 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA in LoRA: Towards Parameter-Efficient Architecture Expansion for Continual Visual Instruction Tuning
Aug 08, 2025Continual Visual Instruction Tuning (CVIT) enables Multimodal Large Language Models (MLLMs) to incrementally learn new tasks over time. However, this process is challenged by catastrophic forgetting, where performance on previously learned tasks deteriorates as the model adapts to new ones. A common approach to mitigate forgetting is architecture expansion, which introduces task-specific modules to prevent interference. Yet, existing methods often expand entire layers for each task, leading to significant parameter overhead and poor scalability. To overcome these issues, we introduce LoRA in LoRA (LiLoRA), a highly efficient architecture expansion method tailored for CVIT in MLLMs. LiLoRA shares the LoRA matrix A across tasks to reduce redundancy, applies an additional low-rank decomposition to matrix B to minimize task-specific parameters, and incorporates a cosine-regularized stability loss to preserve consistency in shared representations over time. Extensive experiments on a diverse CVIT benchmark show that LiLoRA consistently achieves superior performance in sequential task learning while significantly improving parameter efficiency compared to existing approaches.
Segment Any 3D-Part in a Scene from a Sentence
Jun 24, 2025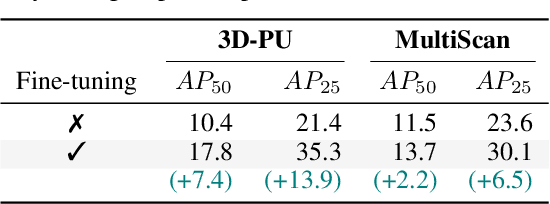
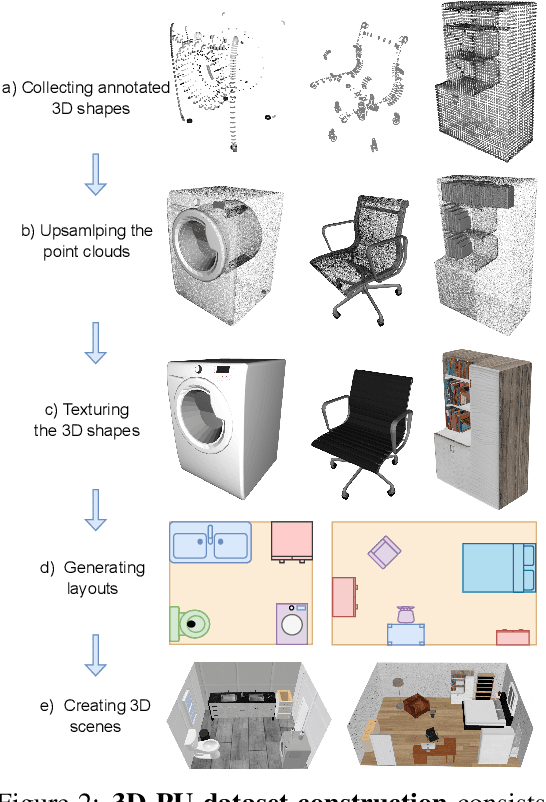


This paper aims to achieve the segmentation of any 3D part in a scene based on natural language descriptions, extending beyond traditional object-level 3D scene understanding and addressing both data and methodological challenges. Due to the expensive acquisition and annotation burden, existing datasets and methods are predominantly limited to object-level comprehension. To overcome the limitations of data and annotation availability, we introduce the 3D-PU dataset, the first large-scale 3D dataset with dense part annotations, created through an innovative and cost-effective method for constructing synthetic 3D scenes with fine-grained part-level annotations, paving the way for advanced 3D-part scene understanding. On the methodological side, we propose OpenPart3D, a 3D-input-only framework to effectively tackle the challenges of part-level segmentation. Extensive experiments demonstrate the superiority of our approach in open-vocabulary 3D scene understanding tasks at the part level, with strong generalization capabilities across various 3D scene datasets.
Self-Ordering Point Clouds
Apr 10, 2023In this paper we address the task of finding representative subsets of points in a 3D point cloud by means of a point-wise ordering. Only a few works have tried to address this challenging vision problem, all with the help of hard to obtain point and cloud labels. Different from these works, we introduce the task of point-wise ordering in 3D point clouds through self-supervision, which we call self-ordering. We further contribute the first end-to-end trainable network that learns a point-wise ordering in a self-supervised fashion. It utilizes a novel differentiable point scoring-sorting strategy and it constructs an hierarchical contrastive scheme to obtain self-supervision signals. We extensively ablate the method and show its scalability and superior performance even compared to supervised ordering methods on multiple datasets and tasks including zero-shot ordering of point clouds from unseen categories.
Less than Few: Self-Shot Video Instance Segmentation
Apr 19, 2022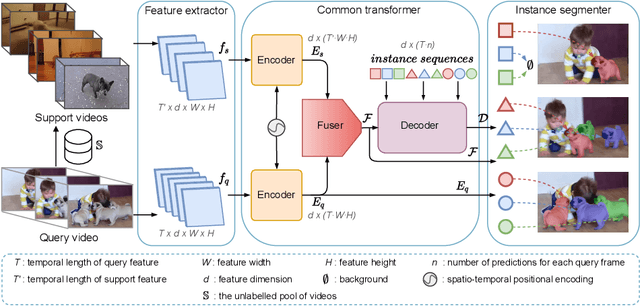
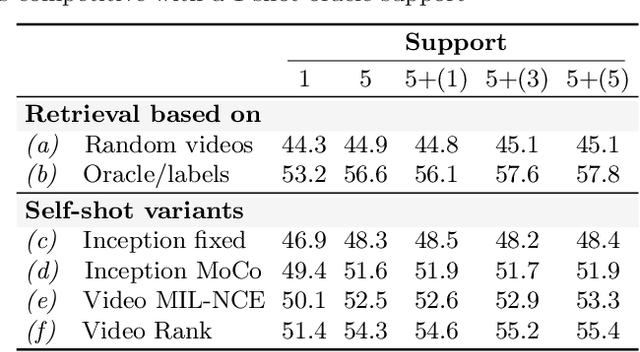
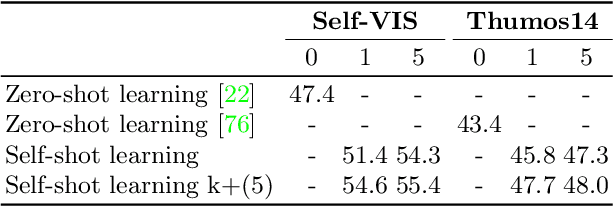
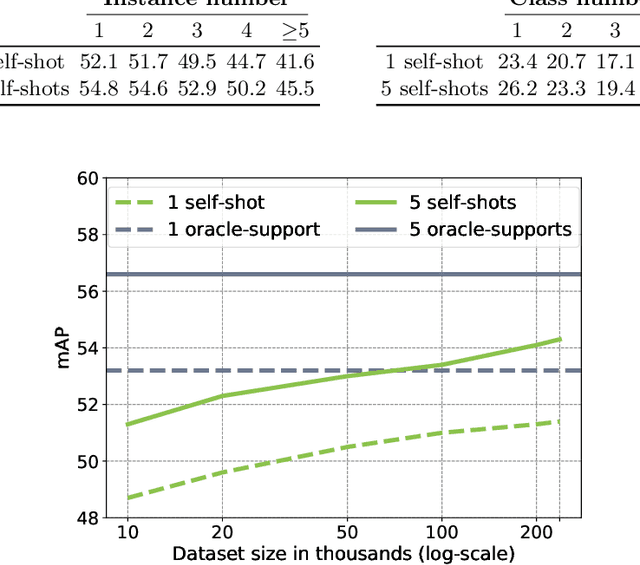
The goal of this paper is to bypass the need for labelled examples in few-shot video understanding at run time. While proven effective, in many practical video settings even labelling a few examples appears unrealistic. This is especially true as the level of details in spatio-temporal video understanding and with it, the complexity of annotations continues to increase. Rather than performing few-shot learning with a human oracle to provide a few densely labelled support videos, we propose to automatically learn to find appropriate support videos given a query. We call this self-shot learning and we outline a simple self-supervised learning method to generate an embedding space well-suited for unsupervised retrieval of relevant samples. To showcase this novel setting, we tackle, for the first time, video instance segmentation in a self-shot (and few-shot) setting, where the goal is to segment instances at the pixel-level across the spatial and temporal domains. We provide strong baseline performances that utilize a novel transformer-based model and show that self-shot learning can even surpass few-shot and can be positively combined for further performance gains. Experiments on new benchmarks show that our approach achieves strong performance, is competitive to oracle support in some settings, scales to large unlabelled video collections, and can be combined in a semi-supervised setting.
Few-Shot Transformation of Common Actions into Time and Space
Apr 06, 2021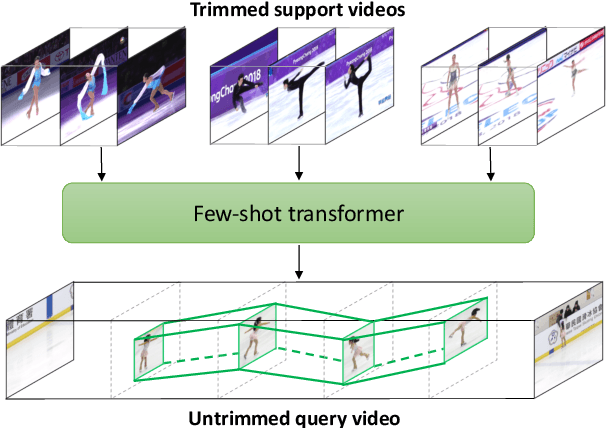
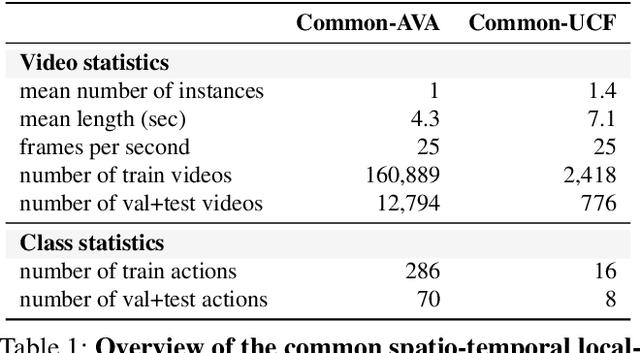
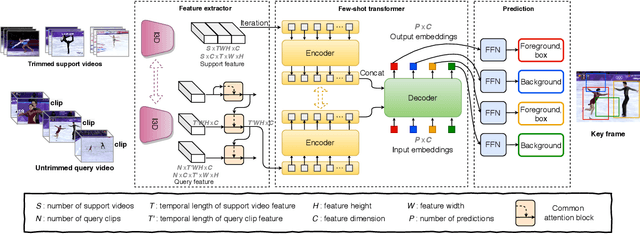

This paper introduces the task of few-shot common action localization in time and space. Given a few trimmed support videos containing the same but unknown action, we strive for spatio-temporal localization of that action in a long untrimmed query video. We do not require any class labels, interval bounds, or bounding boxes. To address this challenging task, we introduce a novel few-shot transformer architecture with a dedicated encoder-decoder structure optimized for joint commonality learning and localization prediction, without the need for proposals. Experiments on our reorganizations of the AVA and UCF101-24 datasets show the effectiveness of our approach for few-shot common action localization, even when the support videos are noisy. Although we are not specifically designed for common localization in time only, we also compare favorably against the few-shot and one-shot state-of-the-art in this setting. Lastly, we demonstrate that the few-shot transformer is easily extended to common action localization per pixel.
Localizing the Common Action Among a Few Videos
Aug 25, 2020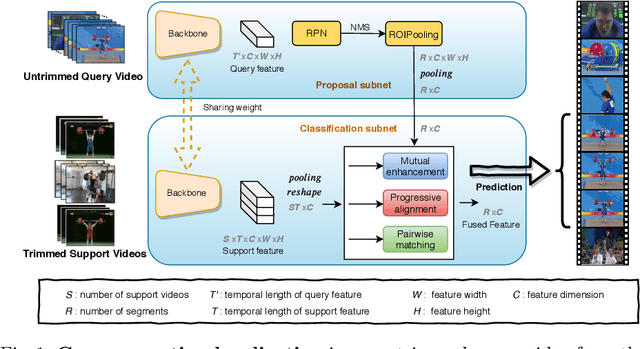
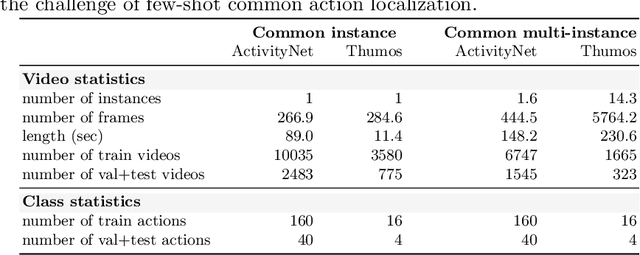
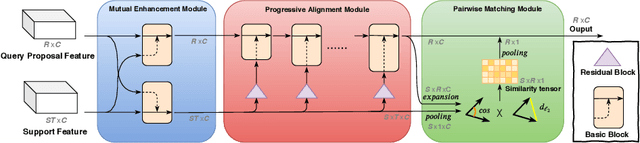
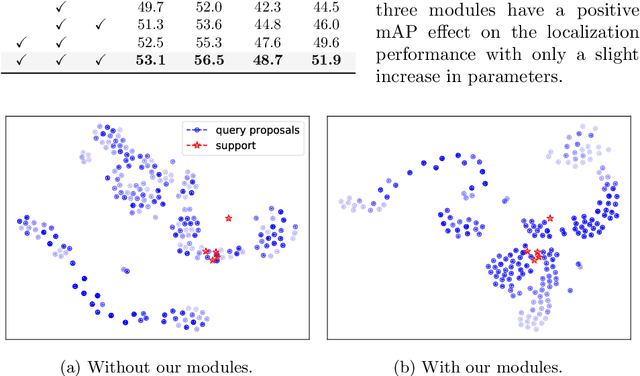
This paper strives to localize the temporal extent of an action in a long untrimmed video. Where existing work leverages many examples with their start, their ending, and/or the class of the action during training time, we propose few-shot common action localization. The start and end of an action in a long untrimmed video is determined based on just a hand-full of trimmed video examples containing the same action, without knowing their common class label. To address this task, we introduce a new 3D convolutional network architecture able to align representations from the support videos with the relevant query video segments. The network contains: (\textit{i}) a mutual enhancement module to simultaneously complement the representation of the few trimmed support videos and the untrimmed query video; (\textit{ii}) a progressive alignment module that iteratively fuses the support videos into the query branch; and (\textit{iii}) a pairwise matching module to weigh the importance of different support videos. Evaluation of few-shot common action localization in untrimmed videos containing a single or multiple action instances demonstrates the effectiveness and general applicability of our proposal.
PointMixup: Augmentation for Point Clouds
Aug 14, 2020
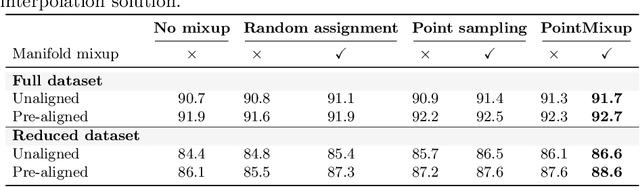
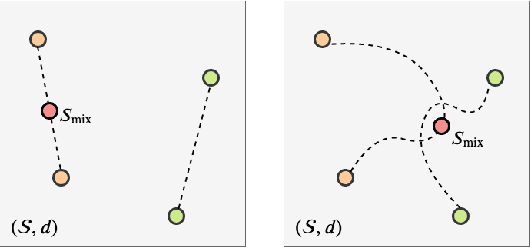
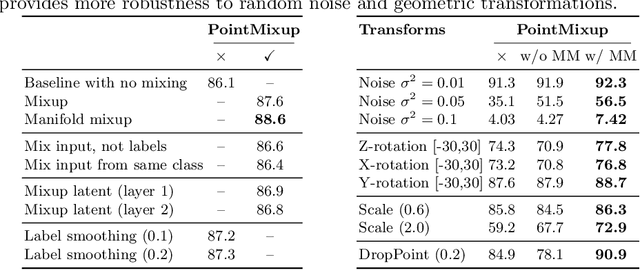
This paper introduces data augmentation for point clouds by interpolation between examples. Data augmentation by interpolation has shown to be a simple and effective approach in the image domain. Such a mixup is however not directly transferable to point clouds, as we do not have a one-to-one correspondence between the points of two different objects. In this paper, we define data augmentation between point clouds as a shortest path linear interpolation. To that end, we introduce PointMixup, an interpolation method that generates new examples through an optimal assignment of the path function between two point clouds. We prove that our PointMixup finds the shortest path between two point clouds and that the interpolation is assignment invariant and linear. With the definition of interpolation, PointMixup allows to introduce strong interpolation-based regularizers such as mixup and manifold mixup to the point cloud domain. Experimentally, we show the potential of PointMixup for point cloud classification, especially when examples are scarce, as well as increased robustness to noise and geometric transformations to points. The code for PointMixup and the experimental details are publicly available.