 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Paper and Code
Nov 16, 2023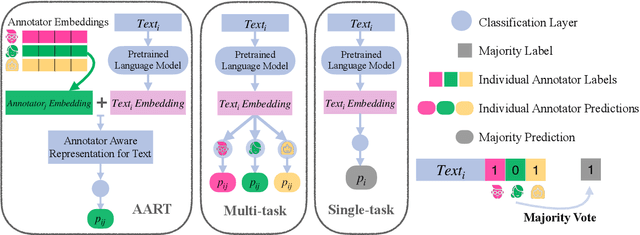
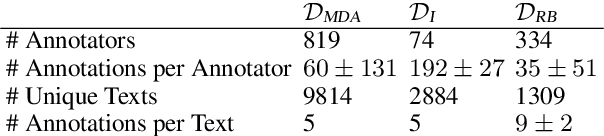
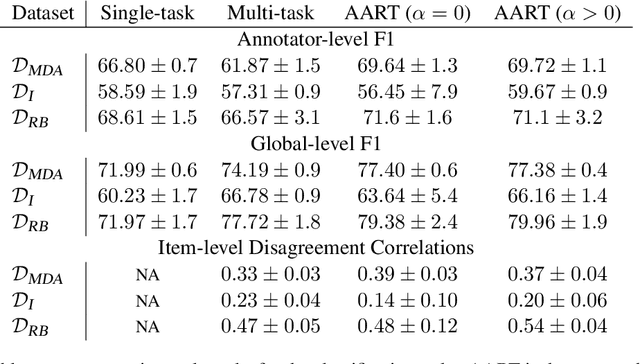
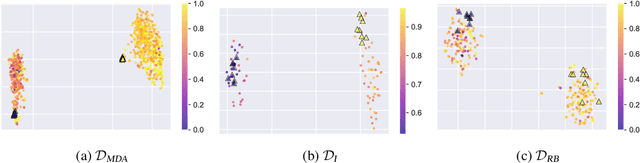
In most classification models, it has been assumed to have a single ground truth label for each data point. However, subjective tasks like toxicity classification can lead to genuine disagreement among annotators. In these cases aggregating labels will result in biased labeling and, consequently, biased models that can overlook minority opinions. Previous studies have shed light on the pitfalls of label aggregation and have introduced a handful of practical approaches to tackle this issue. Recently proposed multi-annotator models, which predict labels individually per annotator, are vulnerable to under-determination for annotators with small samples. This problem is especially the case in crowd-sourced datasets. In this work, we propose Annotator Aware Representations for Texts (AART) for subjective classification tasks. We will show the improvement of our method on metrics that assess the performance on capturing annotators' perspectives. Additionally, our approach involves learning representations for annotators, allowing for an exploration of the captured annotation behaviors.