 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Classifier Circuits: Evolving Accelerators for Tabular Data
Feb 28, 2023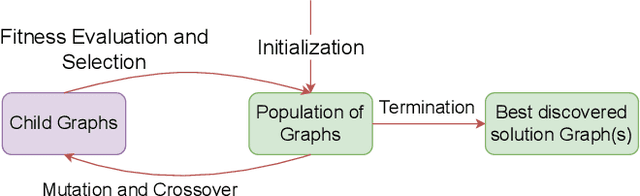
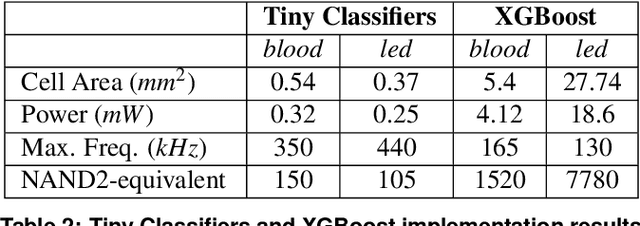
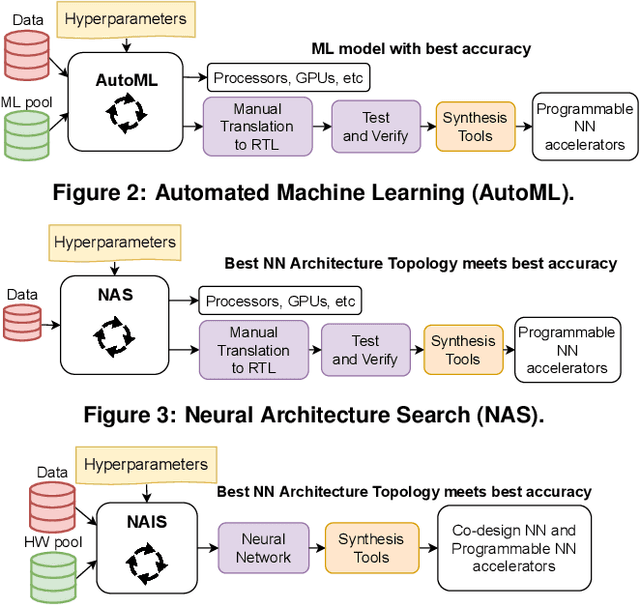
A typical machine learning (ML) development cycle for edge computing is to maximise the performance during model training and then minimise the memory/area footprint of the trained model for deployment on edge devices targeting CPUs, GPUs, microcontrollers, or custom hardware accelerators. This paper proposes a methodology for automatically generating predictor circuits for classification of tabular data with comparable prediction performance to conventional ML techniques while using substantially fewer hardware resources and power. The proposed methodology uses an evolutionary algorithm to search over the space of logic gates and automatically generates a classifier circuit with maximised training prediction accuracy. Classifier circuits are so tiny (i.e., consisting of no more than 300 logic gates) that they are called "Tiny Classifier" circuits, and can efficiently be implemented in ASIC or on an FPGA. We empirically evaluate the automatic Tiny Classifier circuit generation methodology or "Auto Tiny Classifiers" on a wide range of tabular datasets, and compare it against conventional ML techniques such as Amazon's AutoGluon, Google's TabNet and a neural search over Multi-Layer Perceptrons. Despite Tiny Classifiers being constrained to a few hundred logic gates, we observe no statistically significant difference in prediction performance in comparison to the best-performing ML baseline. When synthesised as a Silicon chip, Tiny Classifiers use 8-56x less area and 4-22x less power. When implemented as an ultra-low cost chip on a flexible substrate (i.e., FlexIC), they occupy 10-75x less area and consume 13-75x less power compared to the most hardware-efficient ML baseline. On an FPGA, Tiny Classifiers consume 3-11x fewer resources.
A Unified Theory of Diversity in Ensemble Learning
Jan 10, 2023



We present a theory of ensemble diversity, explaining the nature and effect of diversity for a wide range of supervised learning scenarios. This challenge, of understanding ensemble diversity, has been referred to as the holy grail of ensemble learning, an open question for over 30 years. Our framework reveals that diversity is in fact a hidden dimension in the bias-variance decomposition of an ensemble. In particular, we prove a family of exact bias-variance-diversity decompositions, for both classification and regression losses, e.g., squared, and cross-entropy. The framework provides a methodology to automatically identify the combiner rule enabling such a decomposition, specific to the loss. The formulation of diversity is therefore dependent on just two design choices: the loss, and the combiner. For certain choices (e.g., 0-1 loss with majority voting) the effect of diversity is necessarily dependent on the target label. Experiments illustrate how we can use our framework to understand the diversity-encouraging mechanisms of popular ensemble methods: Bagging, Boosting, and Random Forests.
QNNVerifier: A Tool for Verifying Neural Networks using SMT-Based Model Checking
Nov 25, 2021
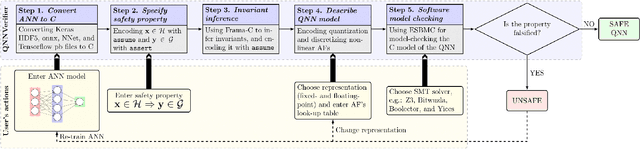


QNNVerifier is the first open-source tool for verifying implementations of neural networks that takes into account the finite word-length (i.e. quantization) of their operands. The novel support for quantization is achieved by employing state-of-the-art software model checking (SMC) techniques. It translates the implementation of neural networks to a decidable fragment of first-order logic based on satisfiability modulo theories (SMT). The effects of fixed- and floating-point operations are represented through direct implementations given a hardware-determined precision. Furthermore, QNNVerifier allows to specify bespoke safety properties and verify the resulting model with different verification strategies (incremental and k-induction) and SMT solvers. Finally, QNNVerifier is the first tool that combines invariant inference via interval analysis and discretization of non-linear activation functions to speed up the verification of neural networks by orders of magnitude. A video presentation of QNNVerifier is available at https://youtu.be/7jMgOL41zTY
Robust SLAM Systems: Are We There Yet?
Sep 27, 2021
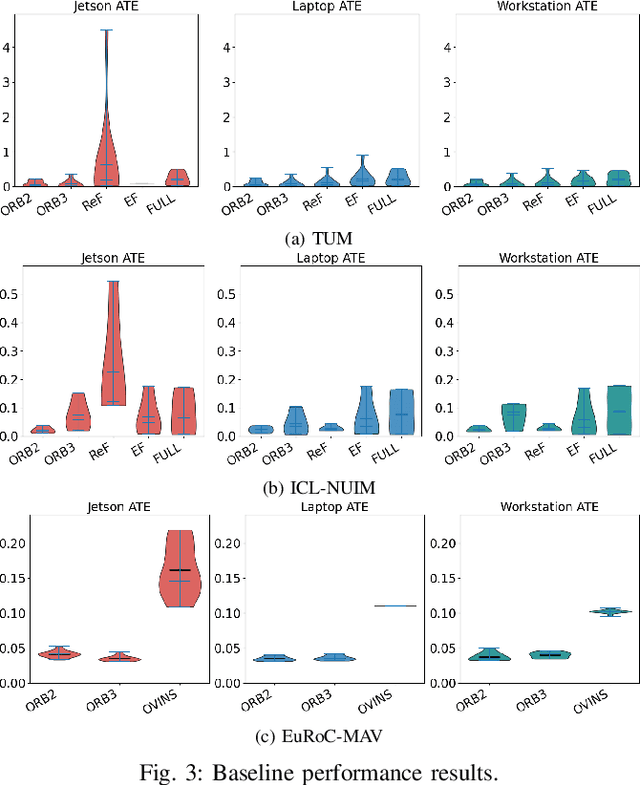
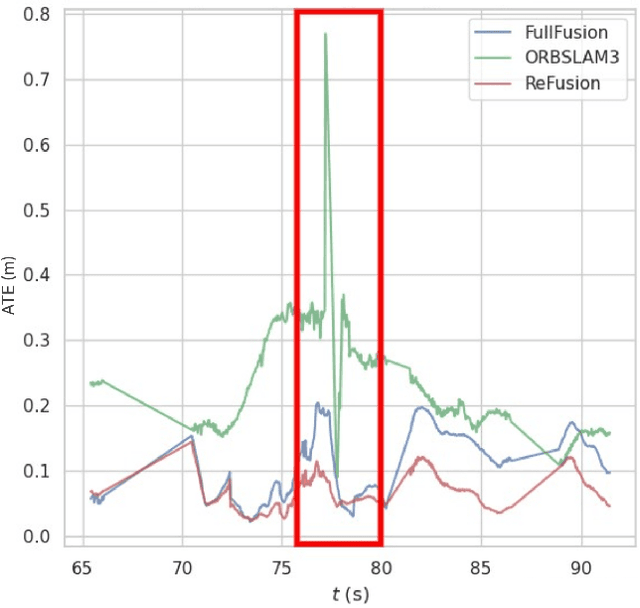
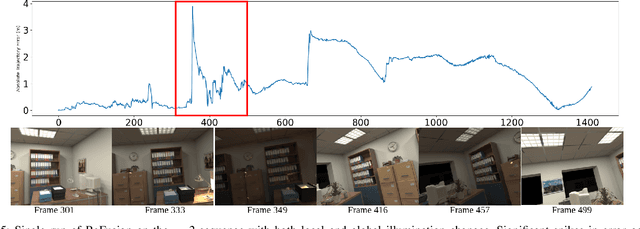
Progress in the last decade has brought about significant improvements in the accuracy and speed of SLAM systems, broadening their mapping capabilities. Despite these advancements, long-term operation remains a major challenge, primarily due to the wide spectrum of perturbations robotic systems may encounter. Increasing the robustness of SLAM algorithms is an ongoing effort, however it usually addresses a specific perturbation. Generalisation of robustness across a large variety of challenging scenarios is not well-studied nor understood. This paper presents a systematic evaluation of the robustness of open-source state-of-the-art SLAM algorithms with respect to challenging conditions such as fast motion, non-uniform illumination, and dynamic scenes. The experiments are performed with perturbations present both independently of each other, as well as in combination in long-term deployment settings in unconstrained environments (lifelong operation).
Energy Predictive Models for Convolutional Neural Networks on Mobile Platforms
Apr 10, 2020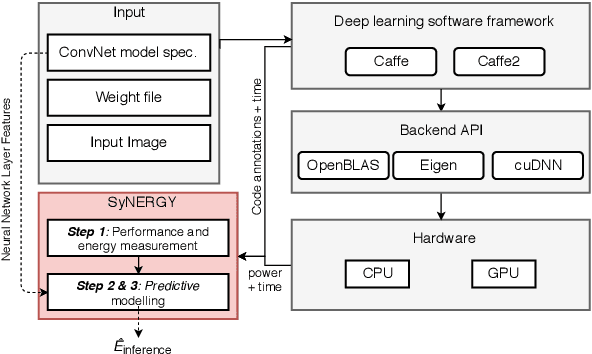
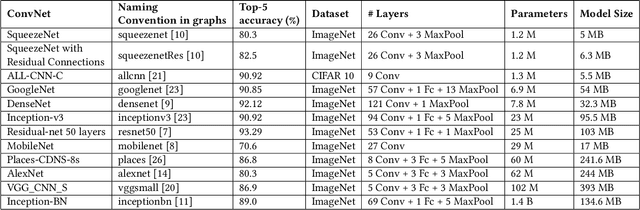
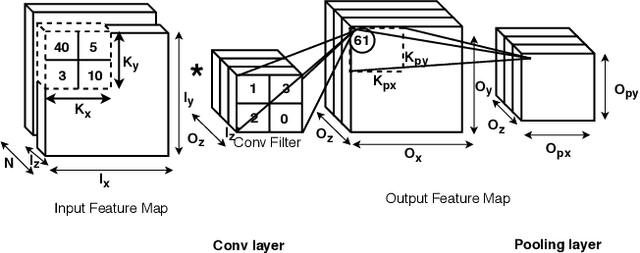

Energy use is a key concern when deploying deep learning models on mobile and embedded platforms. Current studies develop energy predictive models based on application-level features to provide researchers a way to estimate the energy consumption of their deep learning models. This information is useful for building resource-aware models that can make efficient use of the hard-ware resources. However, previous works on predictive modelling provide little insight into the trade-offs involved in the choice of features on the final predictive model accuracy and model complexity. To address this issue, we provide a comprehensive analysis of building regression-based predictive models for deep learning on mobile devices, based on empirical measurements gathered from the SyNERGY framework.Our predictive modelling strategy is based on two types of predictive models used in the literature:individual layers and layer-type. Our analysis of predictive models show that simple layer-type features achieve a model complexity of 4 to 32 times less for convolutional layer predictions for a similar accuracy compared to predictive models using more complex features adopted by previous approaches. To obtain an overall energy estimate of the inference phase, we build layer-type predictive models for the fully-connected and pooling layers using 12 representative Convolutional NeuralNetworks (ConvNets) on the Jetson TX1 and the Snapdragon 820using software backends such as OpenBLAS, Eigen and CuDNN. We obtain an accuracy between 76% to 85% and a model complexity of 1 for the overall energy prediction of the test ConvNets across different hardware-software combinations.
Joint Training of Neural Network Ensembles
Feb 26, 2019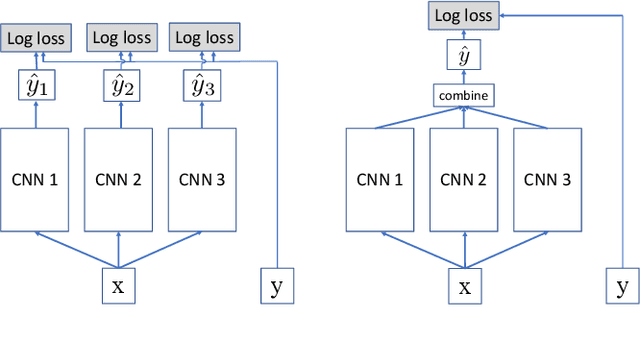

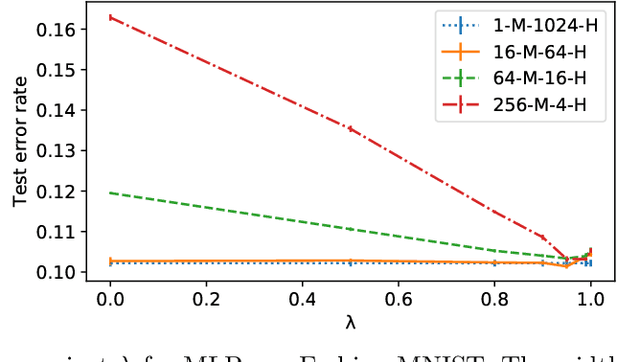
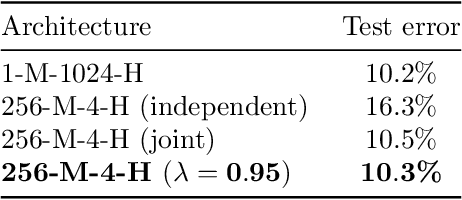
We examine the practice of joint training for neural network ensembles, in which a multi-branch architecture is trained via single loss. This approach has recently gained traction, with claims of greater accuracy per parameter along with increased parallelism. We introduce a family of novel loss functions generalizing multiple previously proposed approaches, with which we study theoretical and empirical properties of joint training. These losses interpolate smoothly between independent and joint training of predictors, demonstrating that joint training has several disadvantages not observed in prior work. However, with appropriate regularization via our proposed loss, the method shows new promise in resource limited scenarios and fault-tolerant systems, e.g., IoT and edge devices. Finally, we discuss how these results may have implications for general multi-branch architectures such as ResNeXt and Inception.