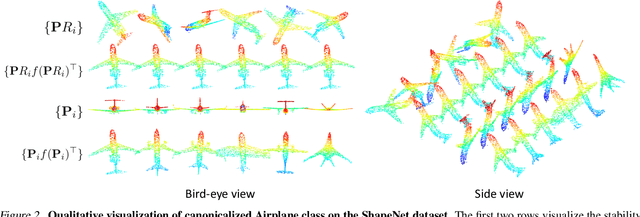

Learning to predict reliable characteristic orientations of 3D point clouds is an important yet challenging problem, as different point clouds of the same class may have largely varying appearances. In this work, we introduce a novel method to decouple the shape geometry and semantics of the input point cloud to achieve both stability and consistency. The proposed method integrates shape-geometry-based SO(3)-equivariant learning and shape-semantics-based SO(3)-invariant residual learning, where a final characteristic orientation is obtained by calibrating an SO(3)-equivariant orientation hypothesis using an SO(3)-invariant residual rotation. In experiments, the proposed method not only demonstrates superior stability and consistency but also exhibits state-of-the-art performances when applied to point cloud part segmentation, given randomly rotated inputs.
Fast Point Transformer
Dec 09, 2021
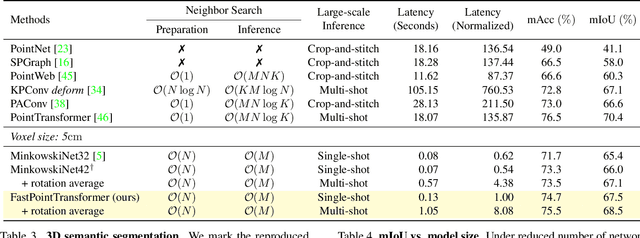
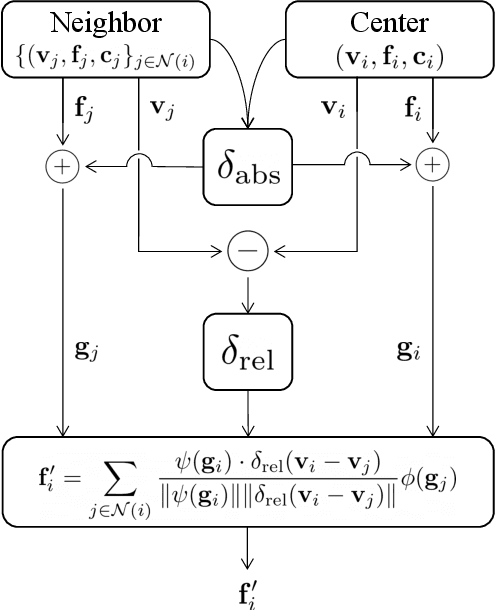
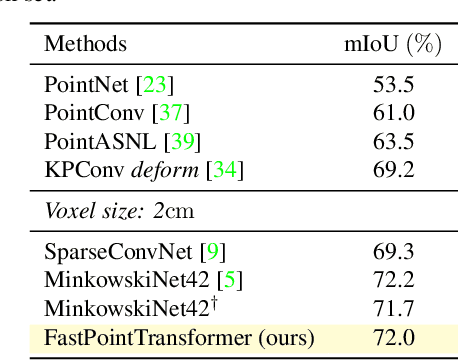
The recent success of neural networks enables a better interpretation of 3D point clouds, but processing a large-scale 3D scene remains a challenging problem. Most current approaches divide a large-scale scene into small regions and combine the local predictions together. However, this scheme inevitably involves additional stages for pre- and post-processing and may also degrade the final output due to predictions in a local perspective. This paper introduces Fast Point Transformer that consists of a new lightweight self-attention layer. Our approach encodes continuous 3D coordinates, and the voxel hashing-based architecture boosts computational efficiency. The proposed method is demonstrated with 3D semantic segmentation and 3D detection. The accuracy of our approach is competitive to the best voxel-based method, and our network achieves 136 times faster inference time than the state-of-the-art, Point Transformer, with a reasonable accuracy trade-off.
PointMixer: MLP-Mixer for Point Cloud Understanding
Nov 27, 2021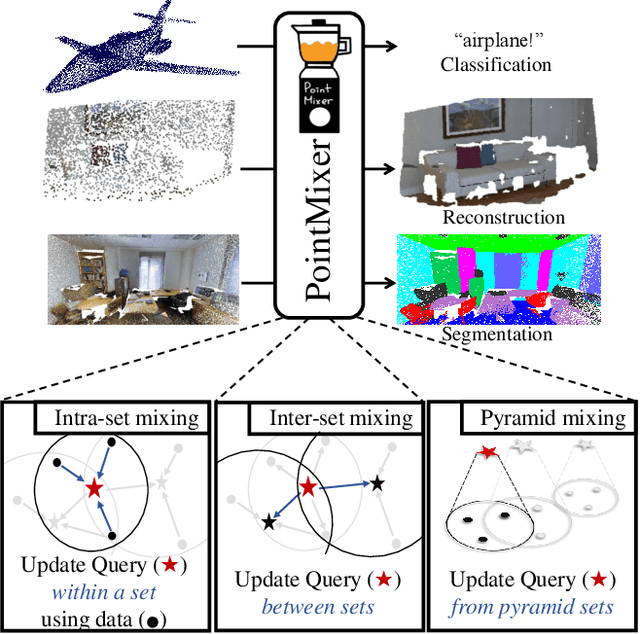

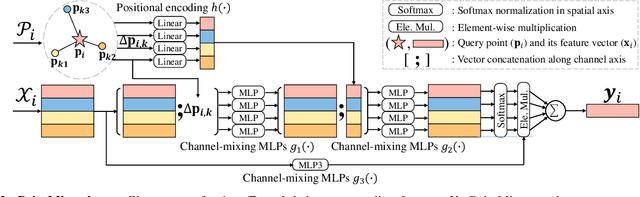

MLP-Mixer has newly appeared as a new challenger against the realm of CNNs and transformer. Despite its simplicity compared to transformer, the concept of channel-mixing MLPs and token-mixing MLPs achieves noticeable performance in visual recognition tasks. Unlike images, point clouds are inherently sparse, unordered and irregular, which limits the direct use of MLP-Mixer for point cloud understanding. In this paper, we propose PointMixer, a universal point set operator that facilitates information sharing among unstructured 3D points. By simply replacing token-mixing MLPs with a softmax function, PointMixer can "mix" features within/between point sets. By doing so, PointMixer can be broadly used in the network as inter-set mixing, intra-set mixing, and pyramid mixing. Extensive experiments show the competitive or superior performance of PointMixer in semantic segmentation, classification, and point reconstruction against transformer-based methods.