 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECLASS-Augmented Semantic Product Search for Electronic Components
Apr 21, 2026Efficient semantic access to industrial product data is a key enabler for factory automation and emerging LLM-based agent workflows, where both human engineers and autonomous agents must identify suitable components from highly structured catalogs. However, the vocabulary mismatch between natural-language queries and attribute-centric product descriptions limits the effectiveness of traditional retrieval approaches, e.g., BM25. In this work, we present a systematic evaluation of LLM-assisted dense retrieval for semantic product search on industrial electronic components, and investigate the integration of hierarchical semantics from the ECLASS standard into embedding-based retrieval. Our results show that dense retrieval combined with re-ranking substantially outperforms classical lexical methods and foundation model web-search baselines. In particular, the proposed approach achieves a Hit_Rate@5 of 94.3 %, compared to 31.4 % for BM25 on expert queries, while also exceeding foundation model baselines in both effectiveness and efficiency. Furthermore, augmenting product representations with ECLASS semantics yields consistent performance gains across configurations, demonstrating that standardized hierarchical metadata provides a crucial semantic bridge between user intent and sparse product descriptions.
Comparing EPGP Surrogates and Finite Elements Under Degree-of-Freedom Parity
Nov 06, 2025We present a new benchmarking study comparing a boundary-constrained Ehrenpreis--Palamodov Gaussian Process (B-EPGP) surrogate with a classical finite element method combined with Crank--Nicolson time stepping (CN-FEM) for solving the two-dimensional wave equation with homogeneous Dirichlet boundary conditions. The B-EPGP construction leverages exponential-polynomial bases derived from the characteristic variety to enforce the PDE and boundary conditions exactly and employs penalized least squares to estimate the coefficients. To ensure fairness across paradigms, we introduce a degrees-of-freedom (DoF) matching protocol. Under matched DoF, B-EPGP consistently attains lower space-time $L^2$-error and maximum-in-time $L^{2}$-error in space than CN-FEM, improving accuracy by roughly two orders of magnitude.
Generative Models for Long Time Series: Approximately Equivariant Recurrent Network Structures for an Adjusted Training Scheme
May 08, 2025



We present a simple yet effective generative model for time series data based on a Variational Autoencoder (VAE) with recurrent layers, referred to as the Recurrent Variational Autoencoder with Subsequent Training (RVAE-ST). Our method introduces an adapted training scheme that progressively increases the sequence length, addressing the challenge recurrent layers typically face when modeling long sequences. By leveraging the recurrent architecture, the model maintains a constant number of parameters regardless of sequence length. This design encourages approximate time-shift equivariance and enables efficient modeling of long-range temporal dependencies. Rather than introducing a fundamentally new architecture, we show that a carefully composed combination of known components can match or outperform state-of-the-art generative models on several benchmark datasets. Our model performs particularly well on time series that exhibit quasi-periodic structure,while remaining competitive on datasets with more irregular or partially non-stationary behavior. We evaluate its performance using ELBO, Fr\'echet Distance, discriminative scores, and visualizations of the learned embeddings.
Gaussian Process Regression for Inverse Problems in Linear PDEs
Feb 06, 2025



This paper introduces a computationally efficient algorithm in system theory for solving inverse problems governed by linear partial differential equations (PDEs). We model solutions of linear PDEs using Gaussian processes with priors defined based on advanced commutative algebra and algebraic analysis. The implementation of these priors is algorithmic and achieved using the Macaulay2 computer algebra software. An example application includes identifying the wave speed from noisy data for classical wave equations, which are widely used in physics. The method achieves high accuracy while enhancing computational efficiency.
Physics-informed Gaussian Processes as Linear Model Predictive Controller
Dec 02, 2024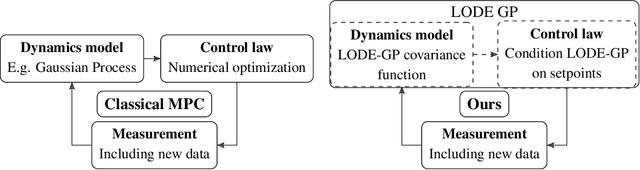

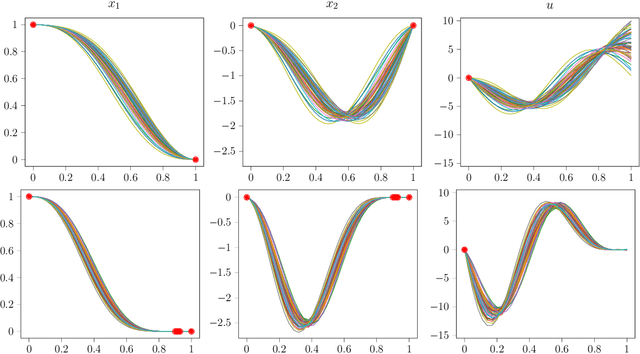
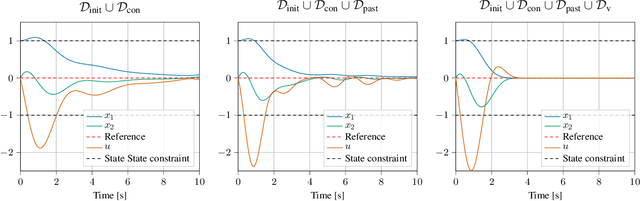
We introduce a novel algorithm for controlling linear time invariant systems in a tracking problem. The controller is based on a Gaussian Process (GP) whose realizations satisfy a system of linear ordinary differential equations with constant coefficients. Control inputs for tracking are determined by conditioning the prior GP on the setpoints, i.e. control as inference. The resulting Model Predictive Control scheme incorporates pointwise soft constraints by introducing virtual setpoints to the posterior Gaussian process. We show theoretically that our controller satisfies asymptotical stability for the optimal control problem by leveraging general results from Bayesian inference and demonstrate this result in a numerical example.
Gaussian Process Priors for Boundary Value Problems of Linear Partial Differential Equations
Nov 25, 2024



Solving systems of partial differential equations (PDEs) is a fundamental task in computational science, traditionally addressed by numerical solvers. Recent advancements have introduced neural operators and physics-informed neural networks (PINNs) to tackle PDEs, achieving reduced computational costs at the expense of solution quality and accuracy. Gaussian processes (GPs) have also been applied to linear PDEs, with the advantage of always yielding precise solutions. In this work, we propose Boundary Ehrenpreis-Palamodov Gaussian Processes (B-EPGPs), a novel framework for constructing GP priors that satisfy both general systems of linear PDEs with constant coefficients and linear boundary conditions. We explicitly construct GP priors for representative PDE systems with practical boundary conditions. Formal proofs of correctness are provided and empirical results demonstrating significant accuracy improvements over state-of-the-art neural operator approaches.
Visual Car Brand Classification by Implementing a Synthetic Image Dataset Creation Pipeline
Jun 03, 2024



Recent advancements in machine learning, particularly in deep learning and object detection, have significantly improved performance in various tasks, including image classification and synthesis. However, challenges persist, particularly in acquiring labeled data that accurately represents specific use cases. In this work, we propose an automatic pipeline for generating synthetic image datasets using Stable Diffusion, an image synthesis model capable of producing highly realistic images. We leverage YOLOv8 for automatic bounding box detection and quality assessment of synthesized images. Our contributions include demonstrating the feasibility of training image classifiers solely on synthetic data, automating the image generation pipeline, and describing the computational requirements for our approach. We evaluate the usability of different modes of Stable Diffusion and achieve a classification accuracy of 75%.
Future Aware Safe Active Learning of Time Varying Systems using Gaussian Processes
May 17, 2024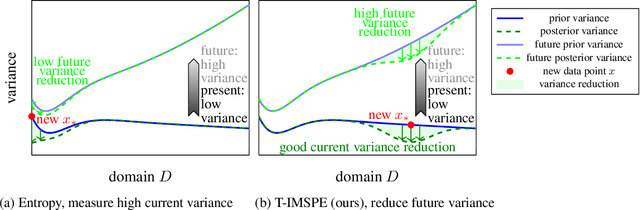

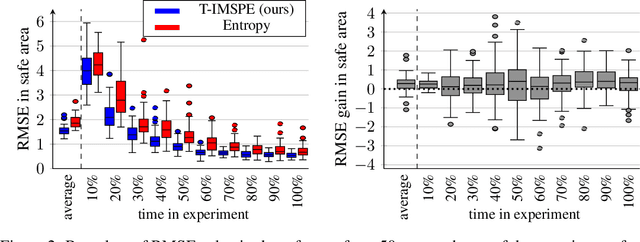
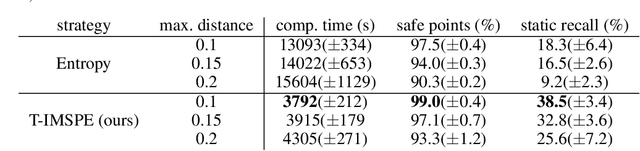
Experimental exploration of high-cost systems with safety constraints, common in engineering applications, is a challenging endeavor. Data-driven models offer a promising solution, but acquiring the requisite data remains expensive and is potentially unsafe. Safe active learning techniques prove essential, enabling the learning of high-quality models with minimal expensive data points and high safety. This paper introduces a safe active learning framework tailored for time-varying systems, addressing drift, seasonal changes, and complexities due to dynamic behavior. The proposed Time-aware Integrated Mean Squared Prediction Error (T-IMSPE) method minimizes posterior variance over current and future states, optimizing information gathering also in the time domain. Empirical results highlight T-IMSPE's advantages in model quality through toy and real-world examples. State of the art Gaussian processes are compatible with T-IMSPE. Our theoretical contributions include a clear delineation which Gaussian process kernels, domains, and weighting measures are suitable for T-IMSPE and even beyond for its non-time aware predecessor IMSPE.
PGNAA Spectral Classification of Aluminium and Copper Alloys with Machine Learning
Apr 22, 2024



In this paper, we explore the optimization of metal recycling with a focus on real-time differentiation between alloys of copper and aluminium. Spectral data, obtained through Prompt Gamma Neutron Activation Analysis (PGNAA), is utilized for classification. The study compares data from two detectors, cerium bromide (CeBr$_{3}$) and high purity germanium (HPGe), considering their energy resolution and sensitivity. We test various data generation, preprocessing, and classification methods, with Maximum Likelihood Classifier (MLC) and Conditional Variational Autoencoder (CVAE) yielding the best results. The study also highlights the impact of different detector types on classification accuracy, with CeBr$_{3}$ excelling in short measurement times and HPGe performing better in longer durations. The findings suggest the importance of selecting the appropriate detector and methodology based on specific application requirements.
On the Laplace Approximation as Model Selection Criterion for Gaussian Processes
Mar 14, 2024



Model selection aims to find the best model in terms of accuracy, interpretability or simplicity, preferably all at once. In this work, we focus on evaluating model performance of Gaussian process models, i.e. finding a metric that provides the best trade-off between all those criteria. While previous work considers metrics like the likelihood, AIC or dynamic nested sampling, they either lack performance or have significant runtime issues, which severely limits applicability. We address these challenges by introducing multiple metrics based on the Laplace approximation, where we overcome a severe inconsistency occuring during naive application of the Laplace approximation. Experiments show that our metrics are comparable in quality to the gold standard dynamic nested sampling without compromising for computational speed. Our model selection criteria allow significantly faster and high quality model selection of Gaussian process models.