 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Classifier Circuits: Evolving Accelerators for Tabular Data
Paper and Code
Feb 28, 2023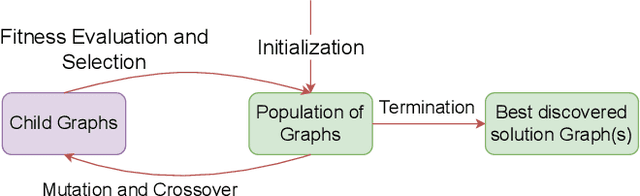
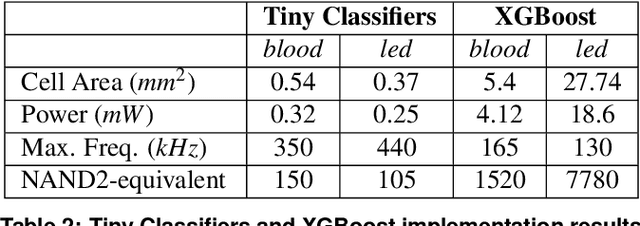
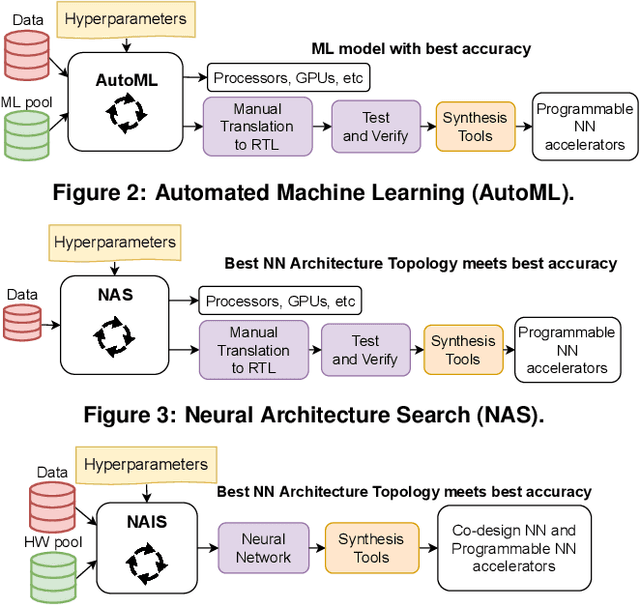
A typical machine learning (ML) development cycle for edge computing is to maximise the performance during model training and then minimise the memory/area footprint of the trained model for deployment on edge devices targeting CPUs, GPUs, microcontrollers, or custom hardware accelerators. This paper proposes a methodology for automatically generating predictor circuits for classification of tabular data with comparable prediction performance to conventional ML techniques while using substantially fewer hardware resources and power. The proposed methodology uses an evolutionary algorithm to search over the space of logic gates and automatically generates a classifier circuit with maximised training prediction accuracy. Classifier circuits are so tiny (i.e., consisting of no more than 300 logic gates) that they are called "Tiny Classifier" circuits, and can efficiently be implemented in ASIC or on an FPGA. We empirically evaluate the automatic Tiny Classifier circuit generation methodology or "Auto Tiny Classifiers" on a wide range of tabular datasets, and compare it against conventional ML techniques such as Amazon's AutoGluon, Google's TabNet and a neural search over Multi-Layer Perceptrons. Despite Tiny Classifiers being constrained to a few hundred logic gates, we observe no statistically significant difference in prediction performance in comparison to the best-performing ML baseline. When synthesised as a Silicon chip, Tiny Classifiers use 8-56x less area and 4-22x less power. When implemented as an ultra-low cost chip on a flexible substrate (i.e., FlexIC), they occupy 10-75x less area and consume 13-75x less power compared to the most hardware-efficient ML baseline. On an FPGA, Tiny Classifiers consume 3-11x fewer resources.