Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Paper and Code
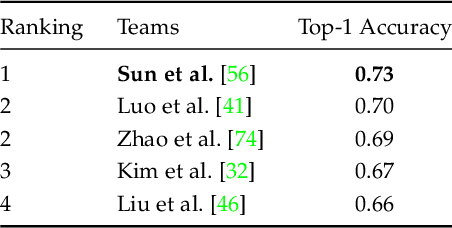
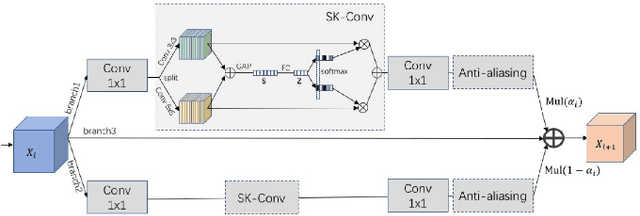
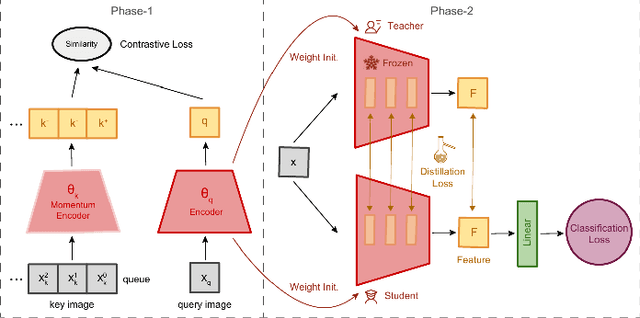

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
* 11 pages, 11 figures
View paper on