 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Weighting Scheme for Automatic Time-Series Data Augmentation
Paper and Code
Feb 16, 2021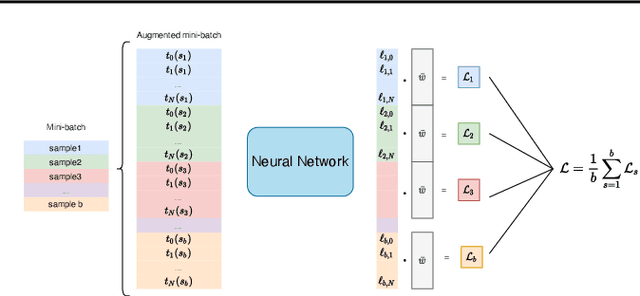
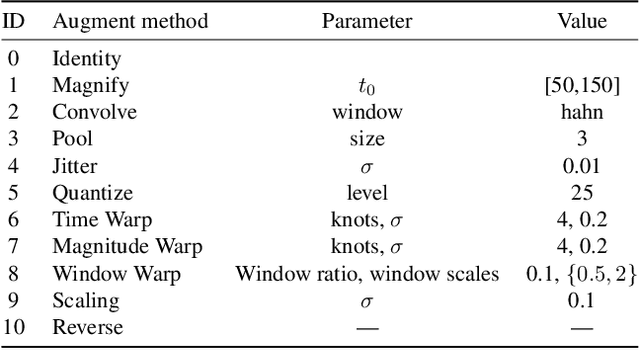
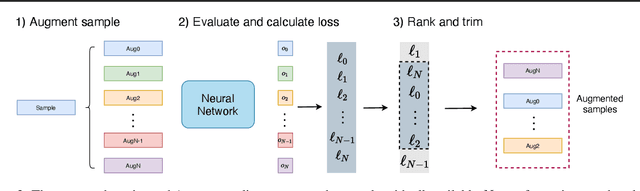
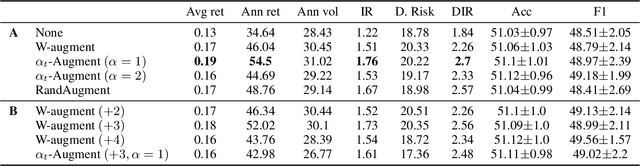
Data augmentation methods have been shown to be a fundamental technique to improve generalization in tasks such as image, text and audio classification. Recently, automated augmentation methods have led to further improvements on image classification and object detection leading to state-of-the-art performances. Nevertheless, little work has been done on time-series data, an area that could greatly benefit from automated data augmentation given the usually limited size of the datasets. We present two sample-adaptive automatic weighting schemes for data augmentation: the first learns to weight the contribution of the augmented samples to the loss, and the second method selects a subset of transformations based on the ranking of the predicted training loss. We validate our proposed methods on a large, noisy financial dataset and on time-series datasets from the UCR archive. On the financial dataset, we show that the methods in combination with a trading strategy lead to improvements in annualized returns of over 50$\%$, and on the time-series data we outperform state-of-the-art models on over half of the datasets, and achieve similar performance in accuracy on the others.