 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Predictive Models for Convolutional Neural Networks on Mobile Platforms
Apr 10, 2020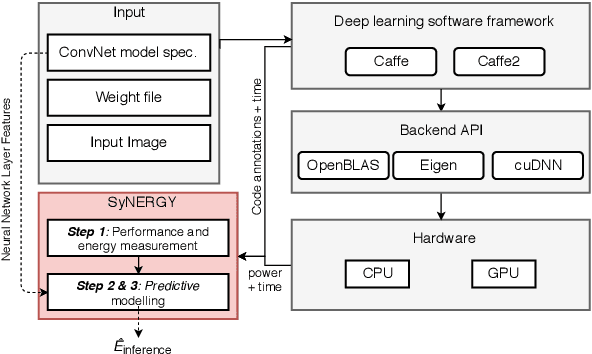
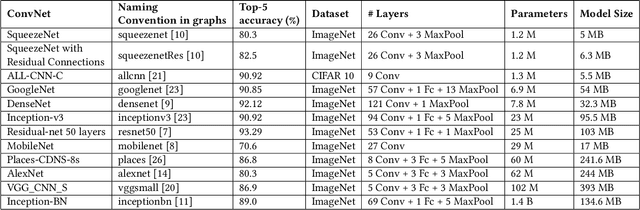
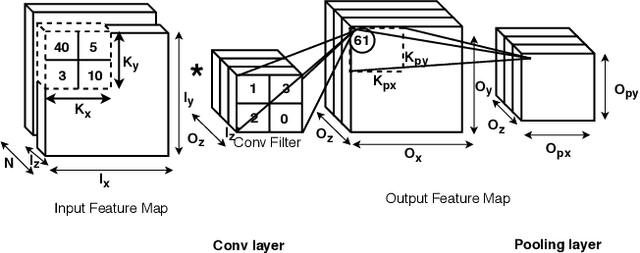

Energy use is a key concern when deploying deep learning models on mobile and embedded platforms. Current studies develop energy predictive models based on application-level features to provide researchers a way to estimate the energy consumption of their deep learning models. This information is useful for building resource-aware models that can make efficient use of the hard-ware resources. However, previous works on predictive modelling provide little insight into the trade-offs involved in the choice of features on the final predictive model accuracy and model complexity. To address this issue, we provide a comprehensive analysis of building regression-based predictive models for deep learning on mobile devices, based on empirical measurements gathered from the SyNERGY framework.Our predictive modelling strategy is based on two types of predictive models used in the literature:individual layers and layer-type. Our analysis of predictive models show that simple layer-type features achieve a model complexity of 4 to 32 times less for convolutional layer predictions for a similar accuracy compared to predictive models using more complex features adopted by previous approaches. To obtain an overall energy estimate of the inference phase, we build layer-type predictive models for the fully-connected and pooling layers using 12 representative Convolutional NeuralNetworks (ConvNets) on the Jetson TX1 and the Snapdragon 820using software backends such as OpenBLAS, Eigen and CuDNN. We obtain an accuracy between 76% to 85% and a model complexity of 1 for the overall energy prediction of the test ConvNets across different hardware-software combinations.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018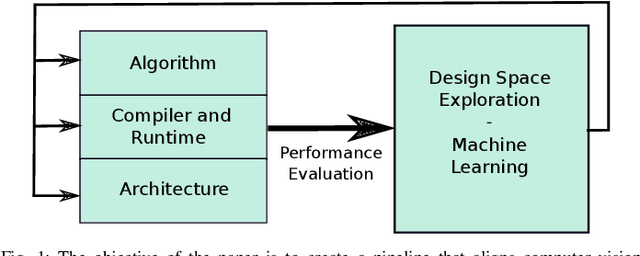

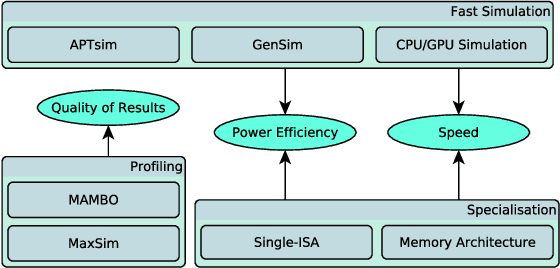
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.
Introducing SLAMBench, a performance and accuracy benchmarking methodology for SLAM
Feb 26, 2015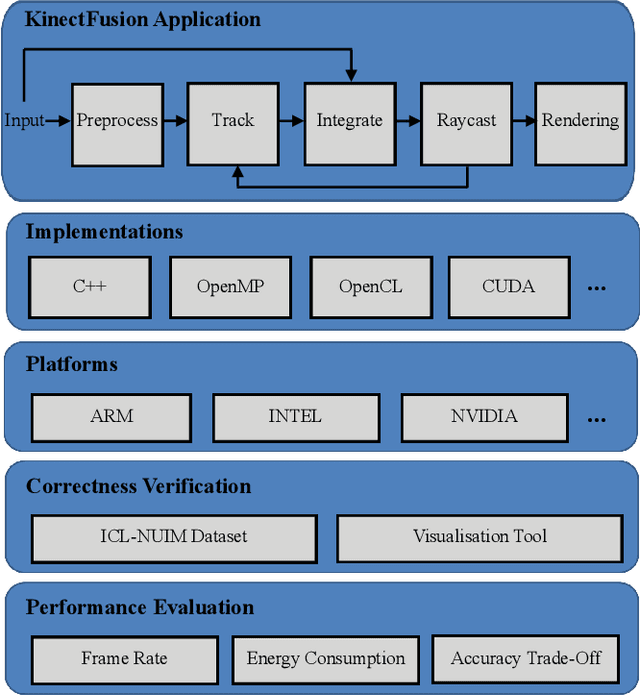

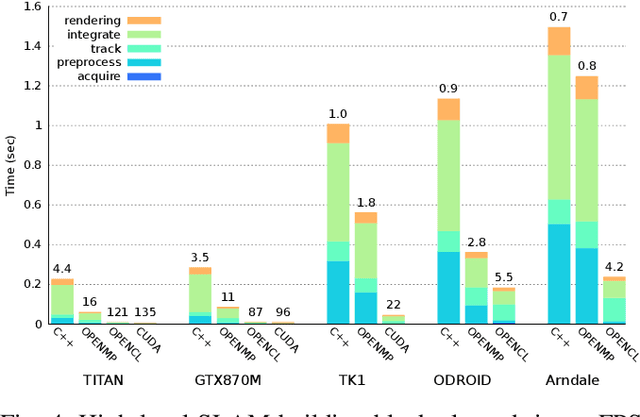
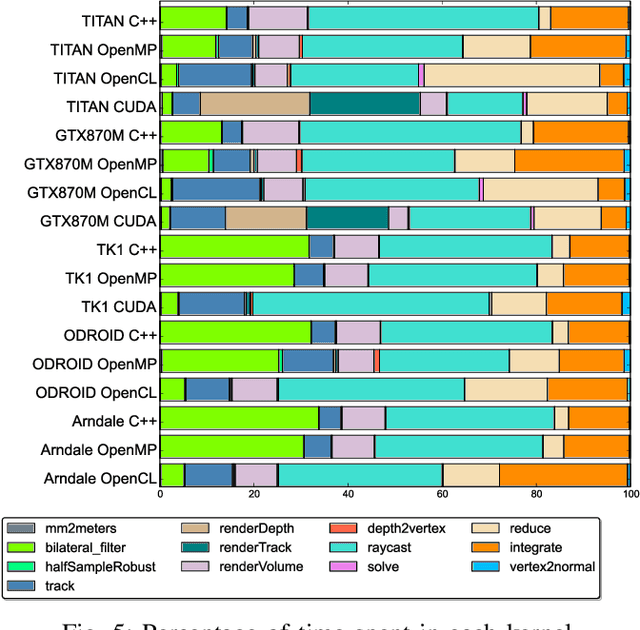
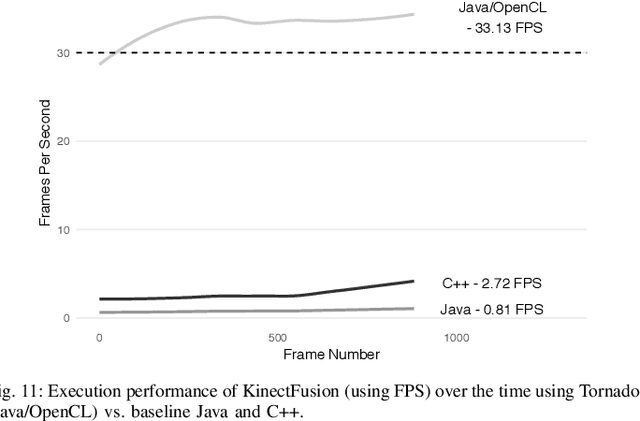
Real-time dense computer vision and SLAM offer great potential for a new level of scene modelling, tracking and real environmental interaction for many types of robot, but their high computational requirements mean that use on mass market embedded platforms is challenging. Meanwhile, trends in low-cost, low-power processing are towards massive parallelism and heterogeneity, making it difficult for robotics and vision researchers to implement their algorithms in a performance-portable way. In this paper we introduce SLAMBench, a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs in performance, accuracy and energy consumption of a dense RGB-D SLAM system. SLAMBench provides a KinectFusion implementation in C++, OpenMP, OpenCL and CUDA, and harnesses the ICL-NUIM dataset of synthetic RGB-D sequences with trajectory and scene ground truth for reliable accuracy comparison of different implementation and algorithms. We present an analysis and breakdown of the constituent algorithmic elements of KinectFusion, and experimentally investigate their execution time on a variety of multicore and GPUaccelerated platforms. For a popular embedded platform, we also present an analysis of energy efficiency for different configuration alternatives.
* 8 pages, ICRA 2015 conference paper