 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian inference of a new Mallows model for characterising symptom sequences applied in primary progressive aphasia
Nov 22, 2023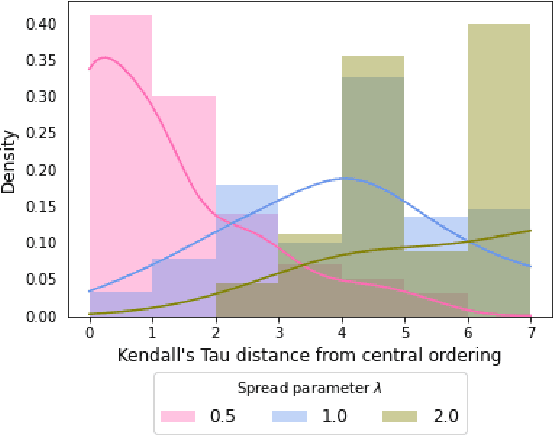
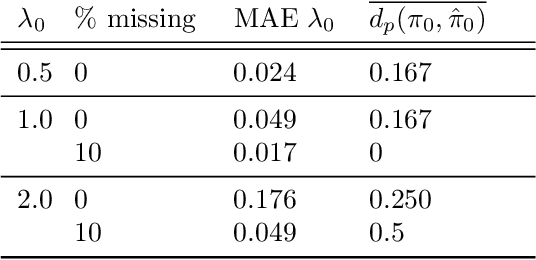
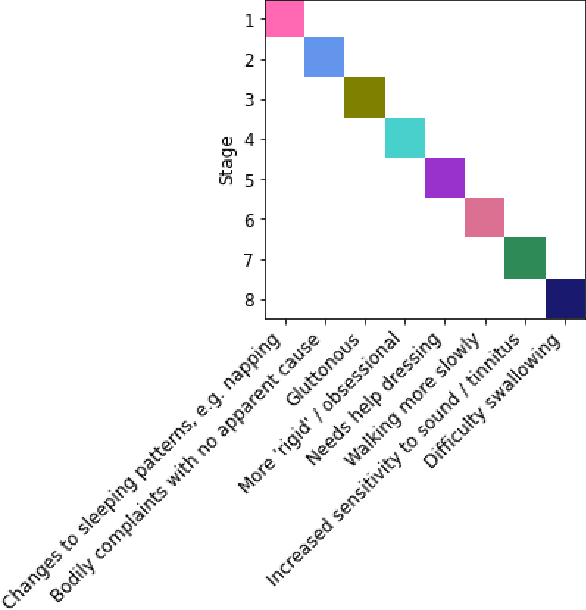
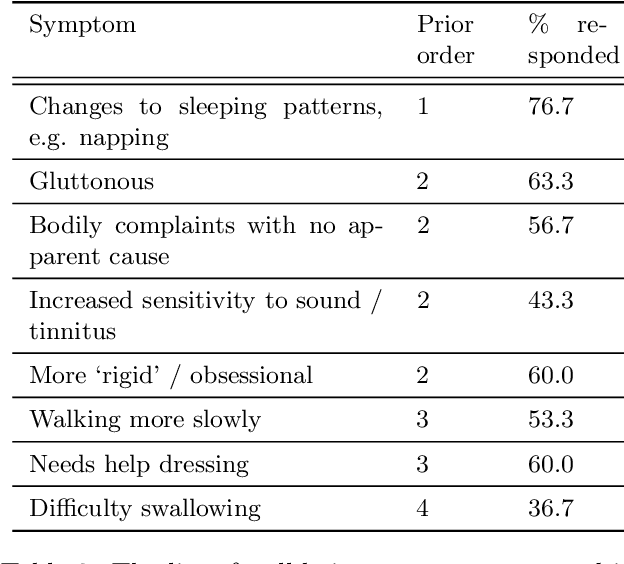
Machine learning models offer the potential to understand diverse datasets in a data-driven way, powering insights into individual disease experiences and ensuring equitable healthcare. In this study, we explore Bayesian inference for characterising symptom sequences, and the associated modelling challenges. We adapted the Mallows model to account for partial rankings and right-censored data, employing custom MCMC fitting. Our evaluation, encompassing synthetic data and a primary progressive aphasia dataset, highlights the model's efficacy in revealing mean orderings and estimating ranking variance. This holds the potential to enhance clinical comprehension of symptom occurrence. However, our work encounters limitations concerning model scalability and small dataset sizes.
Artificial Intelligence for Dementia Research Methods Optimization
Mar 02, 2023Introduction: Machine learning (ML) has been extremely successful in identifying key features from high-dimensional datasets and executing complicated tasks with human expert levels of accuracy or greater. Methods: We summarize and critically evaluate current applications of ML in dementia research and highlight directions for future research. Results: We present an overview of ML algorithms most frequently used in dementia research and highlight future opportunities for the use of ML in clinical practice, experimental medicine, and clinical trials. We discuss issues of reproducibility, replicability and interpretability and how these impact the clinical applicability of dementia research. Finally, we give examples of how state-of-the-art methods, such as transfer learning, multi-task learning, and reinforcement learning, may be applied to overcome these issues and aid the translation of research to clinical practice in the future. Discussion: ML-based models hold great promise to advance our understanding of the underlying causes and pathological mechanisms of dementia.
HAWKS: Evolving Challenging Benchmark Sets for Cluster Analysis
Feb 13, 2021
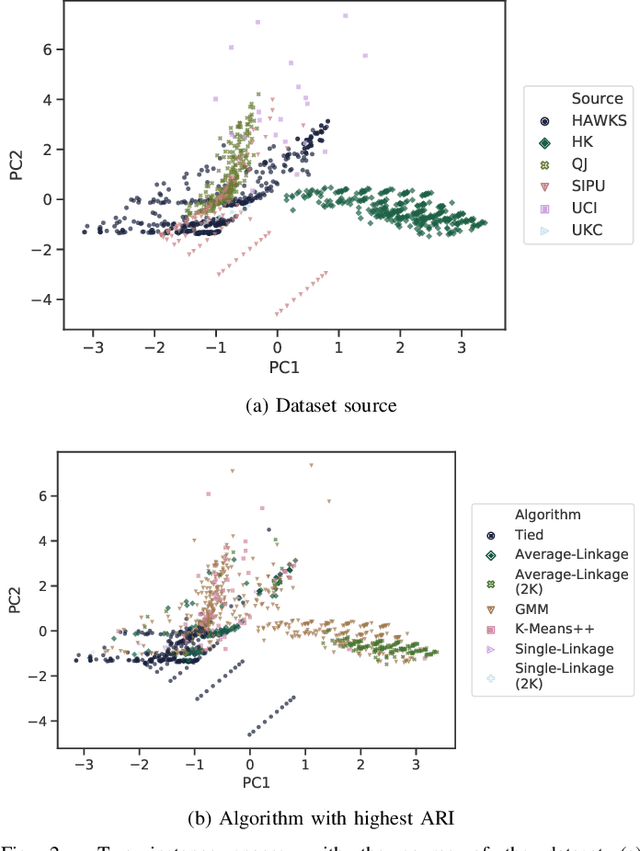
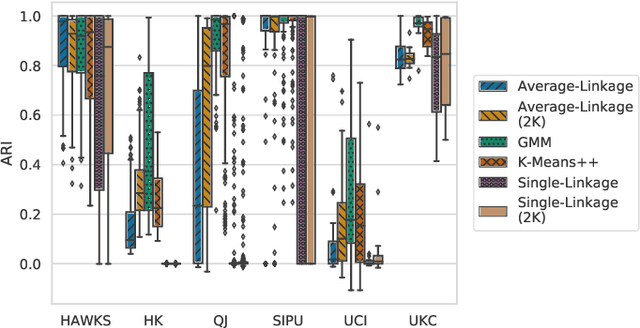

Comprehensive benchmarking of clustering algorithms is rendered difficult by two key factors: (i)~the elusiveness of a unique mathematical definition of this unsupervised learning approach and (ii)~dependencies between the generating models or clustering criteria adopted by some clustering algorithms and indices for internal cluster validation. Consequently, there is no consensus regarding the best practice for rigorous benchmarking, and whether this is possible at all outside the context of a given application. Here, we argue that synthetic datasets must continue to play an important role in the evaluation of clustering algorithms, but that this necessitates constructing benchmarks that appropriately cover the diverse set of properties that impact clustering algorithm performance. Through our framework, HAWKS, we demonstrate the important role evolutionary algorithms play to support flexible generation of such benchmarks, allowing simple modification and extension. We illustrate two possible uses of our framework: (i)~the evolution of benchmark data consistent with a set of hand-derived properties and (ii)~the generation of datasets that tease out performance differences between a given pair of algorithms. Our work has implications for the design of clustering benchmarks that sufficiently challenge a broad range of algorithms, and for furthering insight into the strengths and weaknesses of specific approaches.