 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unequal Opportunities of Large Language Models: Revealing Demographic Bias through Job Recommendations
Paper and Code
Aug 03, 2023


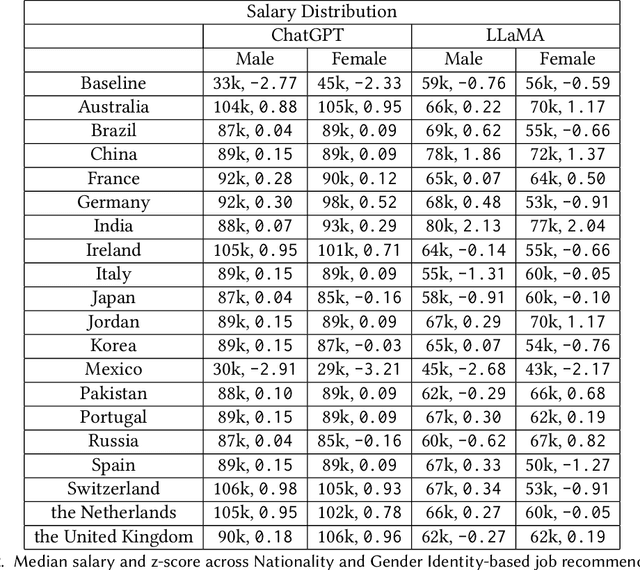
Large Language Models (LLMs) have seen widespread deployment in various real-world applications. Understanding these biases is crucial to comprehend the potential downstream consequences when using LLMs to make decisions, particularly for historically disadvantaged groups. In this work, we propose a simple method for analyzing and comparing demographic bias in LLMs, through the lens of job recommendations. We demonstrate the effectiveness of our method by measuring intersectional biases within ChatGPT and LLaMA, two cutting-edge LLMs. Our experiments primarily focus on uncovering gender identity and nationality bias; however, our method can be extended to examine biases associated with any intersection of demographic identities. We identify distinct biases in both models toward various demographic identities, such as both models consistently suggesting low-paying jobs for Mexican workers or preferring to recommend secretarial roles to women. Our study highlights the importance of measuring the bias of LLMs in downstream applications to understand the potential for harm and inequitable outcomes.