 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient, Limb Position-Aware Hand Gesture Recognition using Hyperdimensional Computing
Mar 09, 2021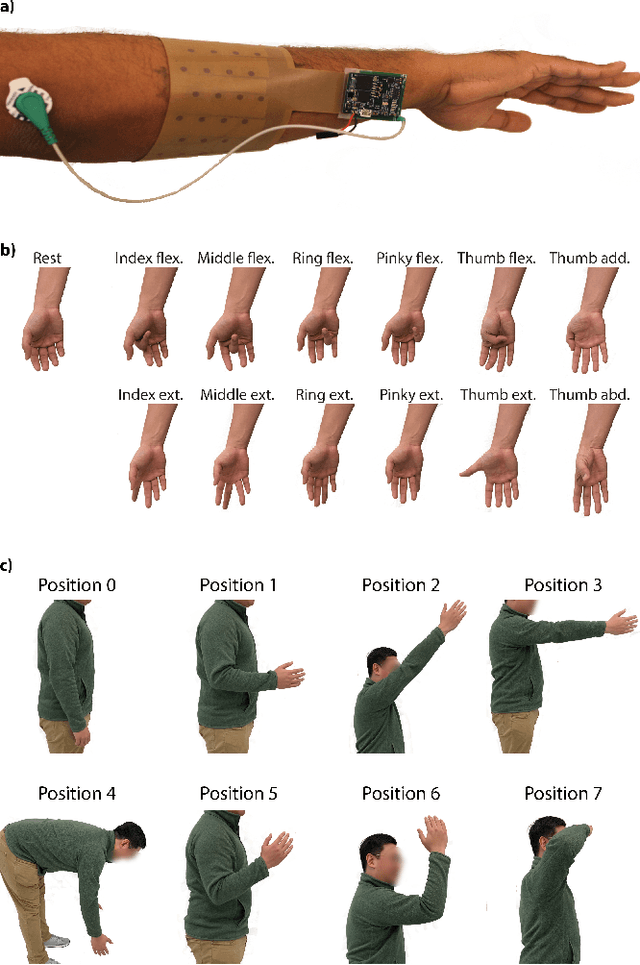

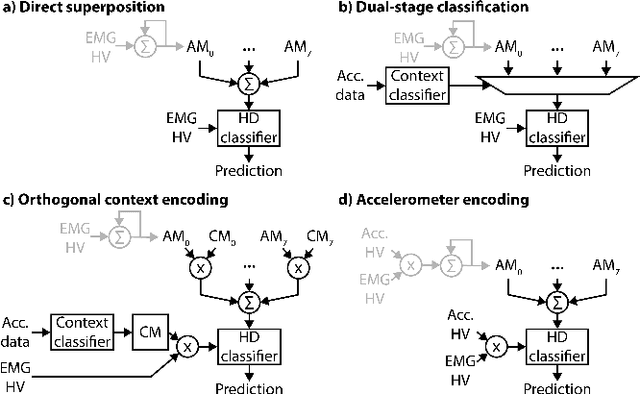
Electromyogram (EMG) pattern recognition can be used to classify hand gestures and movements for human-machine interface and prosthetics applications, but it often faces reliability issues resulting from limb position change. One method to address this is dual-stage classification, in which the limb position is first determined using additional sensors to select between multiple position-specific gesture classifiers. While improving performance, this also increases model complexity and memory footprint, making a dual-stage classifier difficult to implement in a wearable device with limited resources. In this paper, we present sensor fusion of accelerometer and EMG signals using a hyperdimensional computing model to emulate dual-stage classification in a memory-efficient way. We demonstrate two methods of encoding accelerometer features to act as keys for retrieval of position-specific parameters from multiple models stored in superposition. Through validation on a dataset of 13 gestures in 8 limb positions, we obtain a classification accuracy of up to 93.34%, an improvement of 17.79% over using a model trained solely on EMG. We achieve this while only marginally increasing memory footprint over a single limb position model, requiring $8\times$ less memory than a traditional dual-stage classification architecture.
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 12, 2021



Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.