 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare-Aware Autoencoding: Reconstructing Spatially Imbalanced Data
Apr 02, 2026Autoencoders can be challenged by spatially non-uniform sampling of image content. This is common in medical imaging, biology, and physics, where informative patterns occur rarely at specific image coordinates, as background dominates these locations in most samples, biasing reconstructions toward the majority appearance. In practice, autoencoders are biased toward dominant patterns resulting in the loss of fine-grained detail and causing blurred reconstructions for rare spatial inputs especially under spatial data imbalance. We address spatial imbalance by two complementary components: (i) self-entropy-based loss that upweights statistically uncommon spatial locations and (ii) Sample Propagation, a replay mechanism that selectively re-exposes the model to hard to reconstruct samples across batches during training. We benchmark existing data balancing strategies, originally developed for supervised classification, in the unsupervised reconstruction setting. Drawing on the limitations of these approaches, our method specifically targets spatial imbalance by encouraging models to focus on statistically rare locations, improving reconstruction consistency compared to existing baselines. We validate in a simulated dataset with controlled spatial imbalance conditions, and in three, uncontrolled, diverse real-world datasets spanning physical, biological, and astronomical domains. Our approach outperforms baselines on various reconstruction metrics, particularly under spatial imbalance distributions. These results highlight the importance of data representation in a batch and emphasize rare samples in unsupervised image reconstruction. We will make all code and related data available.
Data-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025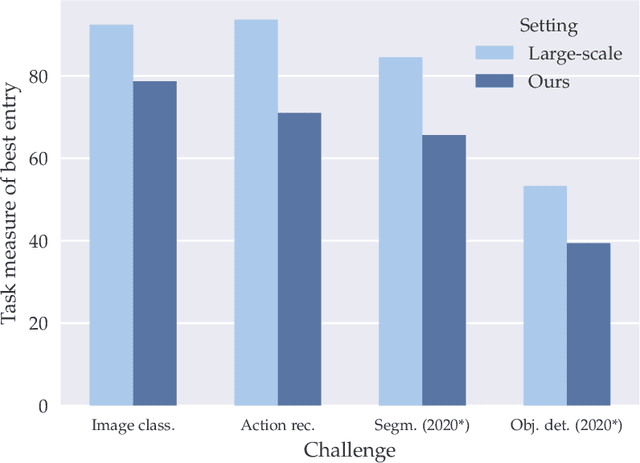
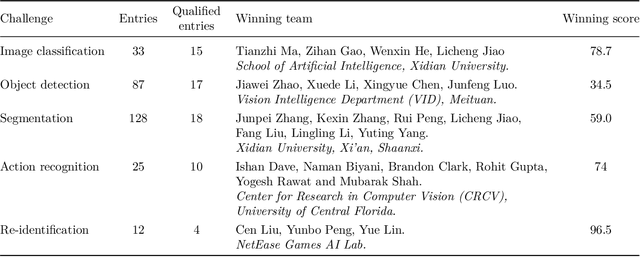

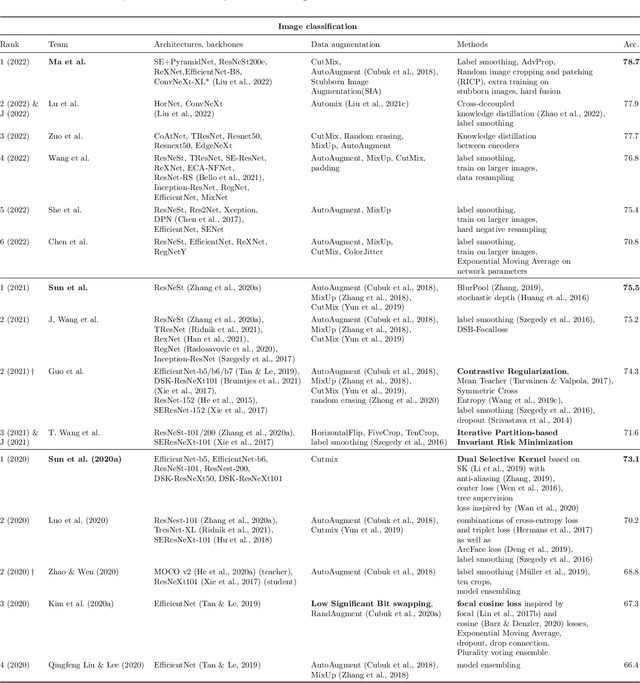
Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
Local Attention Transformers for High-Detail Optical Flow Upsampling
Dec 09, 2024Most recent works on optical flow use convex upsampling as the last step to obtain high-resolution flow. In this work, we show and discuss several issues and limitations of this currently widely adopted convex upsampling approach. We propose a series of changes, in an attempt to resolve current issues. First, we propose to decouple the weights for the final convex upsampler, making it easier to find the correct convex combination. For the same reason, we also provide extra contextual features to the convex upsampler. Then, we increase the convex mask size by using an attention-based alternative convex upsampler; Transformers for Convex Upsampling. This upsampler is based on the observation that convex upsampling can be reformulated as attention, and we propose to use local attention masks as a drop-in replacement for convex masks to increase the mask size. We provide empirical evidence that a larger mask size increases the likelihood of the existence of the convex combination. Lastly, we propose an alternative training scheme to remove bilinear interpolation artifacts from the model output. Our proposed ideas could theoretically be applied to almost every current state-of-the-art optical flow architecture. On the FlyingChairs + FlyingThings3D training setting we reduce the Sintel Clean training end-point-error of RAFT from 1.42 to 1.26, GMA from 1.31 to 1.18, and that of FlowFormer from 0.94 to 0.90, by solely adapting the convex upsampler.
Learning Physics From Video: Unsupervised Physical Parameter Estimation for Continuous Dynamical Systems
Oct 02, 2024



Extracting physical dynamical system parameters from videos is of great interest to applications in natural science and technology. The state-of-the-art in automatic parameter estimation from video is addressed by training supervised deep networks on large datasets. Such datasets require labels, which are difficult to acquire. While some unsupervised techniques -- which depend on frame prediction -- exist, they suffer from long training times, instability under different initializations, and are limited to hand-picked motion problems. In this work, we propose a method to estimate the physical parameters of any known, continuous governing equation from single videos; our solution is suitable for different dynamical systems beyond motion and is robust to initialization compared to previous approaches. Moreover, we remove the need for frame prediction by implementing a KL-divergence-based loss function in the latent space, which avoids convergence to trivial solutions and reduces model size and compute.
Deep activity propagation via weight initialization in spiking neural networks
Oct 01, 2024Spiking Neural Networks (SNNs) and neuromorphic computing offer bio-inspired advantages such as sparsity and ultra-low power consumption, providing a promising alternative to conventional networks. However, training deep SNNs from scratch remains a challenge, as SNNs process and transmit information by quantizing the real-valued membrane potentials into binary spikes. This can lead to information loss and vanishing spikes in deeper layers, impeding effective training. While weight initialization is known to be critical for training deep neural networks, what constitutes an effective initial state for a deep SNN is not well-understood. Existing weight initialization methods designed for conventional networks (ANNs) are often applied to SNNs without accounting for their distinct computational properties. In this work we derive an optimal weight initialization method specifically tailored for SNNs, taking into account the quantization operation. We show theoretically that, unlike standard approaches, this method enables the propagation of activity in deep SNNs without loss of spikes. We demonstrate this behavior in numerical simulations of SNNs with up to 100 layers across multiple time steps. We present an in-depth analysis of the numerical conditions, regarding layer width and neuron hyperparameters, which are necessary to accurately apply our theoretical findings. Furthermore, our experiments on MNIST demonstrate higher accuracy and faster convergence when using the proposed weight initialization scheme. Finally, we show that the newly introduced weight initialization is robust against variations in several network and neuron hyperparameters.
Copy-Pasting Coherent Depth Regions Improves Contrastive Learning for Urban-Scene Segmentation
Nov 25, 2022
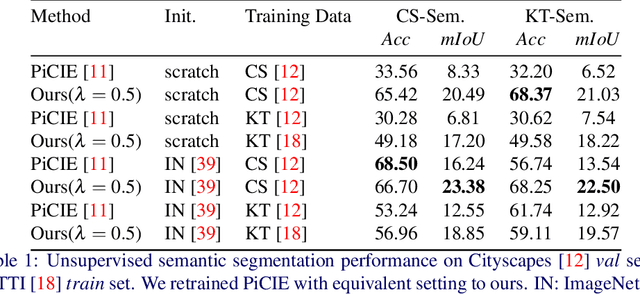
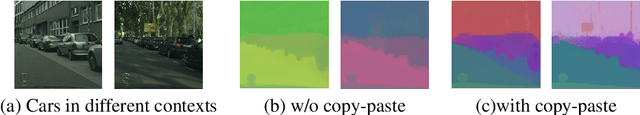
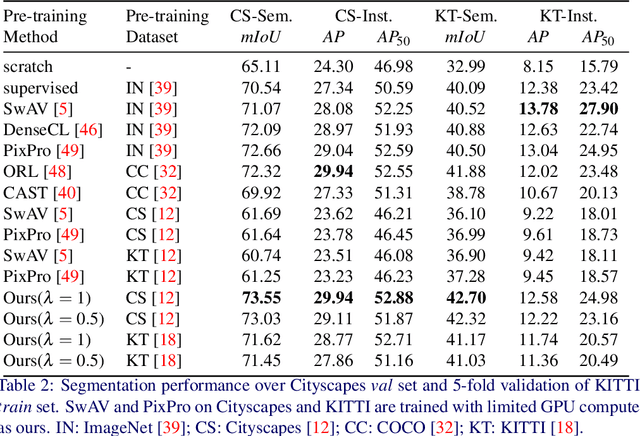
In this work, we leverage estimated depth to boost self-supervised contrastive learning for segmentation of urban scenes, where unlabeled videos are readily available for training self-supervised depth estimation. We argue that the semantics of a coherent group of pixels in 3D space is self-contained and invariant to the contexts in which they appear. We group coherent, semantically related pixels into coherent depth regions given their estimated depth and use copy-paste to synthetically vary their contexts. In this way, cross-context correspondences are built in contrastive learning and a context-invariant representation is learned. For unsupervised semantic segmentation of urban scenes, our method surpasses the previous state-of-the-art baseline by +7.14% in mIoU on Cityscapes and +6.65% on KITTI. For fine-tuning on Cityscapes and KITTI segmentation, our method is competitive with existing models, yet, we do not need to pre-train on ImageNet or COCO, and we are also more computationally efficient. Our code is available on https://github.com/LeungTsang/CPCDR