 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-friendly Comparison of Similarity Algorithms on Wikidata
Paper and Code
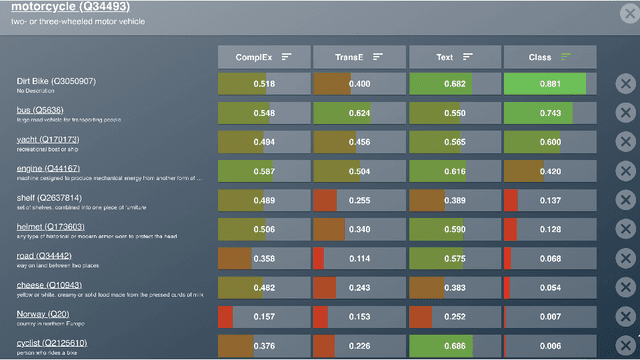
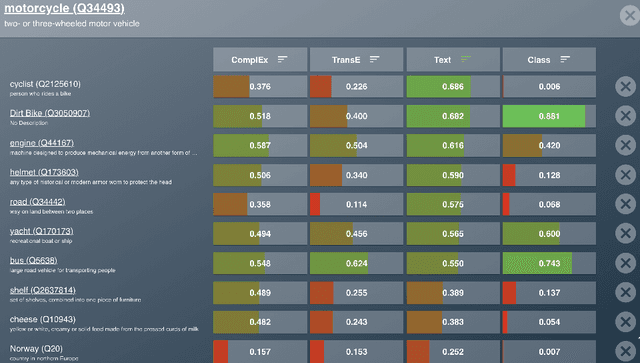
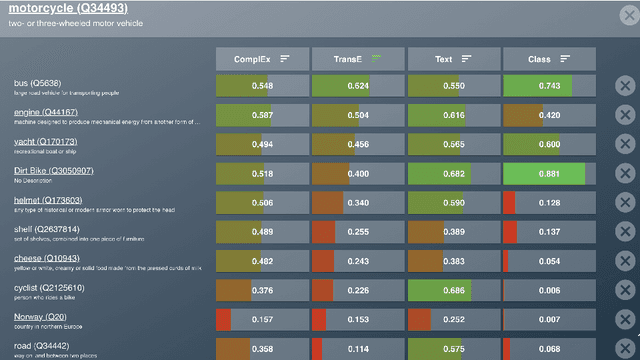
While the similarity between two concept words has been evaluated and studied for decades, much less attention has been devoted to algorithms that can compute the similarity of nodes in very large knowledge graphs, like Wikidata. To facilitate investigations and head-to-head comparisons of similarity algorithms on Wikidata, we present a user-friendly interface that allows flexible computation of similarity between Qnodes in Wikidata. At present, the similarity interface supports four algorithms, based on: graph embeddings (TransE, ComplEx), text embeddings (BERT), and class-based similarity. We demonstrate the behavior of the algorithms on representative examples about semantically similar, related, and entirely unrelated entity pairs. To support anticipated applications that require efficient similarity computations, like entity linking and recommendation, we also provide a REST API that can compute most similar neighbors for any Qnode in Wikidata.