 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage, Time Preferences, and Consumer Behavior: Evidence from Large Language Models
Paper and Code
May 04, 2023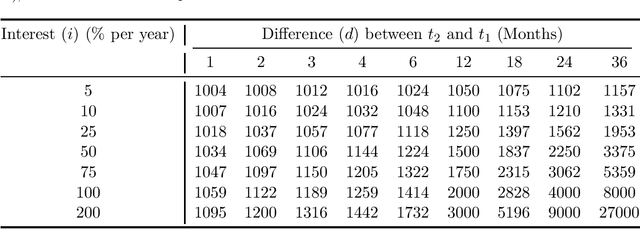


Language has a strong influence on our perceptions of time and rewards. This raises the question of whether large language models, when asked in different languages, show different preferences for rewards over time and if their choices are similar to those of humans. In this study, we analyze the responses of GPT-3.5 (hereafter referred to as GPT) to prompts in multiple languages, exploring preferences between smaller, sooner rewards and larger, later rewards. Our results show that GPT displays greater patience when prompted in languages with weak future tense references (FTR), such as German and Mandarin, compared to languages with strong FTR, like English and French. These findings are consistent with existing literature and suggest a correlation between GPT's choices and the preferences of speakers of these languages. However, further analysis reveals that the preference for earlier or later rewards does not systematically change with reward gaps, indicating a lexicographic preference for earlier payments. While GPT may capture intriguing variations across languages, our findings indicate that the choices made by these models do not correspond to those of human decision-makers.