 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Interaction Data to Predict Engagement with Interactive Media
Aug 04, 2021
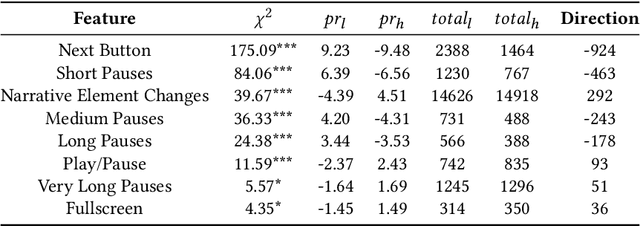
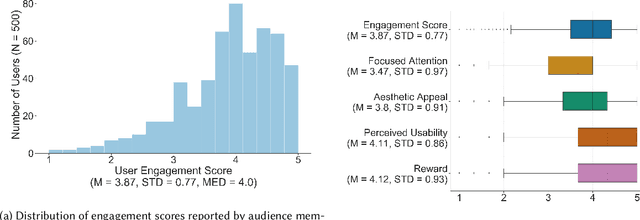
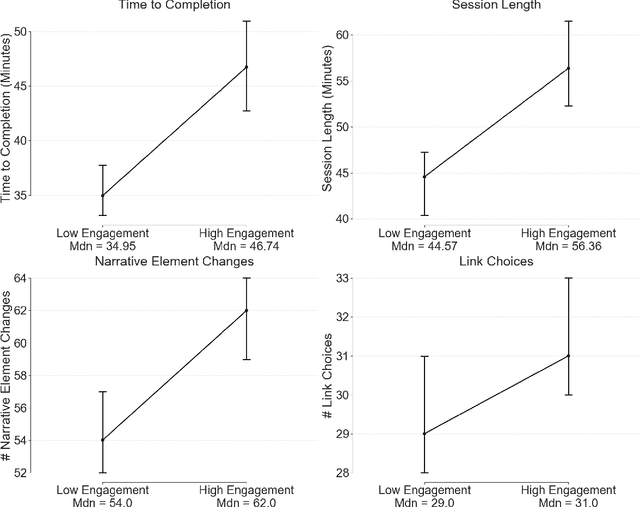
Media is evolving from traditional linear narratives to personalised experiences, where control over information (or how it is presented) is given to individual audience members. Measuring and understanding audience engagement with this media is important in at least two ways: (1) a post-hoc understanding of how engaged audiences are with the content will help production teams learn from experience and improve future productions; (2), this type of media has potential for real-time measures of engagement to be used to enhance the user experience by adapting content on-the-fly. Engagement is typically measured by asking samples of users to self-report, which is time consuming and expensive. In some domains, however, interaction data have been used to infer engagement. Fortuitously, the nature of interactive media facilitates a much richer set of interaction data than traditional media; our research aims to understand if these data can be used to infer audience engagement. In this paper, we report a study using data captured from audience interactions with an interactive TV show to model and predict engagement. We find that temporal metrics, including overall time spent on the experience and the interval between events, are predictive of engagement. The results demonstrate that interaction data can be used to infer users' engagement during and after an experience, and the proposed techniques are relevant to better understand audience preference and responses.
Adaptive Weighting Scheme for Automatic Time-Series Data Augmentation
Feb 16, 2021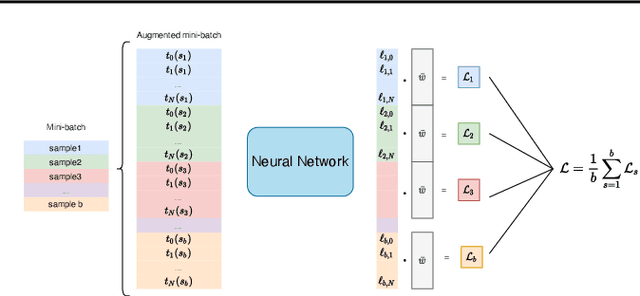
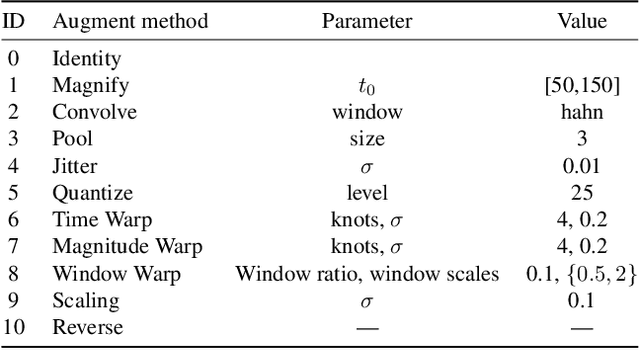
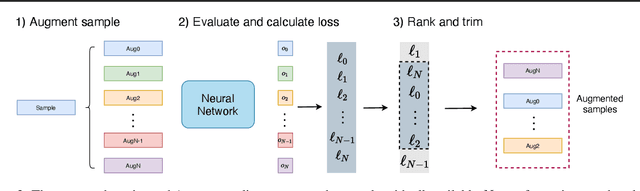
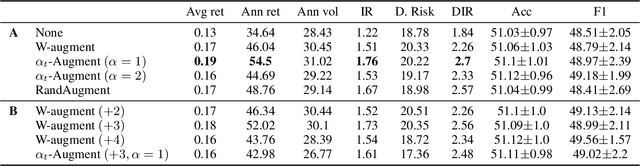
Data augmentation methods have been shown to be a fundamental technique to improve generalization in tasks such as image, text and audio classification. Recently, automated augmentation methods have led to further improvements on image classification and object detection leading to state-of-the-art performances. Nevertheless, little work has been done on time-series data, an area that could greatly benefit from automated data augmentation given the usually limited size of the datasets. We present two sample-adaptive automatic weighting schemes for data augmentation: the first learns to weight the contribution of the augmented samples to the loss, and the second method selects a subset of transformations based on the ranking of the predicted training loss. We validate our proposed methods on a large, noisy financial dataset and on time-series datasets from the UCR archive. On the financial dataset, we show that the methods in combination with a trading strategy lead to improvements in annualized returns of over 50$\%$, and on the time-series data we outperform state-of-the-art models on over half of the datasets, and achieve similar performance in accuracy on the others.
HAWKS: Evolving Challenging Benchmark Sets for Cluster Analysis
Feb 13, 2021
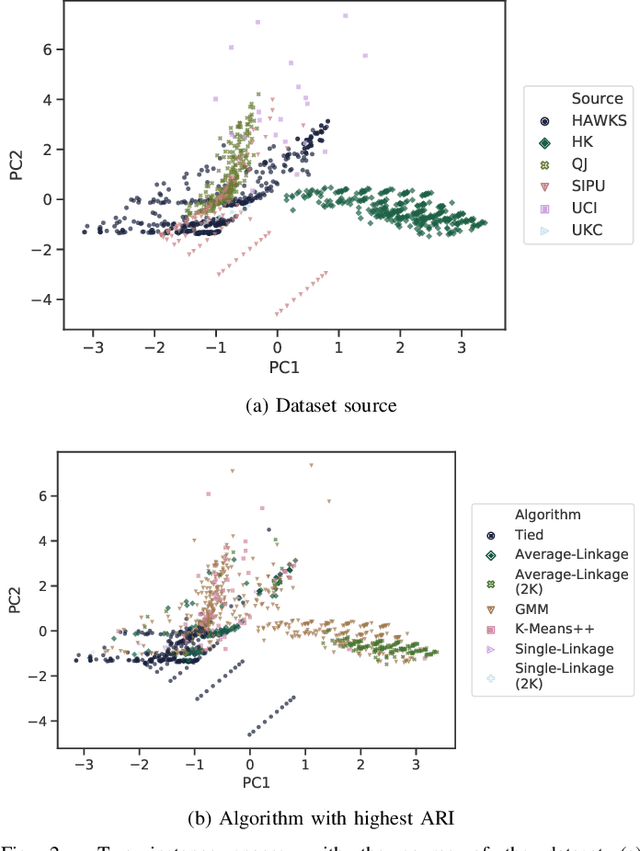
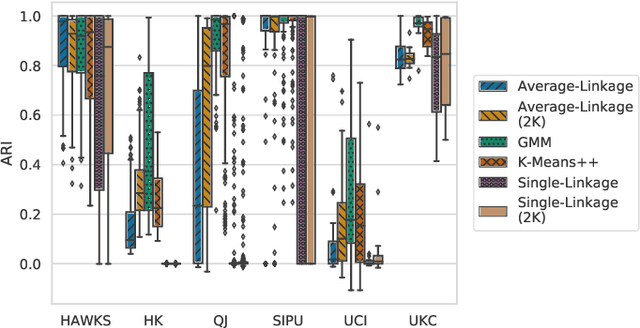

Comprehensive benchmarking of clustering algorithms is rendered difficult by two key factors: (i)~the elusiveness of a unique mathematical definition of this unsupervised learning approach and (ii)~dependencies between the generating models or clustering criteria adopted by some clustering algorithms and indices for internal cluster validation. Consequently, there is no consensus regarding the best practice for rigorous benchmarking, and whether this is possible at all outside the context of a given application. Here, we argue that synthetic datasets must continue to play an important role in the evaluation of clustering algorithms, but that this necessitates constructing benchmarks that appropriately cover the diverse set of properties that impact clustering algorithm performance. Through our framework, HAWKS, we demonstrate the important role evolutionary algorithms play to support flexible generation of such benchmarks, allowing simple modification and extension. We illustrate two possible uses of our framework: (i)~the evolution of benchmark data consistent with a set of hand-derived properties and (ii)~the generation of datasets that tease out performance differences between a given pair of algorithms. Our work has implications for the design of clustering benchmarks that sufficiently challenge a broad range of algorithms, and for furthering insight into the strengths and weaknesses of specific approaches.
Evaluating data augmentation for financial time series classification
Oct 28, 2020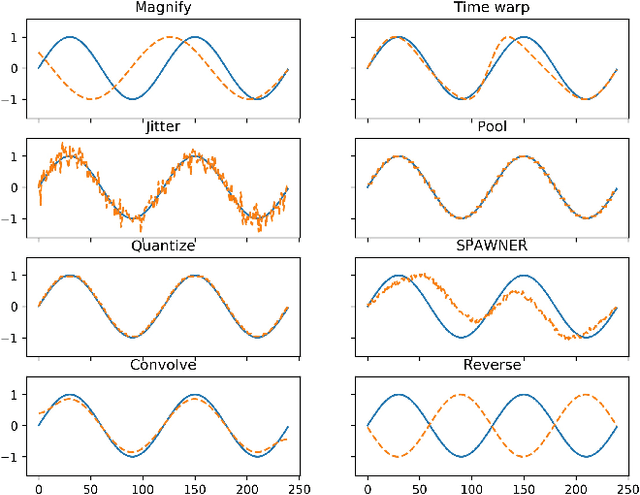
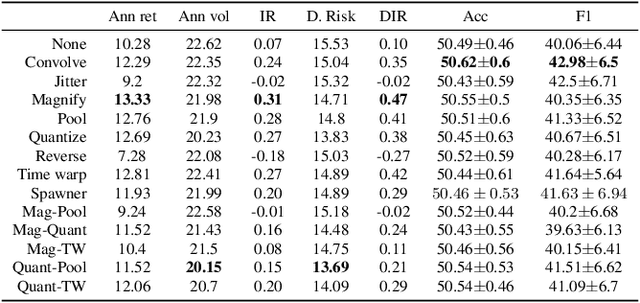
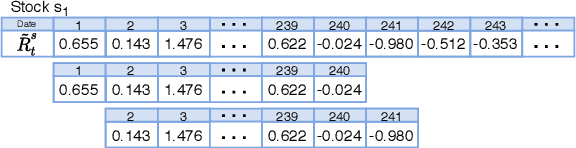
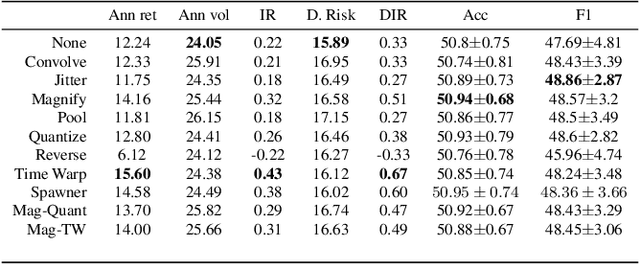
Data augmentation methods in combination with deep neural networks have been used extensively in computer vision on classification tasks, achieving great success; however, their use in time series classification is still at an early stage. This is even more so in the field of financial prediction, where data tends to be small, noisy and non-stationary. In this paper we evaluate several augmentation methods applied to stocks datasets using two state-of-the-art deep learning models. The results show that several augmentation methods significantly improve financial performance when used in combination with a trading strategy. For a relatively small dataset ($\approx30K$ samples), augmentation methods achieve up to $400\%$ improvement in risk adjusted return performance; for a larger stock dataset ($\approx300K$ samples), results show up to $40\%$ improvement.
A novel dynamic asset allocation system using Feature Saliency Hidden Markov models for smart beta investing
Feb 28, 2019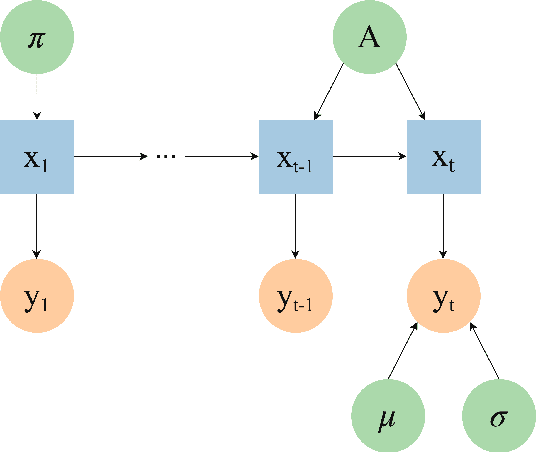
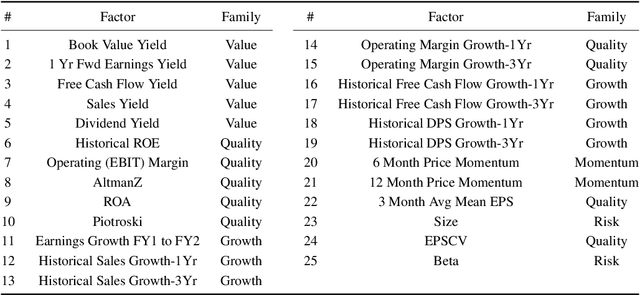
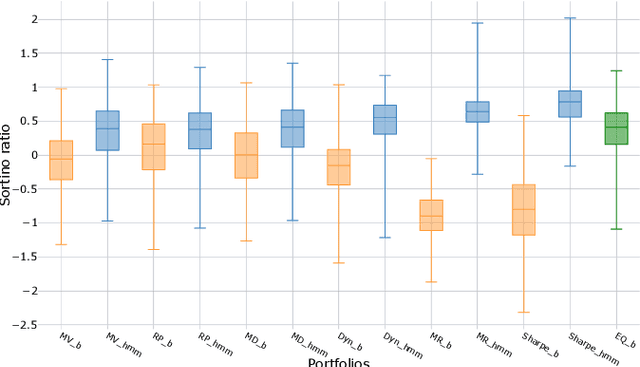
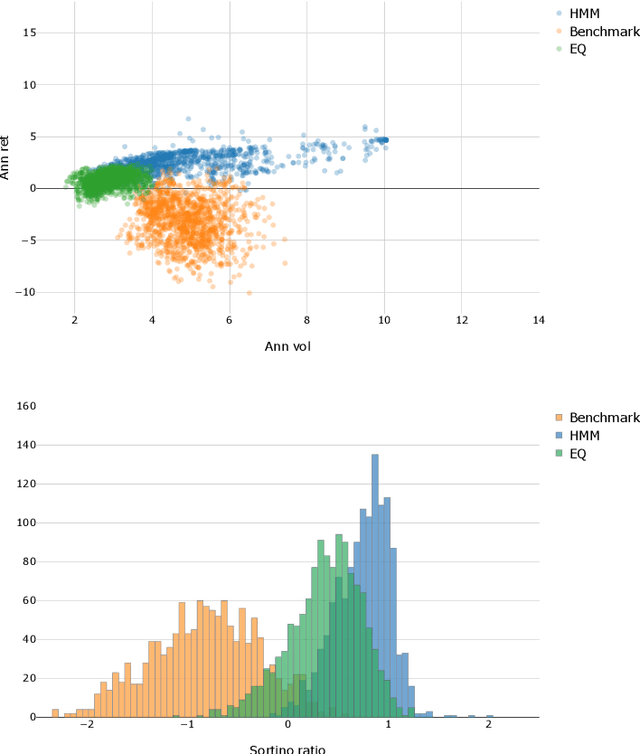
The financial crisis of 2008 generated interest in more transparent, rules-based strategies for portfolio construction, with Smart beta strategies emerging as a trend among institutional investors. While they perform well in the long run, these strategies often suffer from severe short-term drawdown (peak-to-trough decline) with fluctuating performance across cycles. To address cyclicality and underperformance, we build a dynamic asset allocation system using Hidden Markov Models (HMMs). We test our system across multiple combinations of smart beta strategies and the resulting portfolios show an improvement in risk-adjusted returns, especially on more return oriented portfolios (up to 50$\%$ in excess of market annually). In addition, we propose a novel smart beta allocation system based on the Feature Saliency HMM (FSHMM) algorithm that performs feature selection simultaneously with the training of the HMM, to improve regime identification. We evaluate our systematic trading system with real life assets using MSCI indices; further, the results (up to 60$\%$ in excess of market annually) show model performance improvement with respect to portfolios built using full feature HMMs.
Breaking the Activation Function Bottleneck through Adaptive Parameterization
Jul 09, 2018

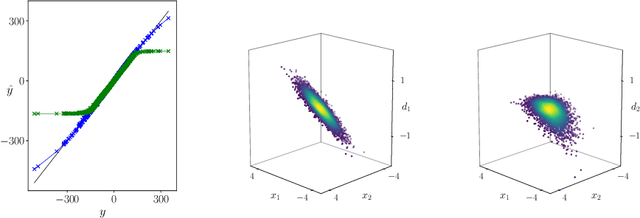
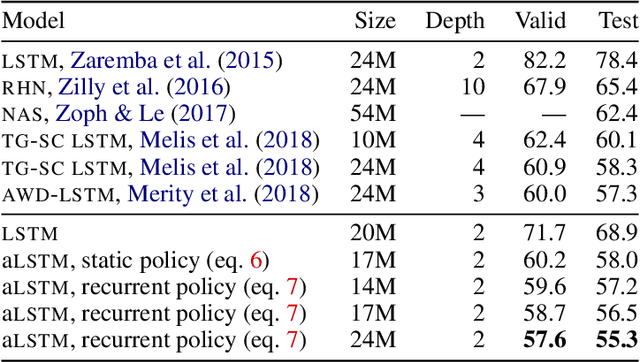
Standard neural network architectures are non-linear only by virtue of a simple element-wise activation function, making them both brittle and excessively large. In this paper, we consider methods for making the feed-forward layer more flexible while preserving its basic structure. We develop simple drop-in replacements that learn to adapt their parameterization conditional on the input, thereby increasing statistical efficiency significantly. We present an adaptive LSTM that advances the state of the art for the Penn Treebank and WikiText-2 word-modeling tasks while using fewer parameters and converging in less than half as many iterations.