 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlag Aggregator: Scalable Distributed Training under Failures and Augmented Losses using Convex Optimization
Feb 12, 2023



Modern ML applications increasingly rely on complex deep learning models and large datasets. There has been an exponential growth in the amount of computation needed to train the largest models. Therefore, to scale computation and data, these models are inevitably trained in a distributed manner in clusters of nodes, and their updates are aggregated before being applied to the model. However, a distributed setup is prone to byzantine failures of individual nodes, components, and software. With data augmentation added to these settings, there is a critical need for robust and efficient aggregation systems. We extend the current state-of-the-art aggregators and propose an optimization-based subspace estimator by modeling pairwise distances as quadratic functions by utilizing the recently introduced Flag Median problem. The estimator in our loss function favors the pairs that preserve the norm of the difference vector. We theoretically show that our approach enhances the robustness of state-of-the-art byzantine resilient aggregators. Also, we evaluate our method with different tasks in a distributed setup with a parameter server architecture and show its communication efficiency while maintaining similar accuracy. The code is publicly available at https://github.com/hamidralmasi/FlagAggregator
Modeling Performance and Energy trade-offs in Online Data-Intensive Applications
Aug 18, 2021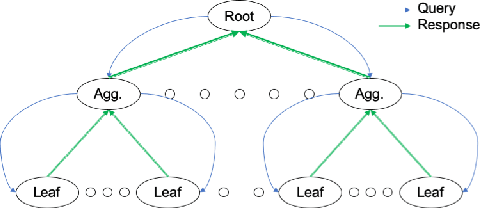
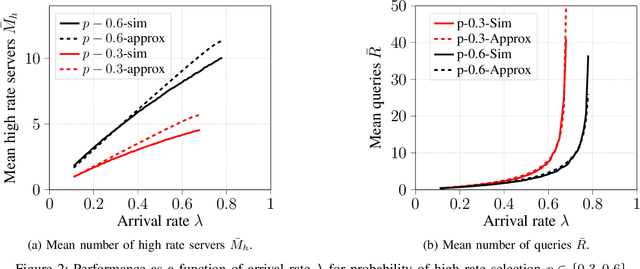
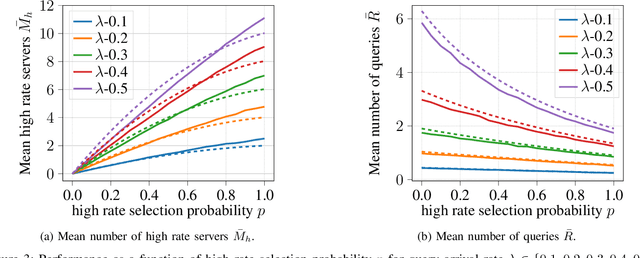
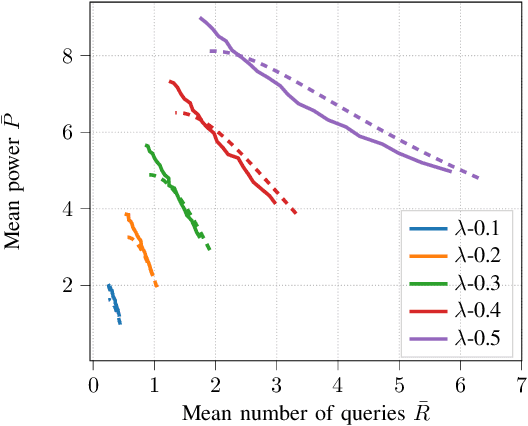
We consider energy minimization for data-intensive applications run on large number of servers, for given performance guarantees. We consider a system, where each incoming application is sent to a set of servers, and is considered to be completed if a subset of them finish serving it. We consider a simple case when each server core has two speed levels, where the higher speed can be achieved by higher power for each core independently. The core selects one of the two speeds probabilistically for each incoming application request. We model arrival of application requests by a Poisson process, and random service time at the server with independent exponential random variables. Our model and analysis generalizes to today's state-of-the-art in CPU energy management where each core can independently select a speed level from a set of supported speeds and corresponding voltages. The performance metrics under consideration are the mean number of applications in the system and the average energy expenditure. We first provide a tight approximation to study this previously intractable problem and derive closed form approximate expressions for the performance metrics when service times are exponentially distributed. Next, we study the trade-off between the approximate mean number of applications and energy expenditure in terms of the switching probability.