 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Wikidata with Linked Open Data
Paper and Code
Jul 01, 2022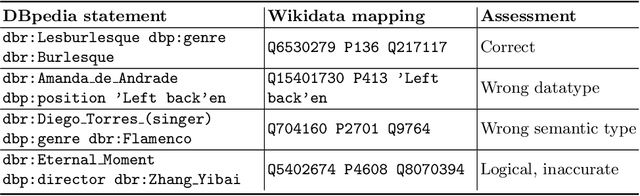
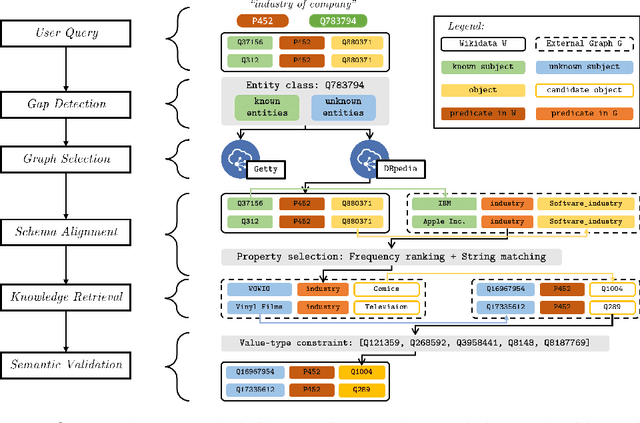


Large public knowledge graphs, like Wikidata, contain billions of statements about tens of millions of entities, thus inspiring various use cases to exploit such knowledge graphs. However, practice shows that much of the relevant information that fits users' needs is still missing in Wikidata, while current linked open data (LOD) tools are not suitable to enrich large graphs like Wikidata. In this paper, we investigate the potential of enriching Wikidata with structured data sources from the LOD cloud. We present a novel workflow that includes gap detection, source selection, schema alignment, and semantic validation. We evaluate our enrichment method with two complementary LOD sources: a noisy source with broad coverage, DBpedia, and a manually curated source with narrow focus on the art domain, Getty. Our experiments show that our workflow can enrich Wikidata with millions of novel statements from external LOD sources with a high quality. Property alignment and data quality are key challenges, whereas entity alignment and source selection are well-supported by existing Wikidata mechanisms. We make our code and data available to support future work.