 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Knowledge Graphs for Better Link Prediction
Paper and Code
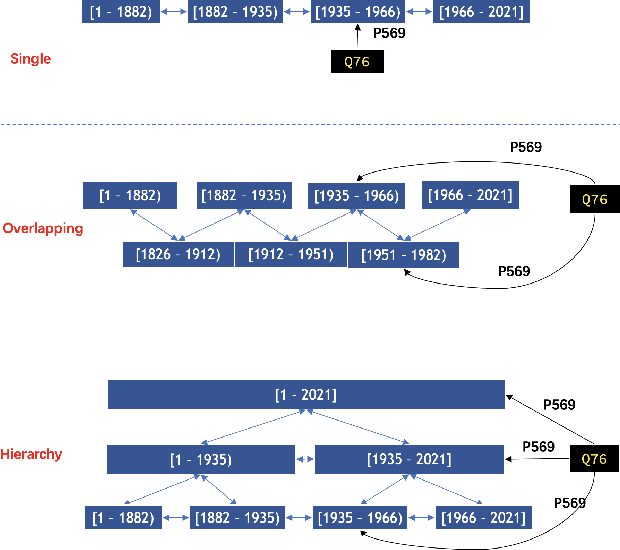

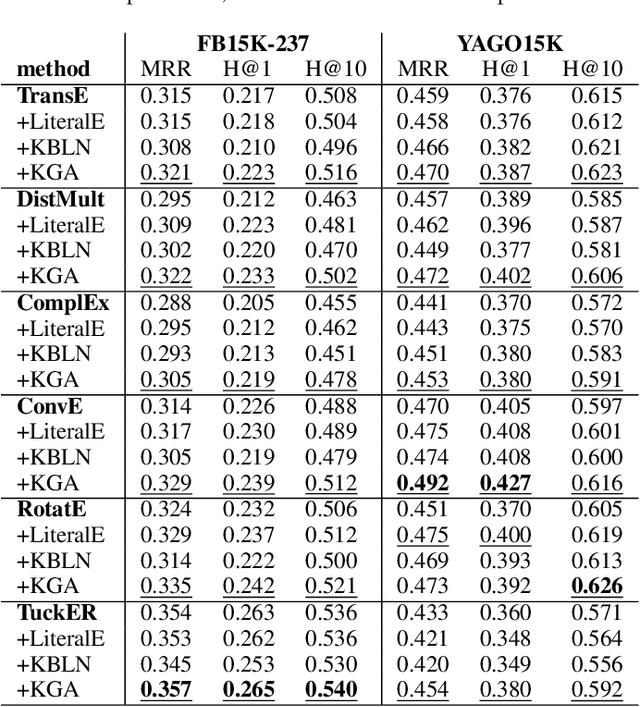
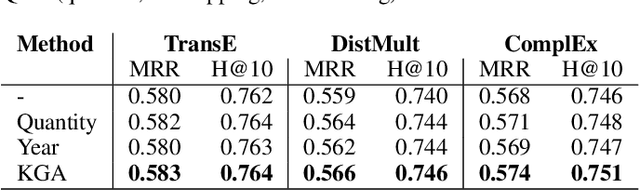
Embedding methods have demonstrated robust performance on the task of link prediction in knowledge graphs, by mostly encoding entity relationships. Recent methods propose to enhance the loss function with a literal-aware term. In this paper, we propose KGA: a knowledge graph augmentation method that incorporates literals in an embedding model without modifying its loss function. KGA discretizes quantity and year values into bins, and chains these bins both horizontally, modeling neighboring values, and vertically, modeling multiple levels of granularity. KGA is scalable and can be used as a pre-processing step for any existing knowledge graph embedding model. Experiments on legacy benchmarks and a new large benchmark, DWD, show that augmenting the knowledge graph with quantities and years is beneficial for predicting both entities and numbers, as KGA outperforms the vanilla models and other relevant baselines. Our ablation studies confirm that both quantities and years contribute to KGA's performance, and that its performance depends on the discretization and binning settings. We make the code, models, and the DWD benchmark publicly available to facilitate reproducibility and future research.